AI-Powered Classifications for Unstructured Cloud Data

How Falcon Data Protection for Cloud combines language models and rules to reduce noise and improve coverage
Sensitive data isn’t only in neat spreadsheets. It’s buried in messy, unstructured data across documents, chat logs, support tickets, wikis, and free-text fields across your environment. As generative AI adoption accelerates, this challenge accelerates. Sensitive data now flows through conversational contexts, and this is where traditional data classification falls short.
CrowdStrike takes a different approach by combining a purpose-built language model with deterministic rules to improve coverage without sacrificing explainability.
Unstructured data demands context and meaning, which rule-based systems fundamentally cannot understand on their own. It requires AI that can comprehend language semantically, not just match patterns.
CrowdStrike’s approach makes a purpose-built language model a core component of data classification, while preserving rules as a complementary layer. The two work together: the language model brings contextual understanding that no regex could capture, while rules provide deterministic validation for patterns that must stay explainable.
AI-powered classification expands coverage for unstructured data, reduces false positives, and cuts tuning overhead. The hybrid approach maintains explainability where it matters most.
But understanding context is only valuable if you can deploy it at scale. Through techniques like knowledge distillation and quantization, we’ve engineered our model to run efficiently in resource-constrained environments, delivering accurate data classification that drives action across the entire Falcon platform.
The Problem with Traditional Rule-Based Engines
Traditional rule-based systems rely on regular expressions and keyword lists, excelling at identifying structured patterns like credit card numbers and Social Security numbers. While they can incorporate contextual clues through predefined keywords (e.g., “password”), they’re limited to explicitly anticipated terms and sentence structures.
Consider this text:
“you can use jmitchell_2024 to access my account, and the phrase we set up yesterday was TempPass@789!”
This is clearly a credential being shared in natural language. While rule-based systems might catch some variations, they’d need extensive rules to cover phrases like “the phrase we set up”, “the code is”, and countless other ways people naturally share sensitive information. Adding these extensive rules also opens the door to false detections as legitimate business communications get flagged as threats.
| The fundamental limitation is simple. Rules match predefined patterns. They do not understand semantic meaning or interpret natural language, which is where unstructured sensitive data lives. |
This creates an unsustainable tradeoff: Security teams either cast a wide net and drown in false positives, spending hours investigating benign matches, or tighten rules to reduce noise and allow critical exposures to slip through undetected.
No matter the approach, the organization is left with compliance gaps, missed sensitive data, and burned-out analysts chasing endless tuning projects.
How Language Models Change the Game
Unlike rules, which match predefined patterns, language models understand meaning and intent. When a language model reads “you can use jmitchell_2024 to access my account” it doesn’t just see a string of characters; it comprehends that someone is sharing access credentials by understanding the semantic relationship between account access, the username format, and the conversational intent.
This capability comes from training at scale. Language models learn how language actually works, including syntax, semantics, and how meaning shifts based on context. They recognize document types and adapt interpretation accordingly. A chat message is read differently than meeting notes or a scientific article. Through exposure, they also acquire domain knowledge, from what constitutes a credential to how medical terminology and PII appear in real-world text. Most importantly, this understanding generalizes beyond fixed patterns or predefined phrases.
The model can identify a medication it has never encountered during training by interpreting the surrounding medical context such as dosage references, symptom descriptions, and prescription language.
The model produces a confidence score with every classification, quantifying detection certainty. Today, these scores are integrated behind the scenes as part of the hybrid approach to help ensure reliable results.
To see the difference in action, let’s compare how rule-based and AI-powered systems classify the same data.
What This Looks Like in Practice
PII in a Registration Form
The following registration form for companies contains various sensitive data types. This is the result of scanning the file with the rule-based system:

The rule-based system struggles with real-world data complexity:
- “Meridian” in the company name “Meridian Solutions Inc.” is incorrectly classified as a city. The rules match it to a known city in Mississippi without understanding it’s part of a business name.
- The address “Northern Building Complex, Manufacturing District, Portland, Oregon” is fragmented into separate, disconnected classifications. The system expects addresses in specific formats and cannot recognize this as one cohesive entity.
An AI-powered scan of the same file produces different results:
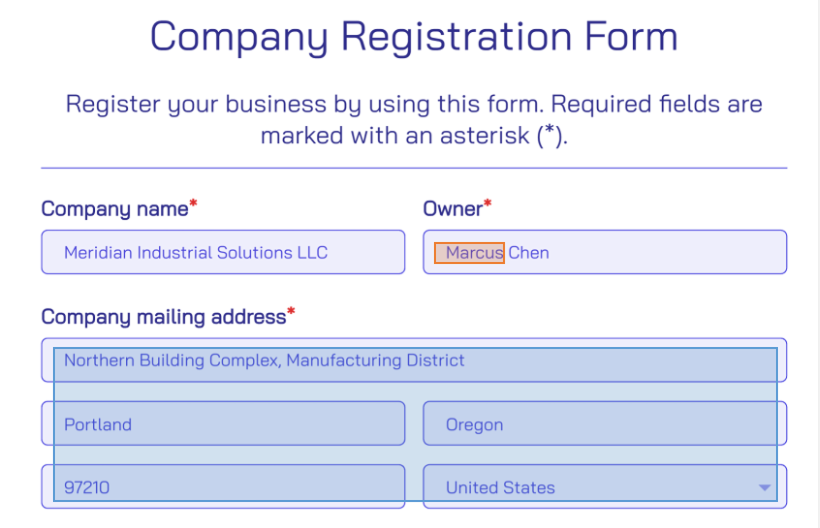
The model demonstrates contextual intelligence, correctly interpreting what the data represents despite formatting variations.
Next, we’ll apply the same comparison to clinical language, where dictionary-based approaches routinely fall short.
Data Classifications in Medical Records
A medical report contains various patient information including diagnoses, medications, and treatment notes. A rule-based scan using medical term dictionaries identified 6 out of 9 medical classifications (and another partial term) in the document:
1. Detailed (Chronological) Analysis:
Patient Sarah Mitchell is a 37y/o female who presented to the St. Mary’s Medical Center at 0236 for evaluation and treatment of posterior neck pain that radiates to the right shoulder for the past three months. She describes being under chiropractic care and possibly medical care for this neck pain. She has taken ibuprofen without resolution.
No pain management was provided in the emergency room and the patient describes her pain as having improved from a 10/10 to a 7/10.
Emergency department documentation demonstrates that Dr. Jennifer Patel wrote a discharge order for Ms Mitchell at 0302. Her diagnosis at the time of discharge was cervical strain with radiculopathy.
While the emergency physician chart documents that the patient received Percocet at the time of discharge, the patient was provided discharge prescriptions for Flexeril and Penicillin VK. Ms. Mitchell was also provided instructions to take Tylenol or Motrin as needed.

The rule-based system missed “cervical strain with radiculopathy” entirely. This compound medical condition doesn’t exist in predefined dictionaries, and “strain” alone is too ambiguous to match reliably. This isn’t an edge case. Dictionary-based approaches systematically fail with the complexity of real medical language.
The AI-powered scan detected all medical classifications:
1. Detailed (Chronological) Analysis:
Patient Sarah Mitchell is a 37y/o female who presented to the St. Mary’s Medical Center at 0236 for evaluation and treatment of posterior neck pain that radiates to the right shoulder for the past three months. She describes being under chiropractic care and possibly medical care for this neck pain. She has taken ibuprofen without resolution.
No pain management was provided in the emergency room and the patient describes her pain as having improved from a 10/10 to a 7/10.
Emergency department documentation dem onstrates that Dr. Jennifer Patel wrote a discharge order for Ms Mitchell at 0302. Her diagnosis at the time of discharge was cervical strain with radiculopathy.
While the emergency physician chart documents that the patient received Percocet at the time of discharge, the patient was provided discharge prescriptions for Flexeril and Penicillin VK. Ms. Mitchell was also provided instructions to take Tylenol or Motrin as needed.
The language model’s training on medical literature enables it to recognize complex, contextual medical relationships that static dictionaries cannot capture. It understands how medical terms combine, how context determines meaning, and how to interpret domain-specific language without requiring every possible phrase to be predefined.
Impact and Evolution
AI-powered classification brings measurable improvements across the dimensions that matter most:
- Better coverage for unstructured data: contextual understanding captures sensitive information that pattern matching simply cannot see.
- Fewer false positives: semantic comprehension reduces alert noise and investigation overhead.
- Reduced tuning burden: the model generalizes across language variations, eliminating the endless cycle of rule refinement.
- Platform consistency: the same classification engine works across cloud and endpoint to deliver unified data protection.
The hybrid approach expands coverage without sacrificing trust. Rule-based classifications continue to provide the deterministic, auditable results compliance teams rely on, including precise checksum validation that language models cannot reliably replicate. The language model adds contextual detections that rules fundamentally cannot make.
Built to Scale Everywhere
Language models are powerful, but they are often constrained by the computational resources they require. CrowdStrike engineered AI-powered classification to operate efficiently through techniques such as knowledge distillation and quantization, compressing the model while preserving its ability to understand context and meaning. The model is designed to run on accelerated AI hardware, enabling high-performance classification on local resources while scanning cloud storage without sending data externally. This is how CrowdStrike turns AI-powered classification into a platform capability, not a standalone feature.
This architecture was not built for the cloud alone. The same efficiency that enables scalable cloud classification also makes it possible to bring this intelligence directly to the endpoint. As announced at Fal.Con 2025, and enhanced through a partnership with Intel, CrowdStrike is extending AI-powered classification to endpoint data protection in 2026. This is not a standalone capability. It is unified data protection evolving across the Falcon platform, with consistent classification intelligence applied from cloud to endpoint. A deeper technical exploration of how language model inference is engineered for endpoint deployment will be shared in a future post.
Additional Resources
- Visit the Falcon Data Protection for Cloud webpage to learn more.
- Schedule a demo to see Falcon Data Protection in action.


