





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)








































In a previous post, our team shared our Three Best Practices for Building a High-Performance Graph Database. That was written two years ago, when CrowdStrike Threat Graph® was processing billions of events per day and storing a few petabytes of data. Fast forward to today: CrowdStrike Threat Graph now stores over 40 petabytes of data and regularly handles trillions of events per day while routinely serving upward of 70 million requests per second. All that data prompted our team to build other systems to process the same data feed in many different ways, allowing our engineers to do anything from creating data lakes to performing real-time streaming queries.
As any data engineer will tell you, handling data at the CrowdStrike scale does not come easy. Protecting our customers means that CrowdStrike engineers must be very careful in choosing the right tools, techniques and data structures to solve the problems at hand. Over the past few years, one of the technologies that has served CrowdStrike remarkably well and continued to support our rapid growth are database engines built using log-structured merge (LSM) trees.
In this post, we’ll examine the inner workings of LSM trees and why databases based on them are a great match for processing data at CrowdStrike scale.
Understanding the Domain
As an engineer, the first step in choosing a database is to understand the characteristics of the data to be stored and the associated access patterns for reading and writing that data.
Because CrowdStrike is ingesting data at a massive scale, keeping up with the write load and not falling behind the incoming data stream is of critical importance. In addition, when it comes to security telemetry, every piece of data is potentially meaningful. While many big data systems will resort to sampling a subset of incoming data and using statistical analysis to manage an extremely high data load, that approach does not work in the security domain.
To stop breaches and protect customers, every event that reaches our cloud can play a role in helping us detect adversary activity in our customers’ environments. Therefore durably storing every event is critical. At the same time, security telemetry resembles many time-series data problems in that newer data tends to be accessed more frequently than older data.
With these parameters in mind, we can set a few high-level tenets for how we store incoming event data at CrowdStrike:
- Optimize for writes. Data is read much less often than it is written. For example, approximately six out of every seven API calls in CrowdStrike Threat Graph are write operations. We optimize for write throughput by treating incoming data as an append-only log.
- No explicit deletes. Our team avoids costly delete operations by using secondary strategies like time-to-live (TTL) mechanisms that can be applied in the background.
- Simplicity is key. We bias toward data storage strategies with simple schemas and technologies that are easy to understand and manage.
- Data is still time-series. While newer data is more relevant and queried more frequently than older data, we still need to provide a path for retrieving older data as needed.
Given these tenets, CrowdStrike was able to determine that LSM tree-based databases such as Apache Cassandra and RocksDB were a potentially good fit for our domain.
In the next section, we will examine LSM trees in a bit more detail to understand how they work and then discuss why they are a good fit for CrowdStrike’s use case.
Meet the Log-Structured Merge Tree
The LSM tree as a data structure was first introduced more than 25 years ago, but rose to prominence more recently as companies needed more efficient ways to store data at scale.
The LSM tree inverts the thinking of a typical database indexing structure; whereas a structure like the ubiquitous B-Tree is generally faster at reads, the LSM tree is optimized for high write throughput. A typical LSM tree-based database consists of a few major components that we will describe in more detail below:
- An in-memory index, or “memtable”
- A set of immutable on-disk files (a.k.a. “Sorted String Tables” or “SST files”)
- A durable log, such as a write-ahead log (WAL)
- A background operation known as compaction
An overall architecture diagram of how these pieces fit together is shown in Figure 1 below.
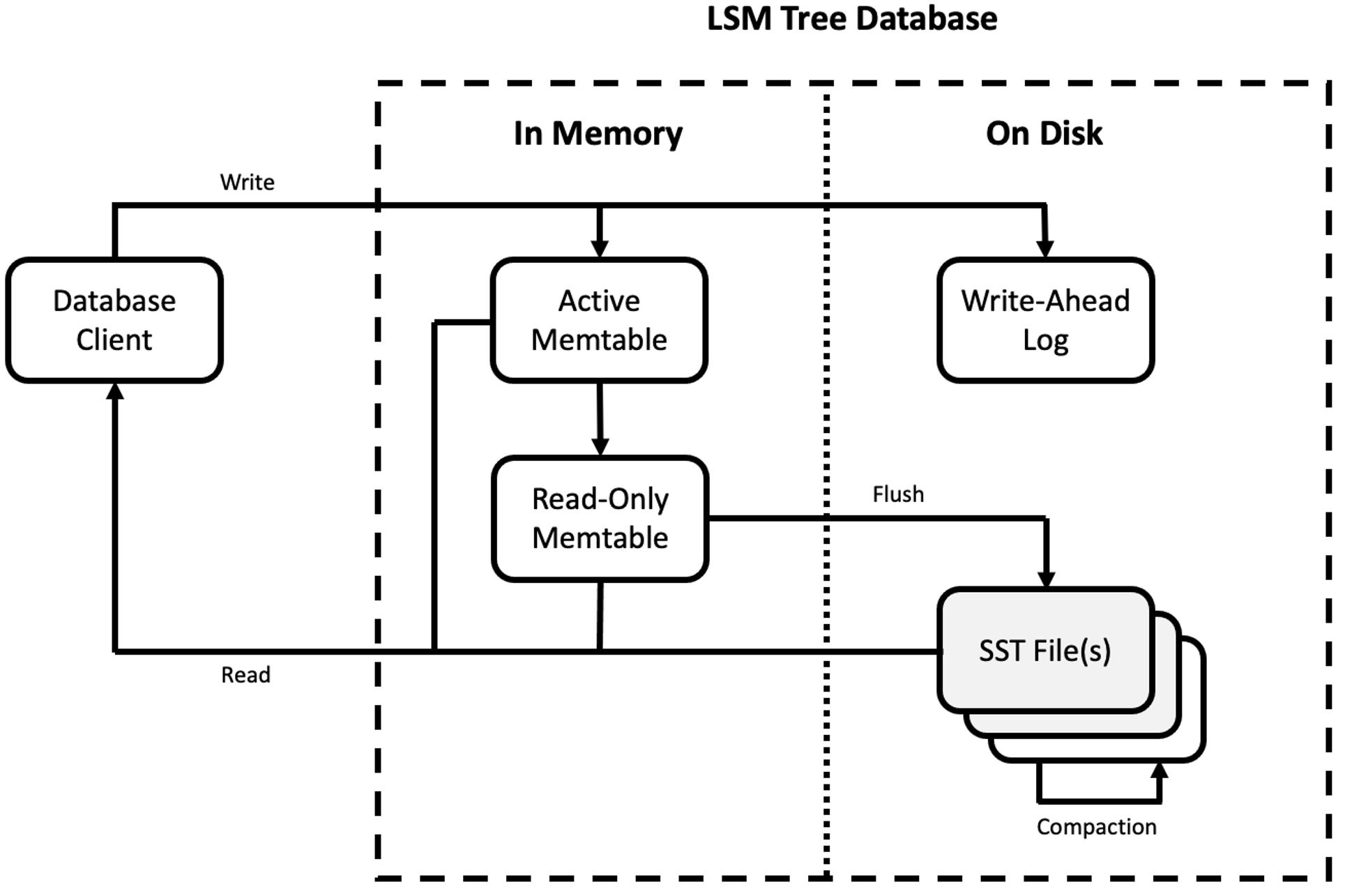 Figure 1. Log-structured merge tree architecture
Figure 1. Log-structured merge tree architectureAs we mentioned, simplicity is very important when it comes to data processing at scale. The first thing to notice about the LSM tree database is that it has relatively few moving parts. This makes it much easier to understand, reason about and manage.
Managing Writes in an LSM Tree
To see how an LSM tree optimizes for write efficiency, let’s follow the path of writing a new record to the database. The basic process is as follows:
- When a new write comes in, it is first serialized directly to the WAL. While this step is optional, the WAL provides a fast and easy mechanism for durability and crash recovery.
- Once the data has been serialized to the WAL, the data is written to an in-memory structure known as a memtable, which is an append-only, sorted structure like a skip list or self-balancing binary tree that will keep data organized by key. (This will be important later!)
- Once a record has been serialized to the WAL and appended to the memtable, the write operation is complete.
It is worth noting that because writes to a memtable happen in an “append only” fashion, updates and deletes behave slightly differently. That said, they still perform append-only operations (e.g., writing a new record for an update or a tombstone record for a delete) that the database then reconciles later.
To an LSM tree database client, write operations are always very fast and predictable because new writes are written to a sorted, in-memory memtable. It should be fairly obvious, however, that a simple in-memory structure will not scale indefinitely. Behind the scenes, the LSM tree database is monitoring the memtable so that once it reaches a certain size threshold, it will stop accepting new writes and be marked read-only so that it may subsequently be flushed to disk in the background. Meanwhile a new “active” memtable is spun up in its place to begin accepting new writes.
The newly full, read-only memtable is flushed to disk in a large, sequential write to generate a new Sorted String Table (SST) file. Sequential writes provide great data locality on spinning disk drives, but still have reduced write amplification and other advantages over traditional database structures like B-Trees, even when captured on solid state drives. Once an SST file is written to disk, it is considered immutable. Over time, as more memtables are filled, more and more SST files will be written to disk.
Managing Reads in an LSM Tree
Read operations are similarly straightforward. When looking for a record, the database will first check to see if the record exists in the active or read-only memtable; if it does not, it will investigate the SST files to see if any of them contain the record. If more than one copy of a record is found, such as in the case of an update or a delete, the latest operation will take precedence. Investigating the memtable and SST files is generally fast and easy because they are maintained in a sorted order. Most LSM tree databases also maintain an auxiliary set of data structures, such as indexes or bloom filters, either in memory, in the SST files themselves, or both, to speed up record lookups.
If this was where the logic stopped, writing to an LSM tree database would always be fast. Unfortunately, reads become slower over time as more SST files are written to disk and more “garbage” entries are created by update and delete operations. To mitigate these issues, the LSM tree database will periodically merge adjacent SST files in a process called compaction. Compaction is an internal database operation that happens in the background independently from reads and writes. Its goal is to reduce the number of SST files and eliminate garbage from updates and deletes in the process.
If you’re familiar with the Merge Sort algorithm, compacting two SST files is a very similar operation; because two SST files are both sorted, the algorithm can merge them in a linear fashion to maintain record ordering and drop any garbage as it goes. Compaction is also a great place to bake in other functionality such as TTL mechanisms where the compaction algorithm can discard records whose TTL value is past expiration.
Bringing It All Together in the CrowdStrike Falcon Architecture
Now that we’ve discussed the scale and characteristics of CrowdStrike’s data as well as the inner workings of the LSM tree, we can examine how this technology fits into our architecture.
As we mentioned previously, running a database at CrowdStrike scale means processing and storing trillions of events per week. As a result, we optimize for write load and keep up with our incoming data stream by using append-only semantics for data storage where possible. These constraints line up well with the internal architecture of an LSM tree database that also operates in an append-only fashion and keeps write operations fast and predictable via in-memory writes to memtables. Given that in our high-scale systems like CrowdStrike Threat Graph six out of every seven operations is a write, it makes sense to optimize writes first.
While having fast write operations is great, we still want read operations to be performant for our customers. It turns out that another feature of LSM trees — the sorting of data in memtables and SST files — can be used to further optimize our read use cases as well. More details are available in our previous blog, but in short we optimize storage of graph-like data by carefully choosing our records’ keys to leverage LSM tree’s inherent sorting. This allows us to place related entities, such as graph vertices and associated edges close to one another in memory and on disk. Due to the sorting baked into the underlying memtable and SST files, most LSM tree databases can provide guarantees on data locality if you can intelligently structure your keys. This results in more efficient iterations that would otherwise require multiple queries to gather the same data.
The final area where LSM tree databases line up well with our requirements is in being able to leverage compactions to move key database operations into the background. At CrowdStrike we heavily leverage compaction-based TTLs to be an append only datastore and perform costly delete operations only in the background. In 2016, when CrowdStrike realized how effective TTLs and proper SST organization could be for time-series workloads, we contributed the original implementation of the TimeWindowCompactionStrategy back to the Apache Cassandra project. While our team had that breakthrough six years ago, the compaction and time-series strategies we introduced back then are still as effective as ever.
In adopting LSM tree-based databases as a core building block of CrowdStrike Threat Graph and other CrowdStrike backend systems, we have been able to scale to many petabytes of data and handle trillions of events weekly in the service of stopping breaches and keeping customers safe.
Have questions or ideas? We’d love to hear your thoughts on our approach, how you would manage this challenge or any questions you may have about this project. Sound off on social media to @CrowdStrike.


