





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































In our last post, Testing Data Flows using Python and Remote Functions, we discussed how organizations can use remote functions in Python to create an end-to-end testing and validation strategy. Here we build on that concept and discuss how it is possible to design the code to be more flexible.
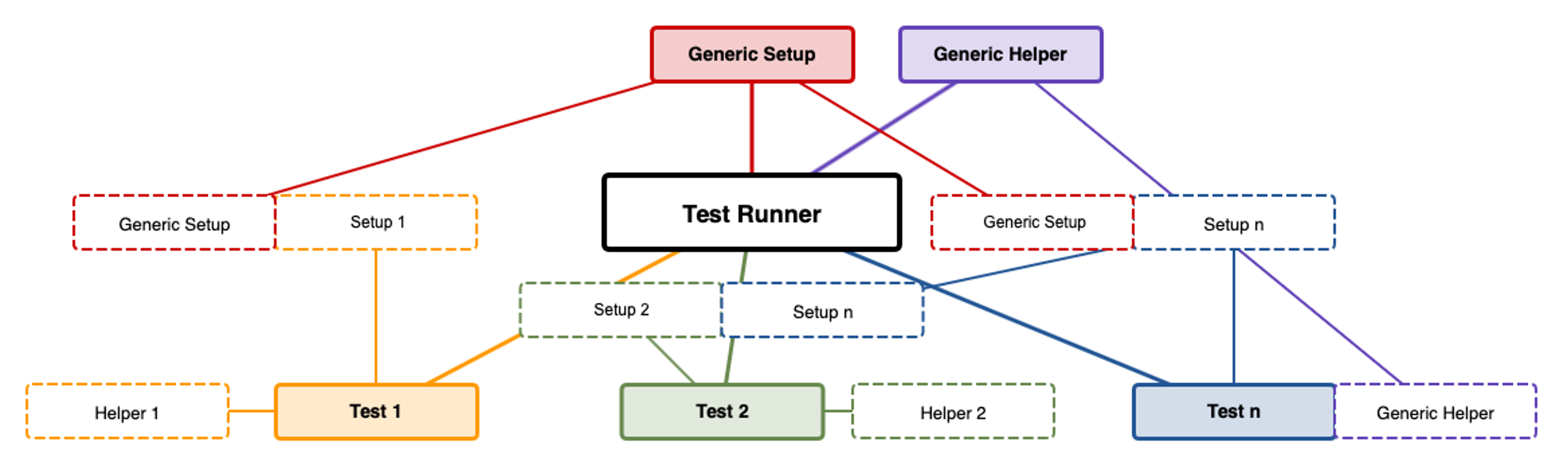 A classical testing view is defined by a sequence of steps that do a particular action on the system. This typically contains:
A classical testing view is defined by a sequence of steps that do a particular action on the system. This typically contains:
 You can see the following highlights from the diagram above:
You can see the following highlights from the diagram above:
The Advantages of a Modular Testing Approach
There are several key advantages to this approach:
For our purposes, flexible code means two things:
- Writing the code in such a way that most of it can be reused
- Creating a pool of functionalities that can be combined to create tests that are bigger and more complex.
| What is a flow? |
| A flow is any unique complex sequence of steps and interactions that is independently testable. |
| Flows can mimic business or functional requirements. |
| Flows can be combined in any way between themselves to create higher level or specific flows. |
The Need to Update the Classic Testing View
A classical testing view is defined by a sequence of steps that do a particular action on the system. This typically contains:
- A setup which will prepare the test environment for the actual test. Eg: creating users, populating data into a DB, etc.
- A series of actions that modifies the current state of the system and checks for the outcome of the performed actions
- A teardown that should return the system to initial state before the test
CrowdStrike’s Approach: A Modular Testing Model
To avoid these issues, we take a modularized approach to testing. You can imagine each test component as a Lego block, wherein each piece can be made to fit together in order to create something bigger or more complex.These flows can map to a specific functionality and should be atomic. As more complex architectures are built, unless the functionality has changed, you don't need to rewrite existing functions to fit. Rather, you can combine them to follow business context and business use cases.
The second part of our approach relates to functional programming, which means we create independent testable functions. We can then separate data into payloads to functions, making them easy to process in parallel.
Business Case: A Product That Identifies Security Vulnerabilities
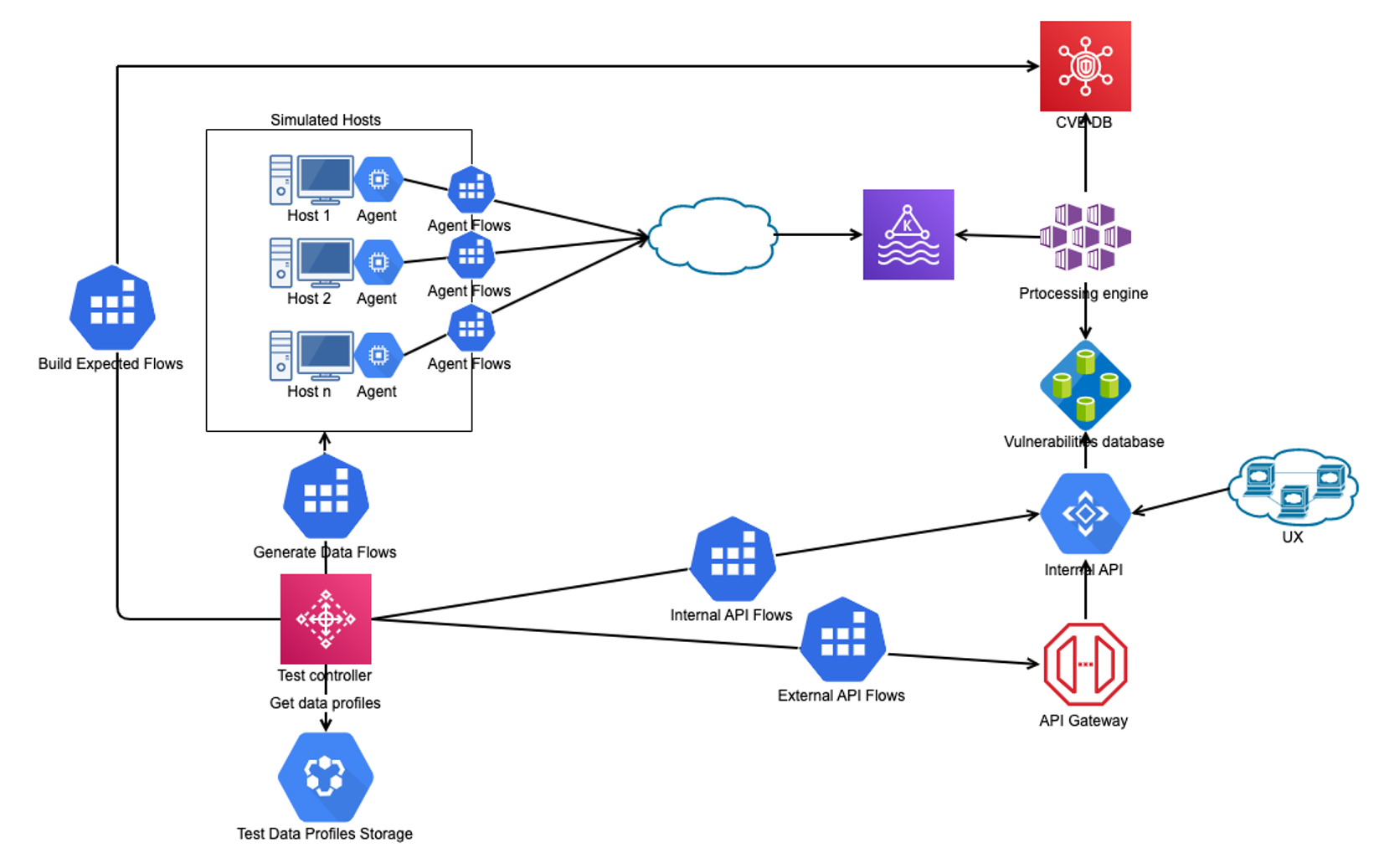
To illustrate this point, let's take a business use case for a product that identifies vulnerabilities for certain applications installed on a PC. The evaluation will be based on information sent by agents installed on PCs about supported installed applications. Information could be the name of the application, installed version, architecture (32 or 64 bits). This use case dictates that if a computer is online, the agent will send all relevant information to the cloud where it will be processed and evaluated against a publicly available DB of vulnerabilities (NVD). (If you are unfamiliar with common vulnerabilities and exposures, or CVE, learn more here.) Our testing flows will be designed around the actual product and business flows. You can see below a basic diagram of the architecture for this proposed product.
You can see the following highlights from the diagram above:
- A database of profiles for different versions of OS and application to be able to cover a wide range of configurations
- An orchestrator for the tests which is called Test Controller with functionalities:
- Algorithm for selecting datasets based on the particularities of the scenario it has to run
- Support for creating constructs for the simulated data.
- Constructs that will be used to create our expected data in order to do our validations post-processing
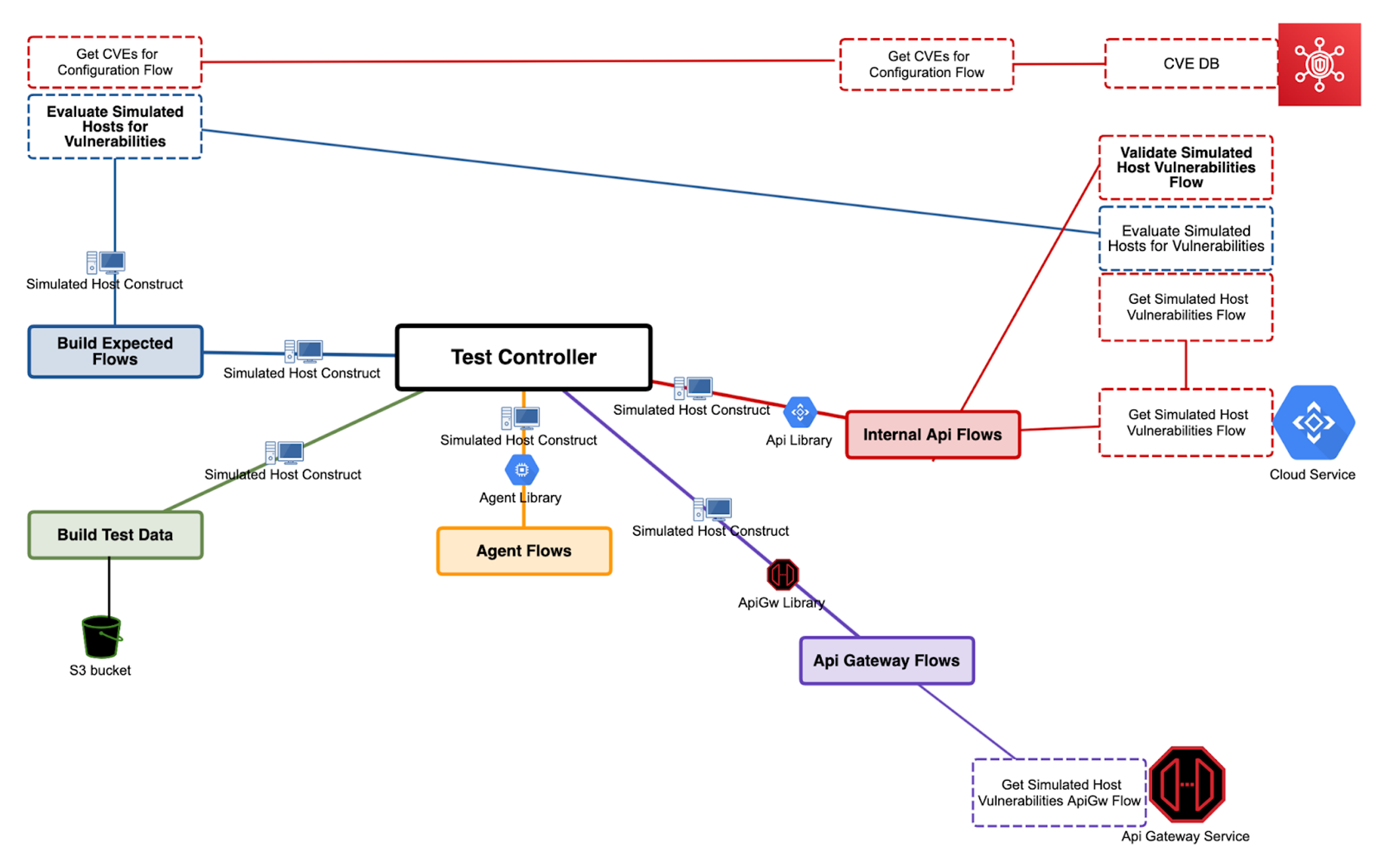
A closer look at the flows diagram and code
Flows are organized into separate packages based on actual business needs. They can be differentiated into public and internal flows. A general rule of thumb is that public flows can be used to design test scenarios, whereas internal flows should only be used as helpers inside other flows. Public flows should always implement the same parameters, which are the structures for test data (in our case being simulated hosts and services).# Build Simulated Hosts/Services Constructs
In this example all data is stored in a simulated host construct. This is created at the beginning of the test based on meaningful data selection algorithms and encapsulates data relevant to the test executed, which may relate to a particular combination of OS or application data.import agent_primitives
from api_helpers import VulnerabilitiesDbApiHelperRest, InternalVulnerabilitiesApiHelperGrpc, ExternalVulnerabilitiesApiHelperRest
@dataclass
class TestDataApp:
name: str
version: str
architecture: str
vendor: str
@dataclass
class TestDataDevice:
architecture: ArchitectureEnum
os_version: str
kernel: str
@dataclass
class TestDataProfile:
app: TestDataApp
device: TestDataDevice
@dataclass
class SimulatedHost:
id: str
device: TestDataDevice
apps: List
agent: agent_primitives.SimulatedAgent
def flow_build_test_data(profile: TestDataProfile, count: int) -> List:
test_data_configurations = get_test_data_from_s3(profile, count)
simulated_hosts = <>
for configuration in test_data_configurations:
agent = agent_primitives.get_simulated_agent(configuration)
host = SimulatedHost(device=configuration.get('device'),
apps=,
agent=agent)
simulated_hosts.append(host)
return simulated_hostsIn case you need to mutate states or other information related to that construct, any particular flow can return the host’s constructs to be used by another higher-level flow. TestServices construct encompasses all the REST/GRPC services clients that will be needed to interact with cloud services to perform queries, get post-processing data, etc. This will be initialized once and passed around where it is needed.
@dataclass
class TestServices:
vulnerabilities_db_api: VulnerabilitiesDbApiHelperRest
internal_vulnerabilities_api: InternalVulnerabilitiesApiHelperGrpc
external_vulnerabilities_api: ExternalVulnerabilitiesApiHelperRest# Agent Flows
def flow_agent_ready_for_cloud(simulated_hosts: List):
for host in simulated_hosts:
host.agent.ping_cloud()
host.agent.keepalive()
host.agent.connect_to_cloud()
def flow_agent_send_device_information(simulated_hosts: List):
for host in simulated_hosts:
host.agent.send_device_data(host.device_name)
host.agent.send_device_data(host.device.architecture)
host.agent.send_device_data(host.device.os_version)
host.agent.send_device_data(host.device.kernel)
def flow_agent_application_information(simulated_hosts: List):
for host in simulated_hosts:
for app in host.apps:
host.agent.send_application_data(app.application_name)
host.agent.send_application_data(app.version)# Internal API Flows
Internal flows are mainly used to gather information from services and do validations. For validations we use a Python library called PyHamcrest and a generic validation method that compares our internal structures with expected outcome built at the beginning of test@retry(AssertionError, tries=8, delay=3, backoff=2, logger=logging)
def flow_validate_simulated_hosts_for_vulnerabilities(hosts: List, services: TestServices):
expected_data = build_expected_flows.evaluate_simulated_hosts_for_vulnerabilities(simulated_hosts, services)
for host in simulated_host:
actual_data = flow_get_simulated_host_vulnerability_flow(host, services)
augmented_expected = {
"total": sum()
}
actual, expected, missing_fields = test_utils.create_validation_map(actual_data, ,
augmented_expected)
test_utils.assert_on_validation_map(actual_status_counter, actual, expected, missing_fields)
def flow_get_simulated_host_vulnerabilities(simulated_host: SimulatedHost, services: TestServices):
response = services.internal_vulnerabilities_api.get_vulnerabilities(host)
response_json = validate_response_call_and_get_json(rest_response, fail_on_errors=True)
return response_jsonThe Advantages of a Modular Testing Approach
There are several key advantages to this approach:
- Increased testing versatility and simplicity. Developers are not dependent on a certain implementation because everything is unique to that function. Modules are independent and can work in any combination. The code base is independently testable. As such, if you have two flows that do the same thing, it means that one can be removed.
- Improved efficiency. It is possible to “double track” most of the flows so that they can be processed in parallel. This means that they can run in any sequence and that the load can be distributed to run in a distributed infrastructure. Because there are no dependencies between the flows, you can also “parallelize” it locally to run multiple threads or multiple processes.
- Enhanced testing maturity. Taken together, these principles mean that developers can build more and more complex tests by reusing common elements and building on top of what exists. Test modules can be developed in parallel because they don’t have dependencies between them. Every flow covers a small part of functionality.
Final Thoughts: When to Use Flow-based Testing
Flow-based testing works well in end-to-end tests for complex products and distributed architectures because it takes the best practices in writing and testing code at scale. Testing and validation has a basis in experimental science and implementing a simulated version of the product inside the validation engine is still one of the most comprehensive ways to test the quality of a product. Flows-based testing helps to reduce the complexity in building this and makes it scalable and easier to maintain than the classical testing approach. However, it is not ideal when testing a single service due to the complexity that exists at the beginning of the process related to data separation and creation of structures to serialize data. In those instances, the team would probably be better served by a classical testing approach.Finally, in complex interactions between multiple components, functionality needs to be compartmentalized in order to run it at scale. In that case, flow-based testing is one of the best approaches you can take. When do you use flow-based testing — and what questions do you have? Sound off on our social media channels @CrowdStrike.


