





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































In a previous blog post, Building on the Shoulders of Giants: Combining TensorFlow and Rust, we laid out our approach of performing hyperparameter tuning and experimenting with known deep learning frameworks (e.g., TensorFlow, PyTorch, Caffe), while reimplementing the optimal versions of these models in a low-level language, to speed up the prediction process. However, an equally important part that we didn’t touch upon in that post is the development cost of taking a TensorFlow model and porting it into Rust.
Scalability is one of CrowdStrike’s focuses, and the need for an automation mechanism that achieves it emerged. In this blog post, we dig deeper, presenting this novel generic conversion mechanism that can successfully convert a TensorFlow model into pure Rust code in no time, offering the exact benefits that were highlighted in our previous blog. Notable technical challenges are also discussed.
Note: Despite the speed boost offered by GPUs when predicting using large batches of samples, they do not fit our workflow that deals with one-off predictions. Consequently, this makes TensorFlow usage for inference even less appealing for production purposes (on top of other potential issues: large dependency chain, memory consumption, etc).
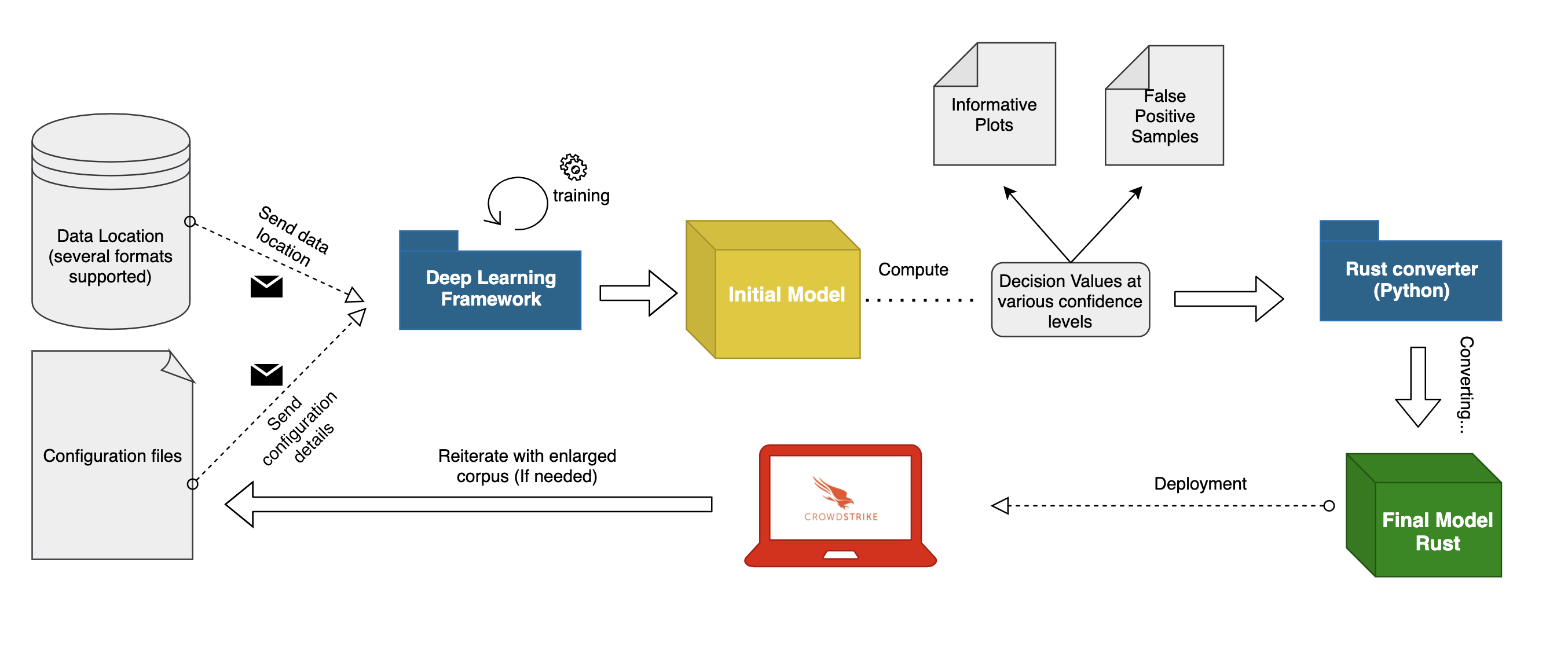 Figure 1. General training workflow (Click to enlarge)
Figure 1. General training workflow (Click to enlarge)
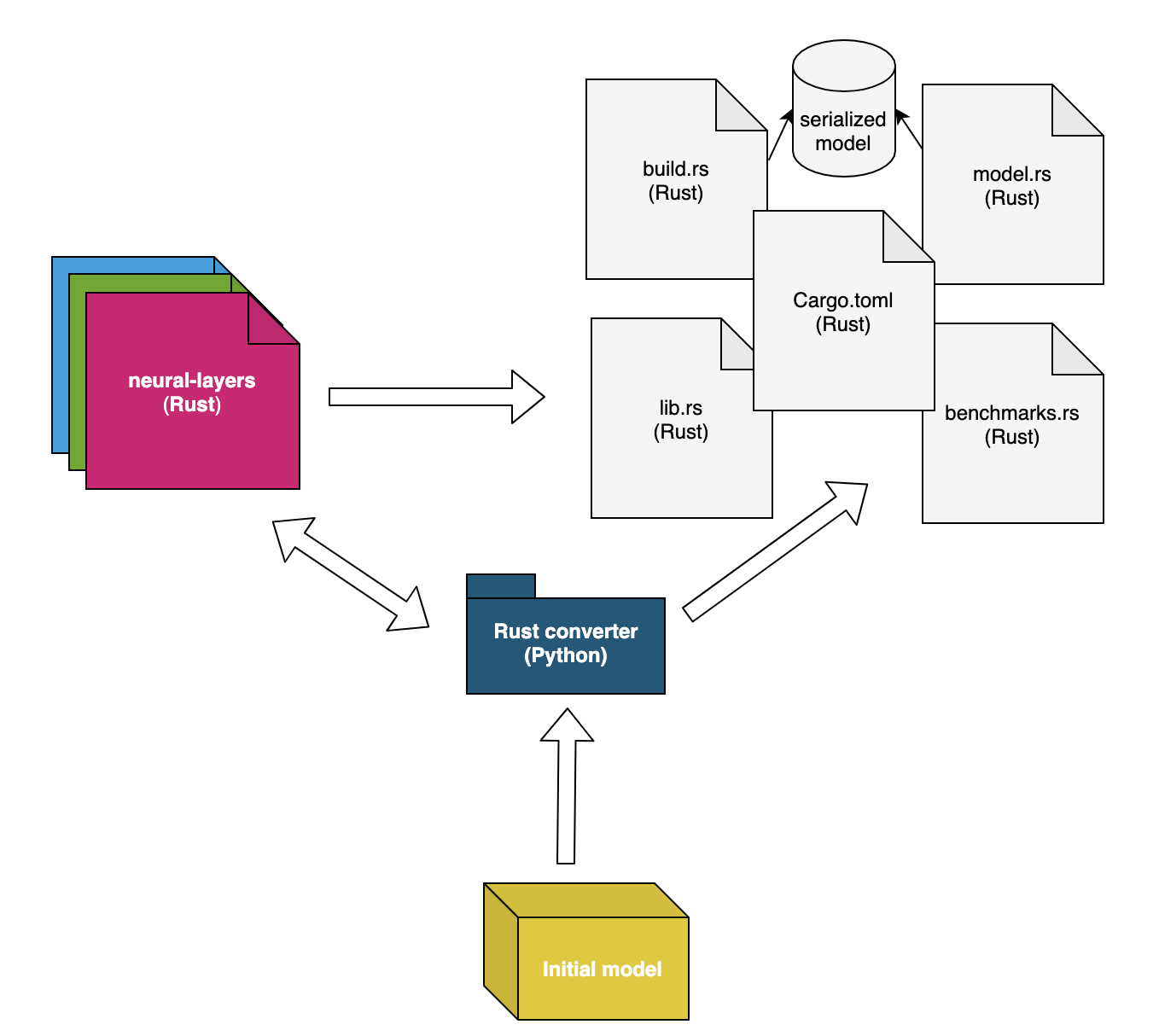 Figure 2. Conversion mechanism (Click to enlarge)
Figure 2. Conversion mechanism (Click to enlarge)
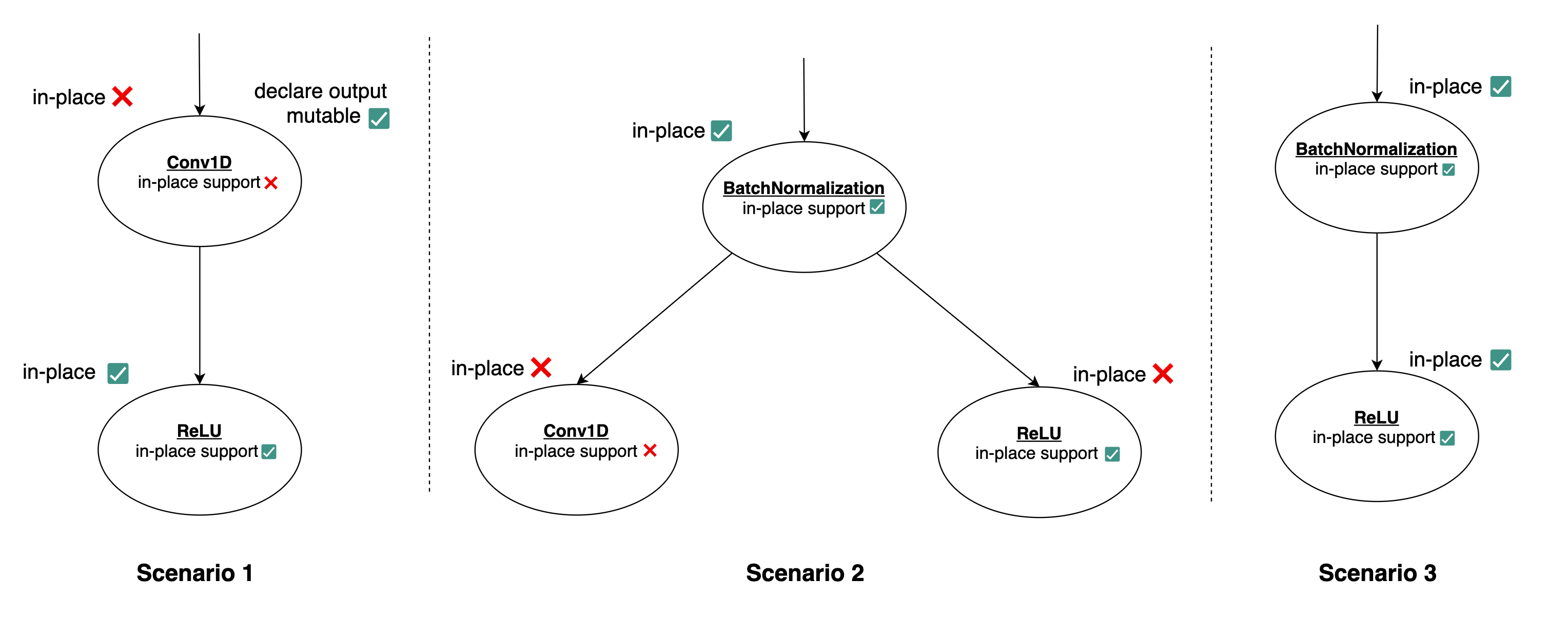 Figure 3. Possible scenarios (Click to enlarge)
Afterward, for each remaining layer there is an extraction step where all of the descriptive hyperparameters are saved (e.g., for a convolutional layer: the kernel, stride and padding type; for a batch normalization layer: gamma, beta, moving mean/variance; for activations: type, etc.). Since memory is usually critical for our target devices (smartphones, tablets, laptops), it was paramount to limit its usage as much as possible. Nevertheless, the main challenge was automating the generation of the Rust code with both in-place operations (from Rust’s perspective) and the deallocation of intermediate tensors once they’re no longer needed, instead of waiting until the end of the function to do it.
To accomplish this, multiple scenarios were covered (see Figure 3). Without going into redundant detail about each of them, it is important to note that even though a layer has in-place capability, it is not always possible to make use of it. For example, even though the ReLU layer has in-place capability, this feature cannot be empowered since its input is passed to
Figure 3. Possible scenarios (Click to enlarge)
Afterward, for each remaining layer there is an extraction step where all of the descriptive hyperparameters are saved (e.g., for a convolutional layer: the kernel, stride and padding type; for a batch normalization layer: gamma, beta, moving mean/variance; for activations: type, etc.). Since memory is usually critical for our target devices (smartphones, tablets, laptops), it was paramount to limit its usage as much as possible. Nevertheless, the main challenge was automating the generation of the Rust code with both in-place operations (from Rust’s perspective) and the deallocation of intermediate tensors once they’re no longer needed, instead of waiting until the end of the function to do it.
To accomplish this, multiple scenarios were covered (see Figure 3). Without going into redundant detail about each of them, it is important to note that even though a layer has in-place capability, it is not always possible to make use of it. For example, even though the ReLU layer has in-place capability, this feature cannot be empowered since its input is passed to The full process happens almost instantaneously, without need for external interventions. It underlines how the said conversion mechanism can be used to redesign a neural model to a more suitable form for a production environment, optimizing further the time and space needed for inference, and using constantly amortized costs to achieve it.
The full process happens almost instantaneously, without need for external interventions. It underlines how the said conversion mechanism can be used to redesign a neural model to a more suitable form for a production environment, optimizing further the time and space needed for inference, and using constantly amortized costs to achieve it.
General Training Workflow
As many readers might already know, an ideal workflow for a generic machine learning project starts by collecting and cleaning the corpus that will be used in the training phase. Equally important is the choice of the model architecture, as well as the set of hyperparameters that define it. Once these requirements are satisfied, the training phase can start. By the end of this process, we have multiple candidate models from which to choose. Of all of the candidate models generated, we’ll use the model that has the most promising results that match a set of predefined metrics (e.g., validation loss, recall, AUC), as well as the decision values that define the confidence level of the classifier.Additionally, in domains such as security, checking the FNs (false negatives) and FPs (false positives) generated when the model predicts on new data might prove useful in discovering relevant information through applying clustering or manual techniques. If the results obtained are satisfactory (e.g., high TPR, low FPR with proven robustness in terms of envisioned adversarial attacks), the code for inference using the chosen model will be converted into a low-level language that will be further optimized and that will offer safety guarantees
(i.e., prevention against memory leaks, memory corruption, race conditions).
As shown in our previous blog post, Rust proved to be a remarkable candidate for this specific task. However, we should mention that it can be replaced by any other low-level programming language. An upcoming performance assessment will target unseen data in a staging phase. The end goal is a thorough analysis of the classifier’s behavior in a controlled environment and checking whether the decision thresholds were suitably chosen, with the possibility of further fine-tuning. Finally, the model is released in production on the targeted endpoints, while carefully monitoring its performance. This process is usually reiterated multiple times through the classifier’s lifetime in order to enhance detection capabilities and keep up with the latest threats that emerge on a daily basis (see Figure 1).
Figure 1. General training workflow (Click to enlarge)Conversion Mechanism
Among the components described above, we'll now zoom in on the Rust conversion mechanism. The conversion mechanism previously mentioned is a generic tool designed to turn a TensorFlow model into pure Rust code. Its main purpose is to filter redundant information and keep only the relevant details needed for inference (i.e., weights and descriptive hyperparameters for each layer) and recreate the target model based on the dependencies described in the computational graph. Finally, the resulting Rust files can then be used to safely run the model in production while achieving a remarkable boost in performance. This mechanism can be further divided into two strongly related parts (see Figure 2):- Neural layers (Rust crate)
- Rust converter (Python package)
Figure 2. Conversion mechanism (Click to enlarge)Neural-Layers Crate
In Rust terminology, a crate is a package containing the implementations of multiple functions. For our use case, we redesigned and implemented from scratch each layer of interest in our neural architectures. Several optimization techniques were applied along the way: 1) using iterators instead of directly indexing the matrices, 2) batch serving capabilities, and 3) using generalized matrix multiplication routines for the bottleneck layers (e.g., the convolutional layer). Additionally, BLAS (Basic Linear Algebra Subprograms) was enabled to make the required multiplications even faster, without introducing prediction errors. This package is built on top of the Ndarray Rust crate, a powerful numerical package that offers multiple functionalities. Similar to Python’s NumPy, the mentioned crate implements facilities ranging from very optimized operations, parallel iterators and multithreading to easy serialization capabilities — and many more.Note: At this point, we didn't make use of any of ndarray’s multithreading functionalities, which means that there is still room for improvement. We expect this particular step to have an impressive impact, especially on very deep neural networks with large input features.
Rust Converter
The Rust conversion mechanism is equally significant and able to recreate the entire logic behind the given neural network. This mechanism was built with extensibility in mind, in an object-oriented programming style, to account for other layers that could become relevant in future projects. Note that there is a one-to-one mapping between the Rust code and the corresponding Python class for each layer. Each such entity contains the hyperparameters needed to restore the layer, their dependencies and two flags: one allowing the layer to execute the operation in place (e.g., Batch Normalization, ReLU, Softmax, etc.), and the other allowing the outputs to be declared mutable (a particularity of Rust’s ownership mechanism). Needless to say, in-place execution already implies that the output is mutable while the reverse doesn’t necessarily hold. Additionally, the model is sanitized, meaning that various regularization layers (e.g., Dropout, Spatial Dropout, Gaussian Dropout and Gaussian Noise) are removed from the model, and the dependency chain is updated accordingly. Figure 3. Possible scenarios (Click to enlarge)another layer as well (the Conv1D layer), which can enter an undefined behavior regime based on which branch is first executed (Figure 3, Scenario 2). Moreover, for such in-place execution to happen, the input(s) passed to the function must be themselves declared as mutable beforehand (Figure 3, Scenarios 1 and 3) — otherwise, this feature cannot be enabled. As for the files generated by this mechanism, they are as follows:
- A building file — used only once, to serialize the model
- A file exposing the end API, as well as the one including the tests
- A model source file containing a Rust structure that encapsulates the computational logic
- A file containing the model’s weights, as extracted by the Rust converter
- A dedicated file for assessing the performance of the neural model
- A file enabling all of the necessary imports and optimization flags
Demo
To offer a visual explanation of the entire workflow, a charCNN architecture (as described in Character-level Convolutional Networks for Text Classification) was passed as input for the algorithm. All of the steps, the commands passed and the files generated are shown in the video below.
The full process happens almost instantaneously, without need for external interventions. It underlines how the said conversion mechanism can be used to redesign a neural model to a more suitable form for a production environment, optimizing further the time and space needed for inference, and using constantly amortized costs to achieve it.
Conclusion
We strive to empower every scientist to choose the tools they prefer, or those that best solve the challenges they are trying to address. This is especially important in the rapidly changing world of deep learning, where every new day brings us closer to the next breakthrough that could shape the industry. Building on this idea, the next improvement would be to employ a more standardized format that can unify models from various deep learning frameworks (i.e., ONNX). This would ensure that there would be no need to impose a particular development framework and would instead allow our engineers to decide for themselves based on their preferences. Moreover, even though Rust proved to be a remarkable candidate for our deep learning models (in terms of time, space and addressing security concerns), we are not going to stop here — we’ll continue exploring further optimization strategies to make our models even faster by 1) using multi-threading when the situation allows, or 2) modifying the data’s format to use simple but extremely optimized routines. Finally, having a generic conversion mechanism at our disposal enables us to shift our attention toward more creative tasks — such as designing, fine-tuning or validating different architectures — while minimizing the cost of preparing these models for production. These added benefits ultimately translate into better models that will not only run faster (due to time/memory gains) but will also offer a wider range of security coverage, since its performance was validated against a larger pool of architectures than before.Additional Resources
- Learn more about the CrowdStrike Falcon® platform by visiting the product webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.

