





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































With the ever-increasing need for speed and accuracy for digital investigations and incident response, it is imperative that organizations are able to provide answers quickly. These organizations rely on highly skilled individuals to provide them fast answers in a crisis situation. Manually parsing evidence can take a long time when going through the repeated process of running a tool followed by analyzing the output. The manual analysis method is tedious and time consuming, especially on limited traditional hardware. Two great tools that make processing memory evidence fast and effective are “Volatility” and “bulk_extractor”. Volatility is a Python based tool that utilizes different modules to extract investigative data from a raw memory dump. The “bulk_extractor” tool is a multithreaded utility that can also extract interesting data from a memory dump. Running each of these tools with different options and modules can take a long time to get to relevant analytical data. It is much easier to script these tools and parse the output for indicators. To facilitate this I created a Linux bash script I call “vshot” that supports simulated multithreading of over 40 modules from Volatility. It also provides an option to run bulk_extractor in parallel with the Volatility modules. With the script, the number of multithreaded Volatility processes depends on the number of available cores a particular host has. If a host has 8 available cores (such as 4 cores using hyper threading), the script will use only cores 1-7 and leave core 0 to handle operating system tasks. As each volatility process finishes, the script assigns the next module in line to be executed under an available processor core. The processor core is specified using the “taskset” command with the “-c” argument. Each core’s availability is tracked and updated in an array that is checked every 0.3 seconds. This provides a significant performance gain over a script that runs one tool at a time. It also prevents the analysis host from being starved for resources when compared to scripts that attempt to run every tool at the same time. 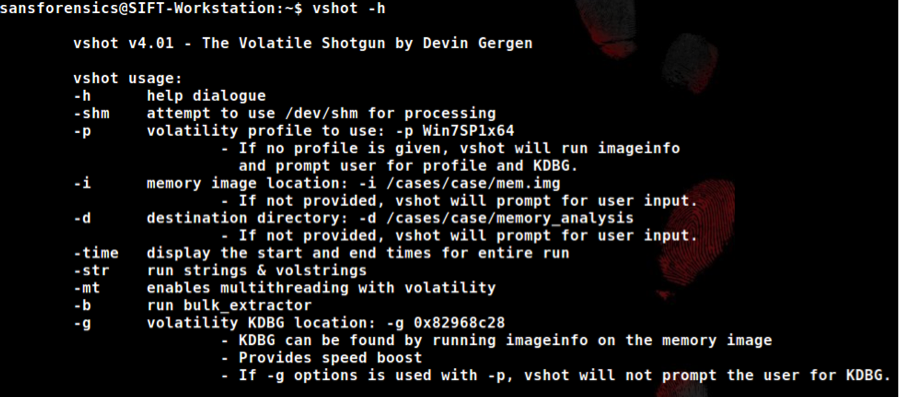 When speed is needed, hardware and device input/output goes a long way in determining how quickly investigators can access data for analysis. We have tested the script speed using the hardware outlined below.
When speed is needed, hardware and device input/output goes a long way in determining how quickly investigators can access data for analysis. We have tested the script speed using the hardware outlined below.
| Model | MacBook Pro (OS X 10.9.5) |
| Processor | Intel Core i7 at 2.3GHz |
| Number of Processors | 1 |
| Total Number of Cores | 4 |
| L2 Cache (per Core) | 256KB |
| L3 Cache | 6MB |
| Memory | 16 GB |
The testing environment we used was a virtual machine in VMware Fusion with the SIFT 2.14 Linux distribution provided by SANS. The VM is set up with 6GB of RAM and configured to utilize the available 4 cores. Below you will find statistics for processing a raw memory image hosted on the following hardware:
- 5400RPM HDD via USB3
- To simulate a budget HDD plugged into an analysis host
- SSD via USB3
- To simulate a SSD plugged into an analysis host
- Built in SATA SSD
- To simulate data directly on the analysis host
- RamDisk via tmpfs (-shm script option)
- To show the usage of RAM as a evidence processing medium
- sudo mount -t tmpfs -o size=2g tmpfs /mnt/tmpfs/
The script was run against a 1GB Windows7 SP1 memory dump from a host infected with the DarkComet malware. Using the multithreading in the script, we saw a 40-50% decrease in the time it took to process the memory image. The table below shows the number of seconds it took the script to complete processing.
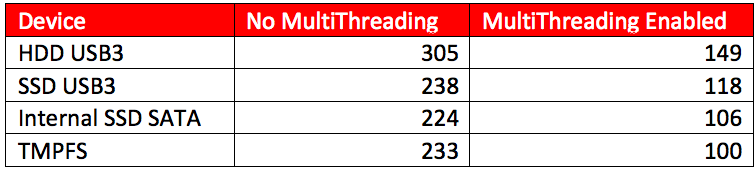 Number of Seconds to Complete Processing
Number of Seconds to Complete Processing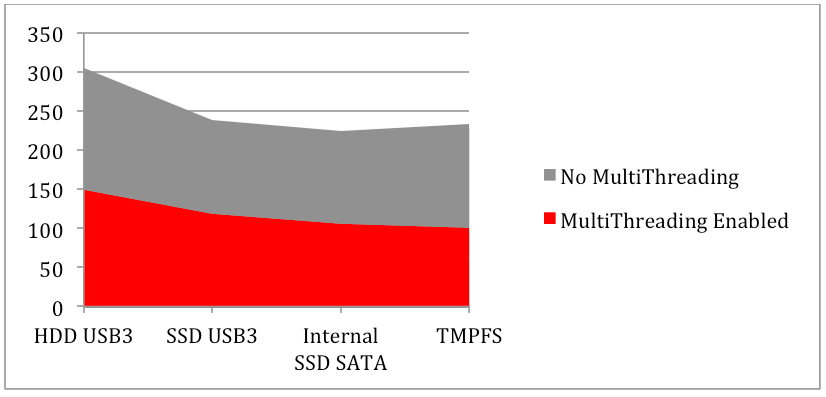 Multithreading Volatility Processing (Lower is Better!)
Multithreading Volatility Processing (Lower is Better!)Today’s business computers come with between 4 and 16 Gigabytes of memory standard. While not totally accurate, we can get a sense of scale as to what this means when it comes to processing larger evidence sizes with this script. Lets say we take the scenario above where we host the memory image on a USB3 SSD, and use that hardware to process an 8GB memory image. Using traditional processing, the image will be fully parsed in around 30 minutes. Using multithreading, we are able to trim that time down to a measly 15 minutes. Now imagine responding to an ongoing adversary campaign with evolving indicators and multiple infected hosts. For good measure, we’ll assume we have to process memory images for 10 hosts, and each host has a 8GB memory dump. By using the multithreading functionality, we save 2.5 hours of processing time, and can now use that time for analysis and other investigative tasks. Now that we’ve saved time in our data processing, we can examine the evidence created by the script. We can start with the results from a single host and use the discovered indicators to identify infection across all resulting data sets. Lets take a look at the output from the “psscan” and “dlllist” Volatility modules.
 Volatility psscan results
Volatility psscan resultsAs investigators, we notice an odd process named “runddl32.exe” running out of a users “Temp” directory. We can now use this indicator to quickly identify the possible infection across all of our hosts we have data for. The example below shows how we can use egrep to search across multiple data sets for indicators of adversary activity.
 Identifying similar infection across multiple data sets
Identifying similar infection across multiple data setsThe memory processing script “vshot” can be downloaded here. Future improvements on the vshot roadmap include the following:
- Volatility timeline support
- Profile-specific tool runs (to remove tools incompatible with specific image types and thus decrease processing time)
Memory analysis has become a staple in gathering evidence of advanced attacks in the world of digital forensics and incident response. Clues that attackers wipe away from disk can now easily be recovered in memory. Using efficient data processing methods and large-scale analysis, responders can rapidly identify anomalies and respond to adversary infection.