





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































Over the past three months, CrowdStrike worked closely with VirusTotal (VT), and we are excited to announce the integration of our anti-malware technology as an additional scanner available to the VT community. CrowdStrike customers have enjoyed protection using this engine as one of many technologies integrated into Falcon Host for a while, but now it is available to any user of VirusTotal. If you have a Windows executable or DLL you are unsure about, you can now head over to VT and submit it to get scan results from over 50 anti-malware scanners, including ours. The results that our scanner returns are a bit different from what you will see from other engines. That is because CrowdStrike’s scanner is the first fully machine learning-based engine in VirusTotal. We’ll get into what that means in a bit, but let’s first see what this means for you as the user. Most importantly, if we detect a file, we return a confidence score -- there is no coarse yes/no decision as with traditional signature-based AV. Presently, the score ranges from 60 to 100. The higher the score, the more certain we are that the file is indeed malware. In Falcon Host, our users can pick their own thresholds for both blocking and detecting malware.  Next, because there are no signatures involved, we do very well on unknown and new malware that is seen for the first time on VT. This is also evidenced by the cadence of our updates -- you will likely see that the last update of our scanner is significantly longer ago than for other engines (which typically update daily). That is because it takes a lot longer for a machine learning-based classifier to get “stale” -- or as we in the machine learning world say: the classifier generalizes, i.e. it captures well what makes something malware as opposed to just learning a bunch of telltale traits of malware, and doesn’t depend on frequent signature “touch-ups.” Think about it this way: it’s the same difference when taking a multiple-choice test and actually understanding the subject as opposed to memorizing a bunch of answers. So how does the technology work and how does it differ from what you have seen on VT so far? Traditional AV engines look for signatures or heuristics, i.e. sequences of specific bytes in the file. A malware author can easily change those detected sequences or add obfuscation layers. In contrast, using machine learning, we look at the broader picture and extract so-called “features” from the files analyzed. These are high-level characteristics that numerically describe the structure of the file. For example, we look at the amount of randomness in various areas of the file. There is a lot of structure in executable files that we can describe and analyze in this fashion. The image below shows a visual representation of the contents of an example malware file to illustrate this; note the various blocks with different shadings.
Next, because there are no signatures involved, we do very well on unknown and new malware that is seen for the first time on VT. This is also evidenced by the cadence of our updates -- you will likely see that the last update of our scanner is significantly longer ago than for other engines (which typically update daily). That is because it takes a lot longer for a machine learning-based classifier to get “stale” -- or as we in the machine learning world say: the classifier generalizes, i.e. it captures well what makes something malware as opposed to just learning a bunch of telltale traits of malware, and doesn’t depend on frequent signature “touch-ups.” Think about it this way: it’s the same difference when taking a multiple-choice test and actually understanding the subject as opposed to memorizing a bunch of answers. So how does the technology work and how does it differ from what you have seen on VT so far? Traditional AV engines look for signatures or heuristics, i.e. sequences of specific bytes in the file. A malware author can easily change those detected sequences or add obfuscation layers. In contrast, using machine learning, we look at the broader picture and extract so-called “features” from the files analyzed. These are high-level characteristics that numerically describe the structure of the file. For example, we look at the amount of randomness in various areas of the file. There is a lot of structure in executable files that we can describe and analyze in this fashion. The image below shows a visual representation of the contents of an example malware file to illustrate this; note the various blocks with different shadings.  There is a lot more data than just the amount of randomness that can be extracted for analysis. Another example are resources embedded in the file. Resources can include images, icons, user interface templates, string tables -- in other words, lots of data to analyze. As a last example, there’s also the actual code in the file, which we dissect and describe in a numerical fashion that can be fed into our machine learning classifier. We extract millions of these numerical values (and about a couple thousand of those are most relevant for the engine to render its verdict). You can think of these numbers as an address for a location in a high-dimensional space similar to GPS coordinates. There are certain neighborhoods that are good (legitimate applications) while others are bad (malware). How and why this works is explained in a lot more detail in our Machine Learning Demystified CrowdCast. A quick summary: take a look at the figure from the CrowdCast below. The data shown comes from a US Army study taking some 100 different measurements (such as height, weight, or width of hands). The study surveyed over 4000 soldiers, and data is reported by gender. In the figure below, two measurements are plotted against each other for female (red) and male (blue) soldiers. As you can imagine, just based on two measurements and the chart below, you can likely make a good guess towards the gender -- that’s how machine learning (in this case “supervised” ML) works in a nutshell.
There is a lot more data than just the amount of randomness that can be extracted for analysis. Another example are resources embedded in the file. Resources can include images, icons, user interface templates, string tables -- in other words, lots of data to analyze. As a last example, there’s also the actual code in the file, which we dissect and describe in a numerical fashion that can be fed into our machine learning classifier. We extract millions of these numerical values (and about a couple thousand of those are most relevant for the engine to render its verdict). You can think of these numbers as an address for a location in a high-dimensional space similar to GPS coordinates. There are certain neighborhoods that are good (legitimate applications) while others are bad (malware). How and why this works is explained in a lot more detail in our Machine Learning Demystified CrowdCast. A quick summary: take a look at the figure from the CrowdCast below. The data shown comes from a US Army study taking some 100 different measurements (such as height, weight, or width of hands). The study surveyed over 4000 soldiers, and data is reported by gender. In the figure below, two measurements are plotted against each other for female (red) and male (blue) soldiers. As you can imagine, just based on two measurements and the chart below, you can likely make a good guess towards the gender -- that’s how machine learning (in this case “supervised” ML) works in a nutshell. 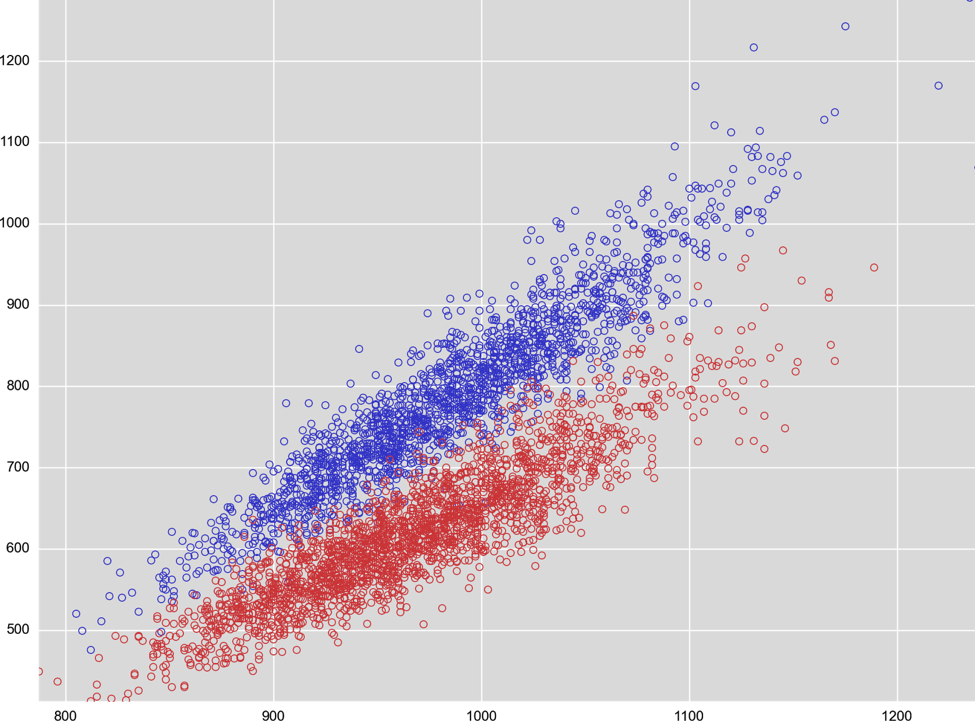 We can take the same approach with executable files and measurements we take from those files. As an example, see how that looks for two arbitrary measurements, black crosses for malware and green circles for legitimate software. The two measurements shown here are based on characteristics of string data extracted from the binary and based on size information extracted from executable sections (parts of the files that contain code).
We can take the same approach with executable files and measurements we take from those files. As an example, see how that looks for two arbitrary measurements, black crosses for malware and green circles for legitimate software. The two measurements shown here are based on characteristics of string data extracted from the binary and based on size information extracted from executable sections (parts of the files that contain code). 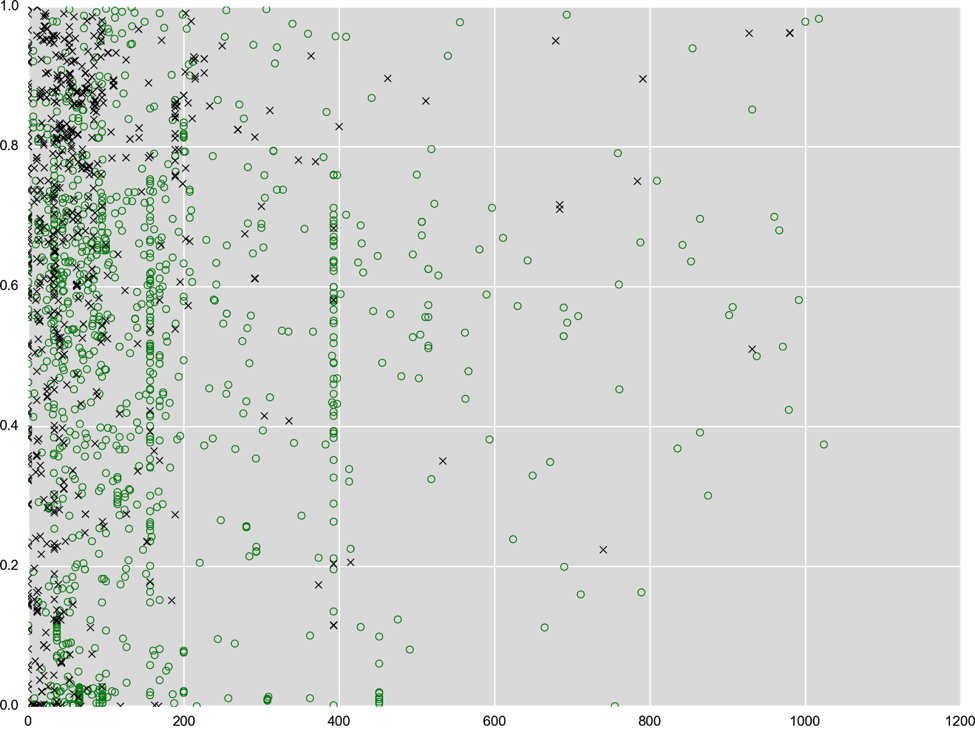 Note that this problem is a lot harder than the measurements in the Army data above -- that’s why we need to take very many measurements for a clear picture to emerge. There are no two single measurements that produce a nice separation as we saw before, but we can combine several measurements to create new ones. You can see that in the figure below; for both the x and y axis we combined a few hundred measurements. Now the green and black dots are starting to move apart.
Note that this problem is a lot harder than the measurements in the Army data above -- that’s why we need to take very many measurements for a clear picture to emerge. There are no two single measurements that produce a nice separation as we saw before, but we can combine several measurements to create new ones. You can see that in the figure below; for both the x and y axis we combined a few hundred measurements. Now the green and black dots are starting to move apart. 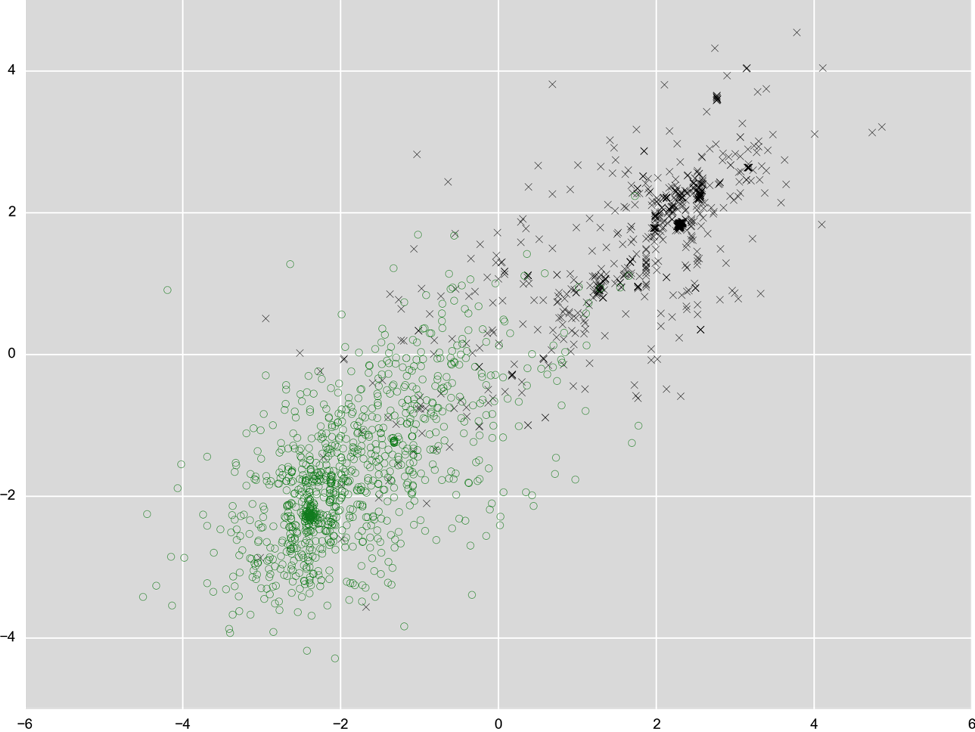 Like all other engines presently in VT, this engine looks at a file “statically,” i.e. it does not execute it and take the actual behavior into consideration. In Falcon Host, we use this engine as a first line of pre-execution defense before powerful behavioral techniques kick in that look for Indicators of Attack (IoAs). That is critically important because while detecting 99% of malware helps to keep the damage low from commodity threats, it is not sufficient to keep persistent and sophisticated national state or criminal adversaries
Like all other engines presently in VT, this engine looks at a file “statically,” i.e. it does not execute it and take the actual behavior into consideration. In Falcon Host, we use this engine as a first line of pre-execution defense before powerful behavioral techniques kick in that look for Indicators of Attack (IoAs). That is critically important because while detecting 99% of malware helps to keep the damage low from commodity threats, it is not sufficient to keep persistent and sophisticated national state or criminal adversaries
out of your network. First, more than half of their attacks are not file based. Second, even for the file based ones, a persistent threat actor just needs to be able to execute a single file in your environment. Let’s assume a state-sponsored actor is creating 1,000 completely different files and tries to get them into your environment. Your AV stops 99% of these files -- what is the chance that at least one file makes it through? It’s virtually a 100% chance of success for the attacker. See in the chart below how the probability builds up as the attacker conducts more and more attempts. 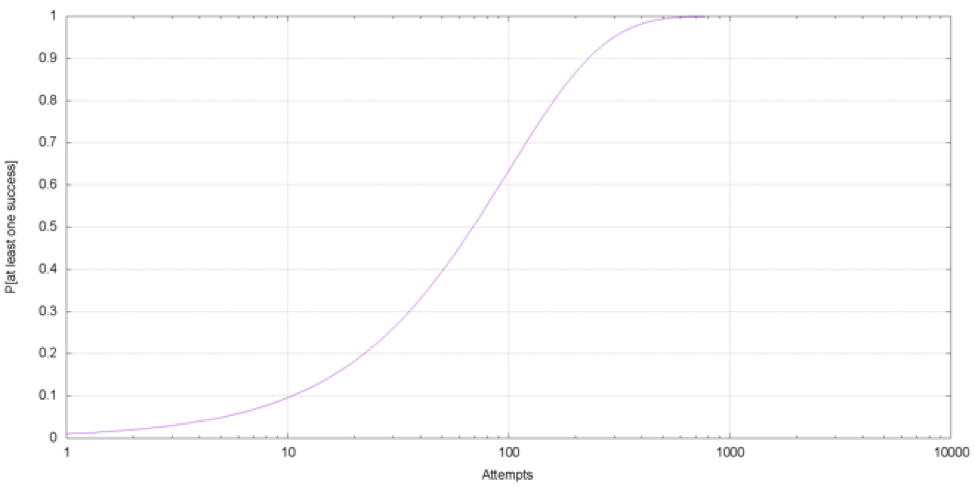 This is of course a very simplified model to illustrate the problem -- but it is intuitive for the same reasons no one would fly with an airline that has a only 99% chance of making it to the destination. We hope you are as excited as us here at CrowdStrike, and we hope you will put our machine learning technology to good use. We are also hoping to blaze the way for more next-generation endpoint security vendors to publicly and transparently share their result to build a stronger security community. Machine learning is no panacea, but it is a very powerful tool able to solve the types of problems outline above. Stay tuned for more!
This is of course a very simplified model to illustrate the problem -- but it is intuitive for the same reasons no one would fly with an airline that has a only 99% chance of making it to the destination. We hope you are as excited as us here at CrowdStrike, and we hope you will put our machine learning technology to good use. We are also hoping to blaze the way for more next-generation endpoint security vendors to publicly and transparently share their result to build a stronger security community. Machine learning is no panacea, but it is a very powerful tool able to solve the types of problems outline above. Stay tuned for more!
Open and transparent contributions to the security community are a key part of our DNA as a company. Those won’t be effective unless we receive and heed feedback from the front lines. If you see an area for improvement or a false positive, or anything you think we can do better, please send us your feedback. We are continually improving our engine and your ideas and thoughts will be critical in helping our quest to advance the security community together. Contact us at VTScanner@crowdstrike.com.


