





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































This blog was originally published Nov. 8, 2021 on humio.com. Humio is a CrowdStrike Company.
In 2021, Humio and Crowdstrike joined forces to deliver a truly robust security solution. CrowdStrike delivers the industry’s most comprehensive security solution for protecting endpoints and workloads, processing 1 trillion security-related events per day with its pioneering Threat Graph™ technology. By combining this with Humio’s best-in-class log management and streaming observability, customers get deep, contextual, index-free analytics at speed and scale.What is the Falcon Data Replicator?
The Falcon Data Replicator (FDR) gives organizations a way to pull their raw event data from the Threat Graph (aka the Falcon Platform). Once the data is pulled, customers can ingest, transform and analyze it. Most organizations will ingest the data into their own data warehouse, perform custom analytics and investigations, and define an event retention policy based on the storage available. Below is a high-level overview of the Falcon Data Replicator data flow. In essence, endpoints generate raw event data which is ingested into Threat Graph. Falcon Data Replicator places the raw event data into a AWS S3 bucket and enables users to bring that data into Humio.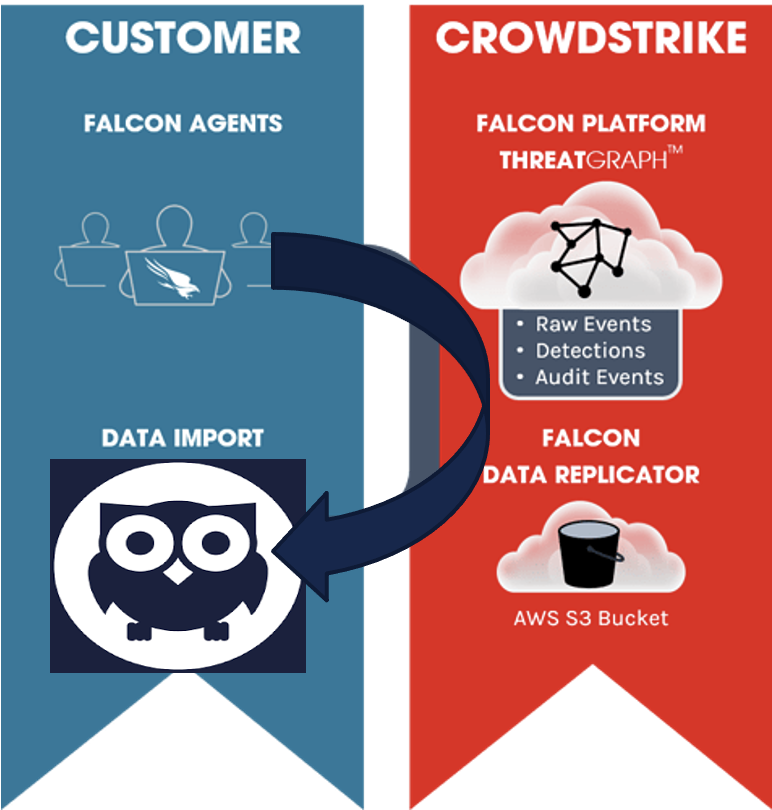
Who can benefit from Falcon Data Replicator and Humio?
The Falcon Data Replicator is most used by teams who have data warehousing capabilities, in-house analytics tools and a need to retain raw event data beyond their “Falcon Platform” retention period. Humio is the perfect solution for hosting this type of data due to its powerful searching and analysis capabilities. Humio is a modernlog management
solution, purpose-built for handling valuable data such as Falcon data. Humio is built on an index-free architecture that enables data streaming at scale. This modern architecture, combined with high compression on storage, gives teams the ability to ask anything and get instant responses, specifically around activities such as threat hunting.
How customers benefit
Correlation with other log sources
By ingesting the Falcon data into Humio, it instantly becomes searchable alongside all existing Humio data. Customers can now create correlation searches across Falcon data and other datasets to get new insights and a clearer understanding and an end-to-end view of their environment. By having security detections use analysis of multiple log sources, customers are able to better define and narrow the scope of detections to match exact adversary techniques and behaviors, resulting in fewer false positives. Detections and findings from one log source can be used to trigger associated searches across other logs sources — enabling proactive threat hunting and investigations to pivot across the entire environment seamlessly.Longer data retention
With Humio’s cost-effective bucket storage and industry-leading compression levels, customers can keep their data in Humio for longer. This applies to all data, including from the new Falcon integrations. This ensures that long-term trending and baselining of activities and behaviour is possible and means that investigations have access to the logs they need, even from months ago. Humio gives customers confidence in the completeness and accuracy of investigations, which allows focused and therefore cheaper and faster remediation.Fast and custom search
Humio’s feature-rich query language and super fast search times allow customers to ask any questions of their data and get immediate answers. Customers can create complex searches, using regular expressions and multiple joins, to craft very specific searches that meet their exact business requirements and generate new insights from the data.How to get started
Contact support
To start, contact CrowdStrike support. The support team will create a CrowdStrike managed Amazon Web Services (AWS) S3 bucket for short-term storage purposes as well as a SQS (simple queue service) account for monitoring changes to the S3 bucket. By default, this S3 bucket has a seven-day retention policy because data is intended to be pulled out of it for longer-term retention. However, with Humio, we take this a step further with the ability to store your data for as long as you need. To learn more about FDR licensing, reach out to your account manager.Pull & process event data
Once the raw event data is flowing, you are working with Humio to pull the data from the S3 bucket. The simple queue service (SQS) simplifies this process by publishing any file changes to the S3 bucket. Humio leverages the processes described below to ingest the data at scale.Enable Falcon Data Replicator
Before enabling the Falcon Data Replicator, be sure to review the technical support feature guide to gain a full understanding of the requirements. Then, work with CrowdStrike support as mentioned above to enable the Falcon Data Replicator for your organization.Bring your data into Humio
Once Falcon Data replicator is enabled, the next step is to deploy the FDR2Humio tool, which is available at https://github.com/humio/fdr2humio. Alternatively, Crowdstrike can also host this process depending on customer requirements. The fdr2humio tool is available as a python script (fdr2humio.py) or as a docker container (fdr2humio) hosted in GitHub. We recommend using the docker container where possible. The first step for either option is to gather the required inputs for use with FDR2Humio. From the Falcon console, go to “Support,” then “API Clients and Keys” and set up the credentials for Falcon Data Replicator (this is an additional component of Falcon that you need to subscribe to). The inputs for the FDR side of the integration are:- SQS Queue URL (e.g. https://sqs.us-west-3.amazonaws.com/1234567890/your-fdr-ident-12345-1234567890)
- S3 Bucket (e.g. s3://your-fdr-ident-12345-1234567890/data)
- AWS Access ID and Key (the key will only be shown to you once during setup)
- The URL of your Humio server (e.g. https://cloud.humio.com/)
- The Ingest API token from your repository (e.g., 11111111-2222-aaaa-bbbb-333333333333)
How the integration works
Humio has a package for FDR which provides some quick-start content for use with data collected from the Falcon Data Replicator service.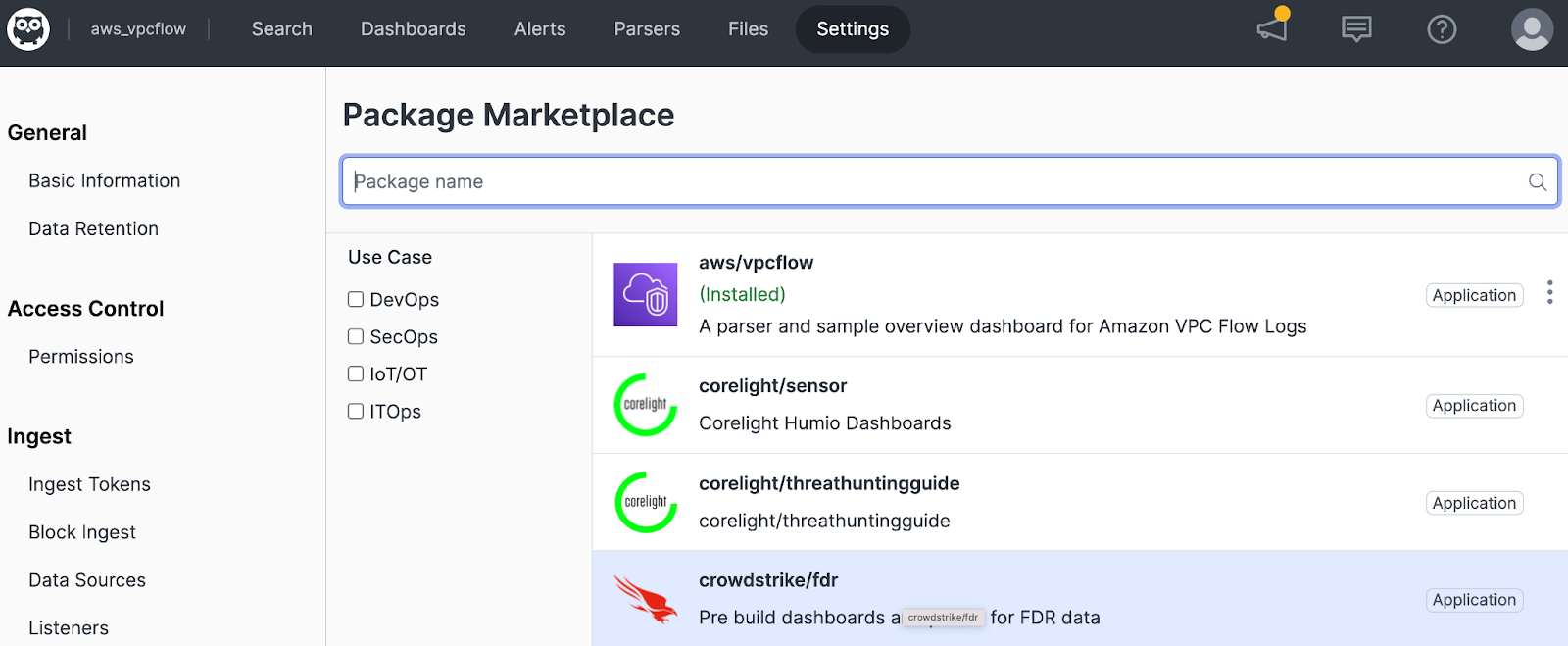 This package can be deployed directly from Humio.
This package can be deployed directly from Humio.
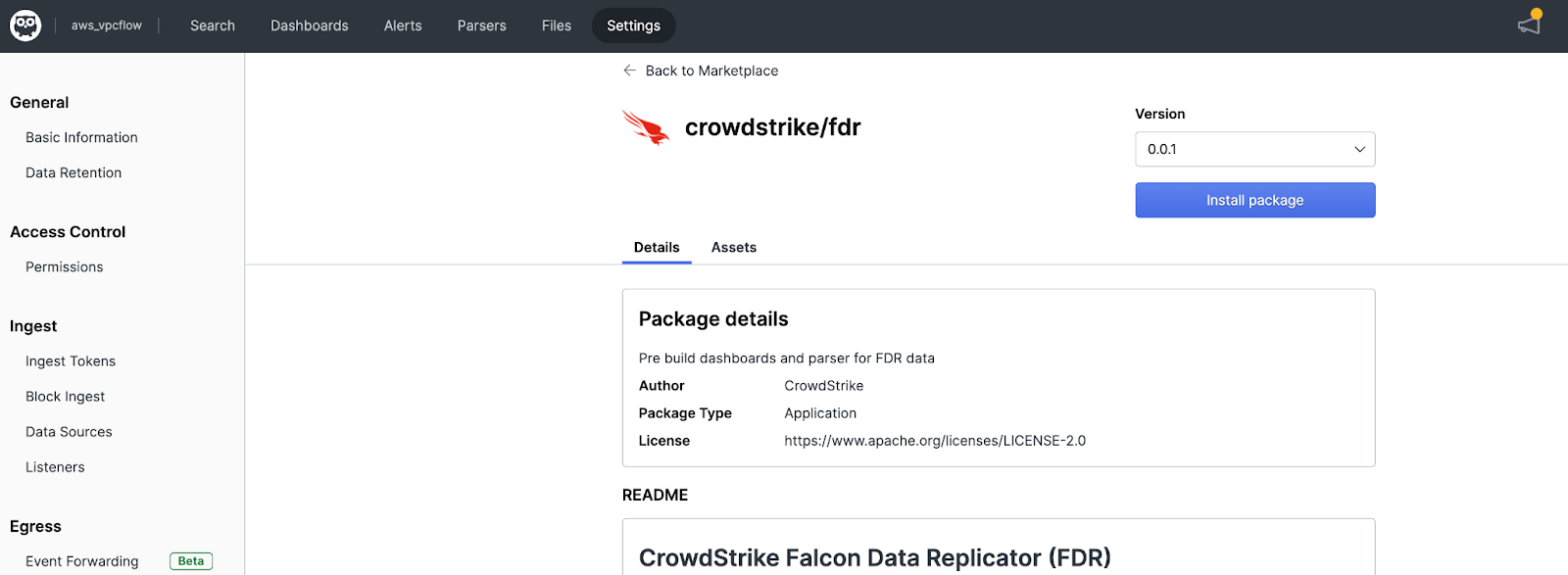 The package includes:
The package includes:
- Parser
- Dashboards
- Saved queries
Parser
While the events from FDR are structured (JSON,) it is necessary to use this parser to ensure that event timestamps are correctly processed and that the event name and cid fields are created as tags.Dashboards
There are a selection of dashboards for getting quick value from your FDR data. These should serve as the basis of building use cases, specific FDR dashboards, alerts and queries. The dashboards the package contains include:- Detections over time. Visualizes detections over time, mapping of files and detections by severity, technique and tactic.
- Domain search. Shows the relationship between processes and domains and domain lookups by host.
- Hash search. Shows file executions and file writes and gives the ability to search for hashes.
- IP search. Shows the relationship between processes and IP addresses and gives the ability to search across IP addresses.
 Example visualization showing detections by severity, technique and tactic:
Example visualization showing detections by severity, technique and tactic:
 Mapping of MITRE ATT&CK Techniques to severity and mapping MITRE ATT&CK tactics to techniques:
Mapping of MITRE ATT&CK Techniques to severity and mapping MITRE ATT&CK tactics to techniques:

Alerts and saved queries
The package also provides alerts and saved queries. These are updated regularly and either provide specific detections (e.g., PrintNightmare) or more general use cases (e.g., Failed Logons).How to try out sample FDR data
Sign up for Humio Community Edition, the largest no-cost log management solution available. Community Edition is a quick and easy way to get streaming observability and to try using your FDR data with Humio. Ingest up 16GB of data per day with seven-day retention. Access Humio Community Edition at no cost today.Additional resources
- On-demand Fal.Con presentation: Extending Falcon’s Memory: Threat Hunting in Humio
- Connect with peers in log management & observability at
The Nest
