





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)








































One common challenge facing cloud engineers is how to develop and run tests that are distributed across multiple clusters, teams, environments or services. The use of new technologies, like containerized workloads and services via Kubernetes, amplify this issue, requiring organizations to rethink validation across entire architectures instead of particular subcomponents.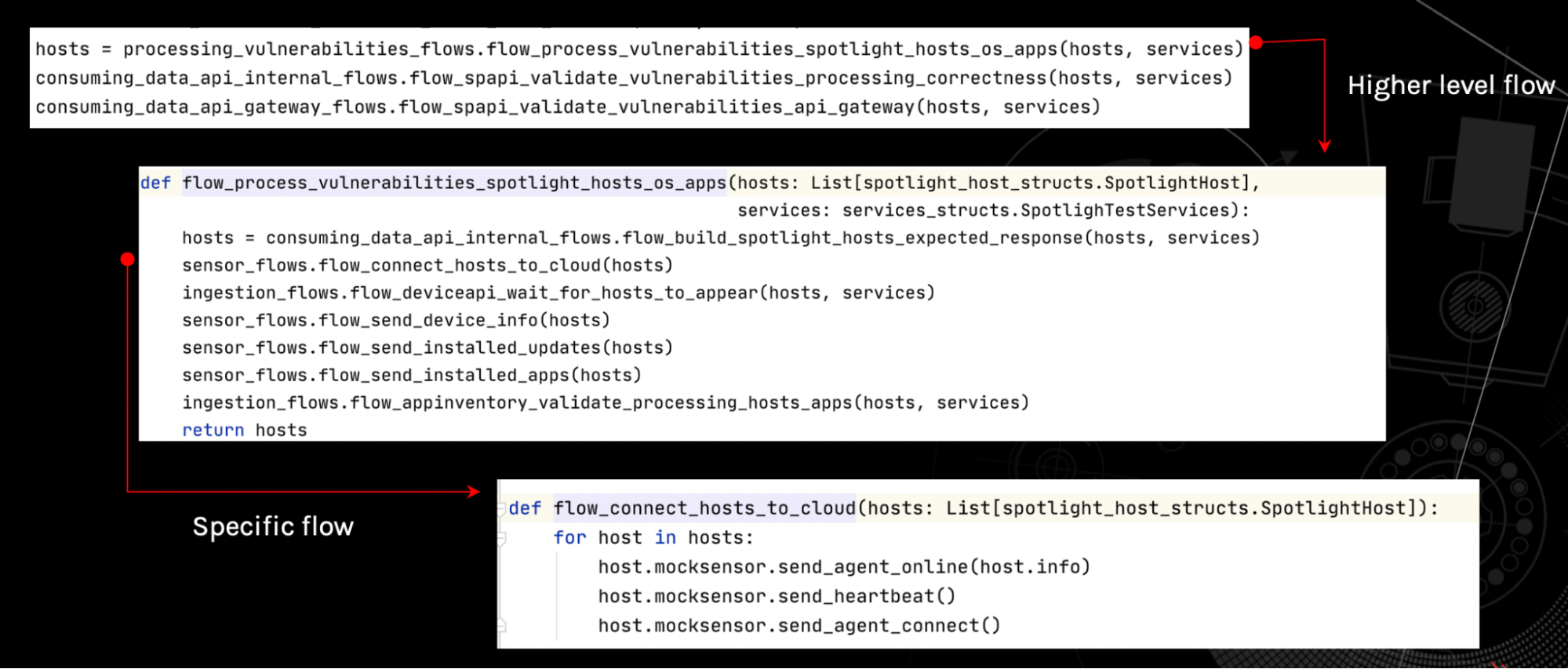 As seen above, we start from a very specific function (bottom box) that sends certain events to populate data for a particular host. This is then used in a more complex function that creates and validates that a host was registered correctly in our cloud with device and application data. In the end, higher level flows can combine any number of pieces to create a more complex test.
As seen above, we start from a very specific function (bottom box) that sends certain events to populate data for a particular host. This is then used in a more complex function that creates and validates that a host was registered correctly in our cloud with device and application data. In the end, higher level flows can combine any number of pieces to create a more complex test.
In this post, we explore how organizations can design an end-to-end approach to testing and validation and the value of doing so.
Defining the Function for Streamlined Validation
Most cloud developers focus on “their part,” be it a piece of functionality, service or product. This introduces a level of disposability in the testing and validation process. While this approach works, developers tend to build libraries and helpers for the point of using them once, only in a test. This often leads to some patterns where tests written tend to be overly simplistic or too complex, which in turn could create coverage black holes or test maintenance nightmares. In addition, integrating different patterns for designing tests and validation approaches tends to be more of a bother than a benefit. This also creates a steep learning curve for different areas of product and functionality, which will force people who face deadlines or some technical challenges not to take the best path. Writing end-to-end complex scenarios is by definition a combination of different functionalities that need to work together — the test’s codebase needs to share the same principles of implementation and design as the services they are testing.Our solution was to create a pool of functionalities that all of our engineers, whether they work on the cloud, our sensor or even R&D, can access. We combine the test and helpers into a unit that can be reused over time. With this approach, when an engineer wants to test a particular functionality from a product or service they can search in the common pool of functions for one that fulfills that purpose. This drives both consistency and efficiency in that developers don’t have to recreate existing tests, and a one-test mechanism is used in all instances. Perhaps more importantly, this approach allows our team to build more complex tests. The team can combine different functions to achieve coverage of a functionality. For instance, if an engineer wants to simulate a host that has OS/APPS vulnerabilities, they can use a function that populates device data in a service and another that pushes applications data in another service. An upstream service can use both these sources of data to evaluate a host for both OS and APPS vulnerabilities. If there are functionalities within the pool that cover all these individual pieces, then an engineer can put them together in a more complex function without the need for individualized testing.
In the graphic below, we share an example of how independent functions can be used to create more complex functionalities.
As seen above, we start from a very specific function (bottom box) that sends certain events to populate data for a particular host. This is then used in a more complex function that creates and validates that a host was registered correctly in our cloud with device and application data. In the end, higher level flows can combine any number of pieces to create a more complex test.
Operating the Function Pool
A pool of functions is like a repository in that you can use one part of the code or multiple parts combined. If needed, code can be extended or forked to create your own implementation. The running part should have an abstract layer that can be configured at runtime. For example, in this model, if an engineer wants to run a particular function on a cluster in AWS, then they can select the functions that they want to run and the provider without any other test development needed. Like many organizations, prior to this approach, CrowdStrike was using a test runner like pytest, which runs tests as a single process. The advantage of this system is that it provides methods to run setups/teardowns, orchestrate test runs and aggregate results. However, using a test runner that manages all aspects of the process as compared to a decentralized approach like Remote Functions has two main disadvantages: it needs to run all tests on a single instance and it can only scale vertically. It would not allow the team to run multiple scenarios and different combinations, or scale in order to run many scenarios concurrently. Enabling such a functionality requires a different kind of infrastructure.One simple illustration of this issue is Ray tool(ray.io). Ray is essentially a master-worker architecture that can scale based on computing load provided and runtime. It provides a way to schedule jobs (functions with payload), distribute them to workers, gather results, scale up clusters in case of load increase and provide monitoring. Other examples are AWS Lambda, Azure Functions, Google Cloud Functions. They all have support for running Python code following a certain definition for creating the jobs and distributing the payload (grpc, s3, etc).
To address this issue, we began using a serverless infrastructure, similar to Amazon Lambda or Azure. In this scenario, we have a job and the definition of the job. Inside the definition of the job we already have the payload—we just need to schedule it. This scalable model allows for the addition of more resources and horizontal scaling without any disruptions, infrastructure or code changes. So if we want to run 100 jobs, we just create or push 100 jobs to the schedule. Then the infrastructure automatically takes care of running them.
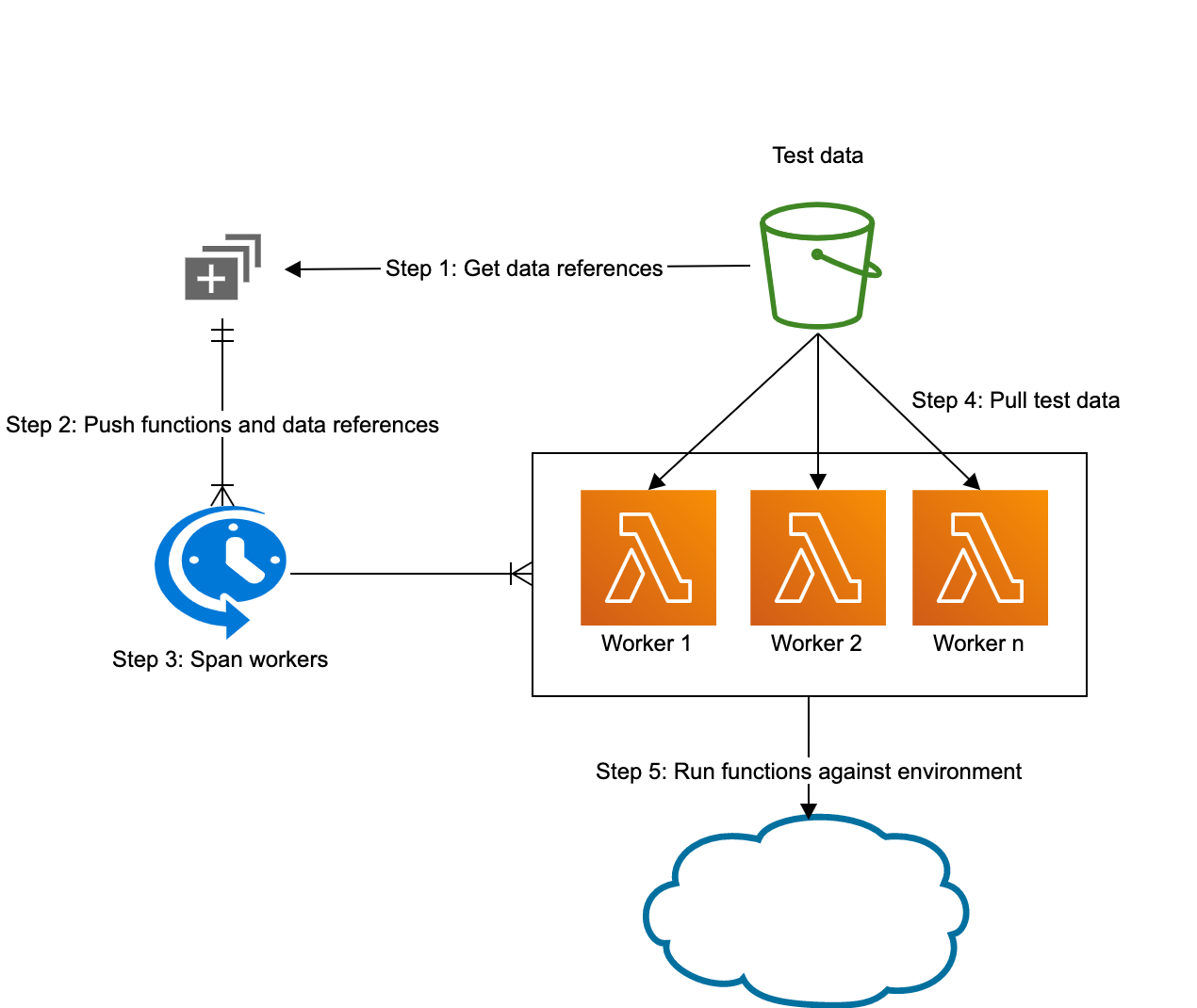
In the graphic below, we see a proposed architecture where test data, function pool and infrastructure are decoupled. They can then be combined inside the worker pool based on the types of jobs (functions with payload) we want to run.
Limitations
One limitation of our solution relates to scalability. When we want to scale thousands of instances, it can be difficult in a classical approach—which is to say through horizontal scalability. Typically, in these cases we need to scale vertically to add more and more resources to those machines. While that works, there is a cost implication to doing so. Another limitation is that the organization will need to rethink use cases and decouple them in order to be able to run independently. States can be shared through payload and test data.The Benefits of Remote Function Testing
As noted above, our approach to testing and validation has some obvious benefits for our organization:
- Efficiency. Working from a common pool saves the team time and reduces the amount of testing and validation that the team has to complete.
- Consistency. This approach also establishes a single source of truth for the organization when it comes to testing.
- Complexity. This testing model allows our team to combine multiple test components to build more complex testing mechanisms.
- Debugging. If the function interacts with a service that has access to data, it can be used to create and run a “step inside” a test, which can be used to gather information to debug a situation.


