





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)








































This blog was originally published Dec. 9, 2020 on humio.com. Humio is a CrowdStrike Company.
Enterprises are often deeply intrigued when they learn that Humio can reduce their log management costs by up to 80%. It’s understandable. Many companies struggle to stay within their log management budget. But it is true, thanks to the choices Humio’s founders made when building the modern log management platform. One of those choices in building a modern log management solution was an index-free architecture.
To perform search at scale, traditional log management systems index data as it’s ingested. Indexing streaming data, however, is expensive and slow, as it requires heavy processing and maintenance. For example, maintenance tasks include merging old indexes with new ones, tracking which indexes exist, and fixing corrupted indexes. Naturally, this all adds to the operational overhead of a log management solution.
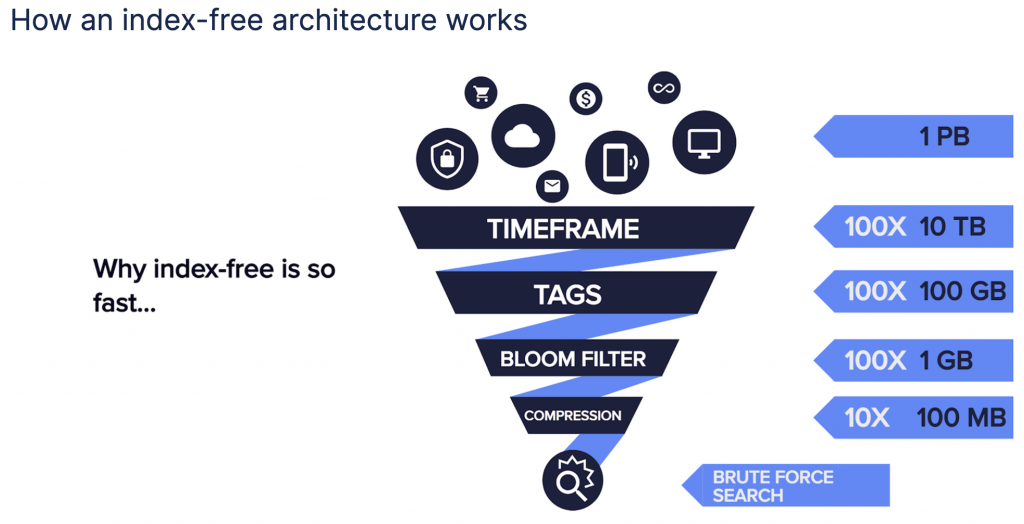 Here’s how Humio’s index-free architecture works:
Here’s how Humio’s index-free architecture works:
We previously managed a 40-node, index-based cluster with a hot, warm, cold data architecture that was costly in terms of infrastructure costs as well ongoing engineering maintenance. In our cost analysis, all index-based solutions had a steep curve in terms of costs and the Humio cost-curve remained fairly flat. We were thrilled to remove the burdens put on our engineering team, the attractive cost model and then marry that with performance increases and a fully-functional set of query functions. — Landon Lewis, CEO, PonduranceIndexing also increases storage requirements. Given the exorbitant growth of data volumes, enterprises are already sensitive to storage costs, and indexing data increases those costs. The indexes themselves can become very large. Assuming the index is used to make the entire event searchable, indexing can make the data up to 300% larger than it was in its raw form. In addition to increasing costs, indexing impacts query speeds. Often, log management platforms that use indexing for search leverage a live streaming query to power “live” views of the data. Users may see a spike in a live dashboard, but they can’t search those events in detail or view them live. Finally, an index-based solution lacks the flexibility to allow users to ask anything of their data. To avoid performance issues, queries must be based on what’s indexed, and that’s a decision that must be made before data is ingested. In many cases, organizations don’t know exactly how they’ll want to search their data and later find themselves restricted by this lack of foresight.
Humio’s index-free architecture
Humio’s founders were tired of the challenges associated with indexing data and, more importantly, they knew that there was a better way to search log data. Our founders decided to limit indexing to event timestamps and build Humio on anindex-free architecture. By eliminating the vast majority of processing and the maintenance associated with indexing, Humio significantly reduces the cost of maintaining indexes and storing that data.
We have been experiencing the benefits of Index-free log aggregation for the past couple of years with Humio, and it truly transformed the way we work with logging. — Kasper Nissen, Cloud Architect, Lunar
Here’s how Humio’s index-free architecture works:
- Log data comes in from either a log shipper or directly from the network device.
- After the data is received, it goes into an ingest node.
- The data is normalized via Humio-provided parsers or custom parsers.
- Next, we index the timestamps of the data. Because we don’t index data, searches are limited to a given timeframe.
- The information is stored in bucket storage.
- The context of the data is stored in lightweight tags that summarize where the data came from or how it is used.
- A bloom filter is applied and computed over the keys, and values of the data are stored. (A bloom filter is a data structure designed to tell you, rapidly and memory-efficiently, whether an element is present in a set. It is a space-efficient probabilistic data structure that is used to test whether an element is a member of a set. Bloom filters use hashing. A hash function takes input and outputs a unique identifier of fixed length that’s used for identification of input. Why do we use a Bloom filter? Well, it’s more flexible than a standard hash table. A Bloom filter of a fixed size can represent a set with an arbitrarily large number of elements. Adding an element never fails, and Bloom filters never generate false negatives.)
Cost Savings Estimator
to estimate your cost savings when you deploy Humio.
Additional resources
- The need to index isn’t the only misconception companies have about log management. Learn more about
how modern log management differs from traditional solutions. - Learn more about
index-free logging in this blog post
by our Founder and CTO, Kresten Thorup. - Attend our
index-free logging webinar, available on-demand. - Read more about the
benefits of index-free technology.
