Cracking the Code of AI Decision Making: Harnessing the Power of SHAP Values

- Machine learning explainability ensures that AI models are transparent, trustworthy and accurate
- Explainability enables data scientists to understand how and why an AI model arrived at a particular decision or prediction
- SHAP values are a powerful tool for explainability as they provide a way to measure the contribution of each feature in a model to the final prediction, offering insights into how the model reached a prediction
Despite the race to integrate artificial intelligence (AI) and machine learning (ML) into business systems and processes, the crucial issue of comprehending and articulating the decision-making process of these models is often ignored. Although machine learning is a valuable tool for uncovering pertinent information from vast amounts of data, it is essential to ensure the relevance, accuracy and reliability of this information. Therefore, comprehending and being able to explain the reasoning behind AI models’ decisions can help data scientists construct unbiased, dependable models that produce precise and trustworthy predictions.
Explainability of AI models can help crack the code on AI decision-making. The use of SHAP (SHapley Additive exPlanations) values can be a powerful tool for data scientists to build accurate machine learning models by identifying areas where the model may be making errors or where the data used to train the model may be flawed.
Why Do We Need AI Explainability?
There are three major reasons why AI explainability is critical. First, by providing clear and transparent explanations of how the AI model arrived at its decisions, stakeholders can understand the rationale behind the decisions and build trust in the model. Second, explainable models can help detect and address unintentional biases, ensuring that the decisions made by the model are fair and unbiased. And third, data scientists can identify areas where the model may be making errors in decision-making or where the data used to train the model may be flawed, which can help refine the model and improve its accuracy.
Explainability methods usually aim to reveal what features are the most important for a given prediction (e.g., for classification, the class predicted for that particular example), as displayed in Figure 1. In cybersecurity, with high stakes on the line, being able to understand the reasoning behind the predictions of an AI detection system allows threat analysts to gain a deeper understanding of the threat landscape. Moreover, an automated way of understanding what fuels the decisions of an ML model can facilitate interactions with customers and even advise on the best remediation measures applicable in the case of malicious activity being detected by an AI system. Thus, model explainability is an important topic, but one that is rarely brought up.
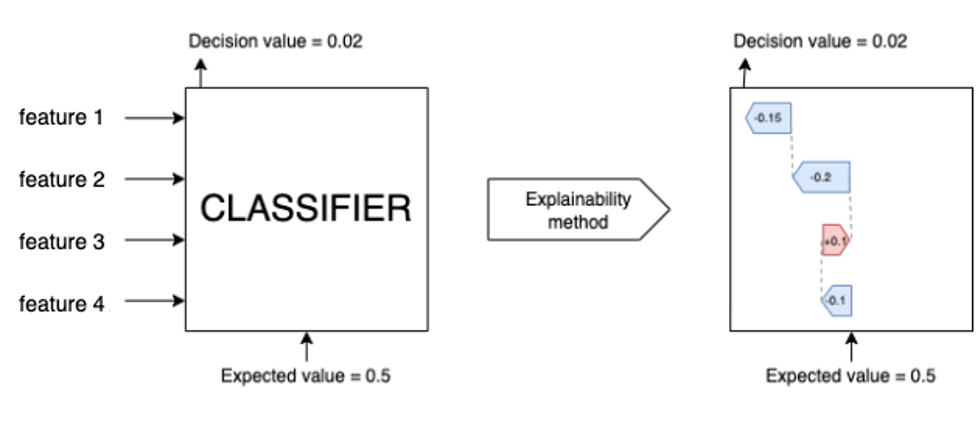
Figure 1. Model explainability: the ability to explain, from the model’s perspective, why certain detections happen and how certain features influence the prediction
In Figure 1, the features are represented by Feature 1, Feature 2, Feature 3 and Feature 4. The values on the right-hand side are the features’ actual SHAP values, and they sum to the model’s prediction. The sign of the SHAP values is indicative of the contribution toward positive class.
Depending on the type of problem, architectural constraints or other use-case-specific limitations, there are a variety of explainability paths we can explore. Here we focus on explainability in two different types of ML methods that have become very popular in cybersecurity in recent years: tree-based models (e.g., XGBoost, Random Forest) and neural networks.
Model Explainability for Tree-based Models
SHAP is a game theoretic approach named in honor of Lloyd Shapley and is based on the idea that the outcome of each possible combination of features should be considered to determine the importance of a single feature, as shown in Figure 2. This comes down to training an exponential number of distinct predictive models that are equivalent to each other, but using a different set of features.
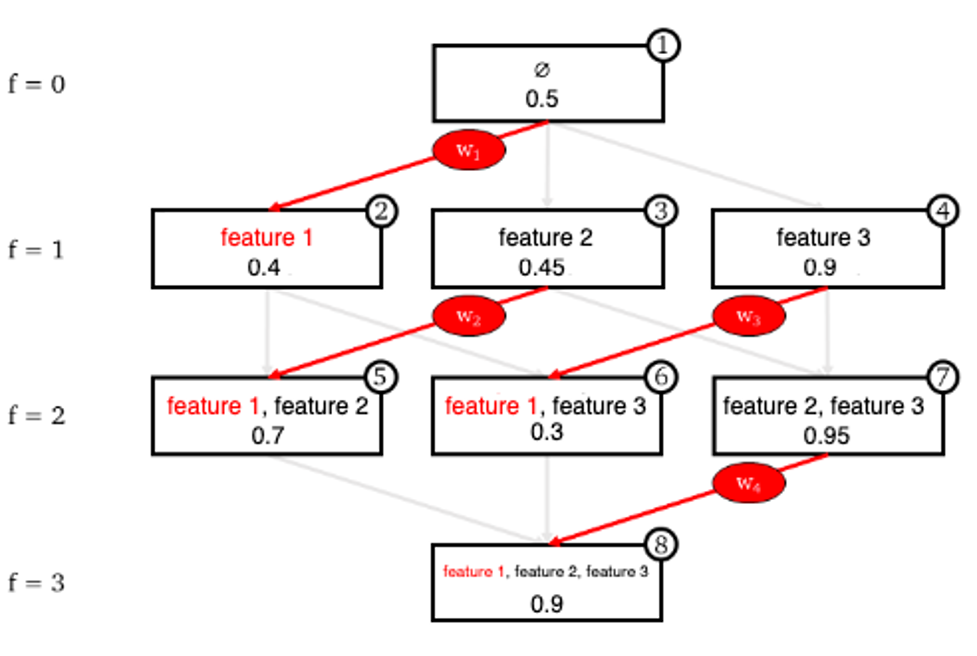
Figure 2. The impact of specific features over prediction. The red edges represent the contributions of the feature Feature 1 when different combinations of features are considered.
This approach is very time and resource intensive. Thus, existing feature selection methods take measures to avoid this kind of exhaustive search. One solution is to approximate the decision function by creating a series of perturbations to the sample (e.g., randomly set entries in the feature vector to zero) and then predicting a label for each of these perturbations. Using this sampling strategy, the local neighborhood is roughly approximated, therefore creating SHAP values when solving the regression.
When it comes to tree models and ensembles of trees, a very popular implementation of SHAP is the TreeExplainer, which can be found in the SHAP package, making it our go-to explainer for these types of models. TreeExplainer is a good choice because it includes fast runtime, it works under several different possible assumptions about feature dependence, and it gives exact and insightful information regarding the features’ influence on a prediction, as shown in Figure 3.
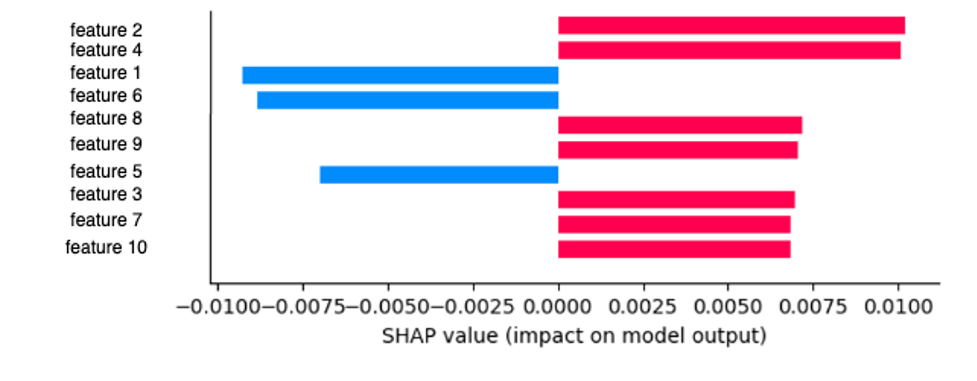
Figure 3. The impact different features have on a model’s output. We use blue to draw clean features and red to draw features pointing to this particular sample’s maliciousness.
Model Explainability for Neural Networks
Picking the best candidate for explainability in neural networks is not as straightforward. When first investigating this problem, our interest was in leveraging explainability methods applicable to all common architectures, such as MLPs (multi-layered perceptrons), CNNs (convolutional neural networks) and RNNs (recurrent neural networks). Therefore, approaches such as Grad-CAM (Gradient-weighted Class Activation Mapping) were purposely omitted.
We found a multitude of potential explainers, but before discussing the one we chose, let’s briefly review some of the other techniques that have various advantages and disadvantages:
- KernelExplainer explains the output of any function using a special weighted linear regression that computes the importance of each feature. However, it suffers from non-determinism and exponential computing time, making it unsuitable for most neural network-based architectures.
- Gradients and integrated gradients (IG): Gradients output a saliency map that measures prediction changes with respect to a given feature. Integrated gradients use a baseline to compute the importance of a feature by accumulating gradients with respect to that feature along the shortest path from the baseline to the sample. The advantage of this method is it uses the original network as is, and it is simple to implement.
- GradientExplainer approximates SHAP values to infinite player games using expected gradients, which combines ideas from integrated gradients, SHAP and SmoothGrad. Its drawback is non-determinism.
- Deep Learning Important FeaTures (DeepLIFT) determines the relevance of a prediction via the decomposition of the output of a neural network on a specific input by back-propagating the contributions of all neurons in the network to every feature of the input. It is efficient and connects with SHAP values.
- DeepExplainer is based on DeepSHAP and estimates the conditional expectations of SHAP values for deep learning models. It supports a wider variety of architectures but does not support all rules for assigning contribution scores. It scales linearly with the number of background data samples, and 1,000 or even 100 samples can give a good estimate of the expected values.
While working with DeepExplainer, we observed that a version of the SHAP package greater than 0.41.0 is required for TensorFlow v2 models. Also, some of the operations (e.g., the SELU activation) may not be supported yet. Fortunately, this is easily solvable by adding them manually here.

Figure 4. Patterns detected in a PowerShell script using DeepExplainer. Highlights in light red and red indicate substrings contributing weakly and strongly to the classifier’s prediction of maliciousness, respectively.
Our experiments showed that selecting a good baseline is a key step in applying the explainability methods discussed above (Integrated Gradients and DeepLIFT). It should convey a complete absence of signal, so features that are apparent from attributions are properties only of the input and not of the baseline. From our experience (see Figure 4), while applying explainability on neural networks working at character level, we have found that the all-zero input embedding vector is a good baseline.
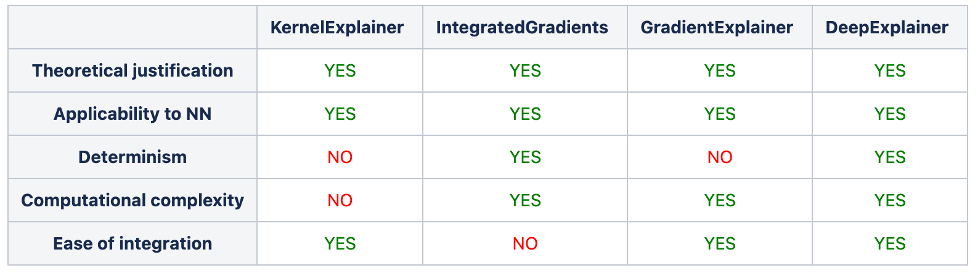
Table 1. A comparison of explainability methods for neural networks
Our experiments show that all of the methods considered for neural networks seem to mostly agree on the positive or negative impact of a feature. However, the value computed by each of these methods might be different because of the computation technique used. In the end, for consistency reasons we chose DeepExplainer because its determinism and its straightforward implementation in the SHAP package yield definite advantages.
Explainability Methods at CrowdStrike
When dealing with tree-based models as well as tree ensembles, a very promising explainability technique we have leveraged in the past with great success was the TreeExplainer, which is powered by SHAP. When it comes to understanding how certain features influence the prediction of a neural network, we have found that using DeepExplainer can help us gain more insights into a model’s predictions. Explainability methods are a complex topic and are part of an intricate system designed to offer the most accurate predictions to our customers, while ensuring that decisions are as transparent and well-informed as possible.
As part of our workflow, we always make sure to analyze the importance of a model’s features. This is regarded as an important sanity check among many others before deploying any AI model into production. Since classifiers are trained on large corpora, it’s crucial to ensure that features are indeed informative (no high correlation or redundancy) and also that their value distribution in the corpora is representative of real-world data.

Figure 5. Patterns detected in a PowerShell script using DeepExplainer. Highlights in red and green (light or strong) indicate substrings contributing (weakly and strongly) to the classifier’s prediction of maliciousness and non-maliciousness, respectively.
Explainability methods are also helpful for threat analysts and support teams. Using explainability, we can more easily and accurately explain to customers what triggered specific detections. In Figure 5, you can see some of the patterns that fueled the decision of our malware classifier for PowerShell scripts. This code snippet presents a weak obfuscation of the well-known Invoke-Expression (IEX) cmdlet, which evaluates or runs a specified string as a command. The actual command needs to be decoded from Base64 by a human in order to decide if the script is indeed malicious. Nevertheless, this assessment can serve as the basis for a more complex analysis.
Final Remarks
Auditing and protecting black-box learning systems against attacks is challenging, especially in cybersecurity. A lack of transparency is a significant security issue. Determining the features of an input that are decisive in making a given prediction is an example of a straightforward problem. However, problems like this often prove difficult to solve and are yet of utmost necessity.
Achieving explainability in cybersecurity ML models is crucial for identifying and addressing weaknesses. We discussed various methods for explaining the decision-making process of commonly used ML models in cybersecurity, including tree-based models and neural networks. While TreeExplainer is widely used for the former, the latter poses a challenge due to their opaque decision-making process. To address this challenge, we use a solution based on DeepExplainer that meets multiple requirements such as theoretical justification, accuracy of explanations, determinism, computational complexity, and robustness. While current explainability methods have limitations, they represent a positive step toward achieving explainable AI (XAI), which is essential for identifying and correcting model weaknesses to achieve optimal results.
Additional Resources
- Learn more about the CrowdStrike Falcon® platform by visiting the product page.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of CrowdStrike Falcon® Prevent.

