





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































Malware in the Scripting Landscape
Scripting is a well-known means of spreading malware. Easy to write and often difficult for security solutions to detect, scripts make the perfect tool for attackers. However, automatically differentiating between clean and malicious scripts is a challenging task, because in many cases understanding the intention behind the code is the only way to gain an accurate view of the script’s purpose. At CrowdStrike, our big-data-fueled platform provides expanded visibility into scripting languages, especially PowerShell, which is a focus throughout this blog. Some of the techniques we use at CrowdStrike encode the expertise of threat analysts. In addition, for data-heavy tasks, we like to leverage machine-learning (ML)-based approaches. In this post, we explore one such approach. When a PowerShell script is being executed, an event packing more context around the script is sent to the CrowdStrike® cloud. The content of this script is unpacked and fed into our ML model, Kestrel, which is essentially a character-level convolutional neural network (charCNN). It is described in the following sections.Kestrel: Approach and Motivation
Kestrel takes the content of a PowerShell script being executed as input, and plain text language modeling techniques have been key in approaching this task.We have tried several classifiers in initial experiments, such as: Logistic Regression, SVM (Support Vector Machines), Naive Bayes, etc. The results, however, have not risen to the requirements of what a malware classifier is expected to do. Better performance has been obtained with various ensemble models trained on the doc2vec features extracted from our PowerShell corpus. We decided to also take a neural approach and see by how much and at what cost we can improve the performance on the PowerShell dataset available for the experiments. A few neural models have been tried: charCNN, LSTM (long short-term memory networks), BiGRU (bi-directional gated recurrent unit) and HAN (hierarchical attention network). Although they rendered similar results, we have decided to continue with a charCNN, for the reasons presented in the following description of our work.
Features
By using a model that operates at the character level, we move past the time-consuming feature-engineering step. Another possibility we explored for features is the use of pre-trained word embeddings. However, in that approach, some preprocessing must be done on the original content as well as costly feature extraction periodically, as more data becomes available. With characters as features, our vocabulary is an alphabet with less than 5,000 elements (including the foreign characters discovered in the corpus: Chinese, Vietnamese, etc). We will see later how each of these characters is initially represented by its index in the alphabet and then assigned a vectorial representation, which was learned in an embedding layer while also (re)training the model.CNN
Another reason for choosing a CNN from all of the types of neural networks available is that this model is lightweight. This offers better maintainability properties, and due to its small size, the model can be deployed anywhere.Interpretability
A CNN has more interpretability due to its convolutional layers that keep some spatial clues on the patterns selected. This makes it possible to reverse the learning process and extract the most predictive features of malware in PowerShell scripts. This is also helpful in terms of debugging the network and checking to determine if it is looking at the right features when making decisions.Convolutional Neural Networks (CNNs)
Background
CNNs have been applied in the vision area for a long time, but only with very good results in recent years, as more data and computational power has become available. One of the most important properties of these networks is that they operate on raw input and remove the need for feature engineering — i.e., the process whereby a human expert expresses the raw data in a form useful for ML.The principle behind a CNN is the application of a set of kernels over different regions of the input image — learning from low-level features (edges, blobs, colors) in earlier layers, to more complex compositions of those features in the upcoming layers. On the efficiency side, applying the same kernel over different regions of the input is equivalent to recycling the respective weights. This gives a smaller number of parameters that need to be learned for CNNs, compared to dense neural networks.
CNNs in Natural Language Processing
In natural language processing (NLP), CNNs are applied on words or patterns. More recent applications use information at the character level, which has the advantage of not requiring syntactic knowledge of the language. Currently, a variety of tasks (sentiment analysis, dialect identification, etc.) benefit from the touch of CNNs. Malware research is included in the list of domains where charCNNs have previously been used with good results. For example, in a charCNN for detecting malicious URLs, file paths and registry keys are presented.The CharCNN behind Kestrel
For Kestrel, we had one main research objective: to detect malware in PowerShell scripts. Furthermore, we knew the means to achieve this: using a CNN that operates on raw input signals under the form of characters. Some background and intuition on the proposed technique has been given, and we can now proceed to a more detailed view of the subject, including insights from the experimental setup and architecture of the charCNN behind Kestrel — our ML-powered classifier for PowerShell scripts.Input
The data used in the Kestrel model consists of a sequence of characters encoded using their position in the alphabet. Initially, we are considering 96 possible characters (lowercase and uppercase letters, digits and special characters):ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 0123456789 -,;.!?:’’’/\|_@#$%ˆ&*˜‘+-=<>()<>{}
The alphabet is augmented with the new characters discovered in the training set. This makes sense especially when dealing with malicious files, because their content might include characters not usually found in a PowerShell script. For example, Chinese characters are a common example of new features that have appeared in the training alphabet. Overall, the alphabet obtained after the augmentation is a little under 5,000 characters. The number of distinct input features is the alphabet size. Regarding the input feature length, we decided that 5,000 characters is a good number that captures most of the texts of interest, and it has also performed the best in the parameter-tuning phase.Learning character embeddings
Right after the input layer, we use an embedding layer with the aim of representing the indexes used for characters as continuous vectors that are more meaningful in terms of the categories they represent. Therefore, our computational flow starts with embedding the sequence of characters considered for each sample into a 5,000 x 128 floating point matrix. Each character is mapped into a 128-dimensional embedding space. These representations are optimized throughout the learning process in the CNN. The aim is to capture more meaning in the spatial representation of features, bringing characters with similar attributes closer to each other: lowercase letters, uppercase letters, digits, etc.In order to validate the embeddings learned for the characters found in the PowerShell corpus, we are using t-SNE. In other words, we are performing dimensionality reduction while still keeping the relative pairwise distance between points that are not similar. Therefore, the vectors of length 128 obtained in the embedding layer are mapped into two dimensions (2D). After that, a simple clustering method (k-means) is applied on the 2D points in order to see how the characters group together.
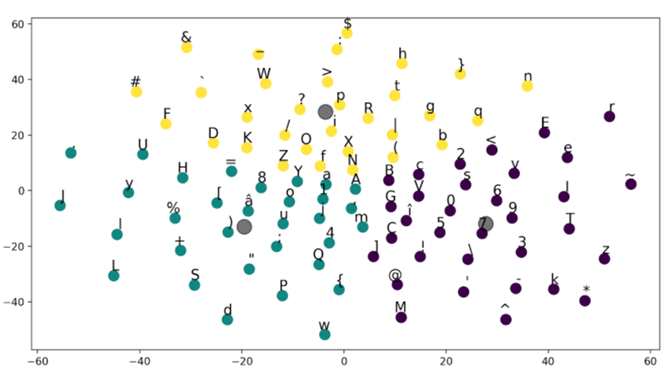 Figure 1. k-means clustering of the first 120 characters used as features in the charCNN described in this article
Figure 1. k-means clustering of the first 120 characters used as features in the charCNN described in this articleOne might also notice that not all of the characters in the alphabet described above are considered in the plot. The rationale behind this decision is that with the increase in the number of data points, it is becoming more difficult to make an easy-to-read t-SNE plot. Therefore, we have decided to only take the first 120 characters in the alphabet for this visualization.
It is worth mentioning that in general, these embeddings are not interesting by themselves. This is why they are learned in an embedding layer that is connected to the input layer and also to the first convolutional module in the charCNN chosen to back Kestrel. Our charCNN embeddings are just a means to an end, as they tailor the model to the PowerShell training set. For implementing the charCNN described here, we used Keras with the Tensorflow backend. One interesting detail is that the same architecture yields completely different results with Pytorch. The only reasonable explanation for this is that we are relying on some magic that happens in the Keras embedding layer and does not apply when working with Pytorch. This is a known problem. A workaround in overcoming this drawback is to plug the weight matrix obtained while training the Keras embeddings into the Pytorch embedding layer.
Model Design
So far, the topics of the inputs and their embeddings have been treated separately due to their particularities and importance in the learning process. However, they are the significant entry points into the model presented below. It is needless to mention how crucial this clustering of semantically similar characters is in helping the lower layers identify semantically similar patterns in the string.Now, we will talk about the architecture of the model, which is similar to the one presented in the original charCNN paper and also inspired by the insights provided in a paper in which a similar CNN is applied successfully in the dialect identification area.
Among the main modules of a charCNN, we enumerate the temporal 1D convolutional module, which computes the convolution:
 In each convolutional module, we are using more kernel functions, f, which essentially represent the weights in those layers, with g as the input features. Each kernel looks for a different pattern in the input, resulting in many functions, h — the output features passed forward by the current module.
In each convolutional module, we are using more kernel functions, f, which essentially represent the weights in those layers, with g as the input features. Each kernel looks for a different pattern in the input, resulting in many functions, h — the output features passed forward by the current module.The temporal 1D max pooling allows us to train deeper models through the selection of only the relevant feature maps retrieved from the convolutional modules (the patterns that matter for our use case):
 The non-linearities of the model are introduced using the rectifier/thresholding function:
The non-linearities of the model are introduced using the rectifier/thresholding function:
![]()
Results
The results obtained in the research phase are promising. From an average of 1.5% false positives (FPs) in the tests run at a 0.5 threshold, the proposed method decreases the FP rate to an average of 0.9% with an increase of only 0.3% in false negatives (FNs) when the threshold increases to 0.9. Furthermore, a threshold of 0.99 yields 0.5% FPs with the trade-off of having 6% FNs. Going up to 0.999 as the decision threshold gives one false detection of malware in 1,000 samples, and we are still able to correctly detect more than 80% of the malware files in these conditions.
The results presented above represent the average values of the respective metrics obtained in the tests performed in the experimental phase, with limited data. We expect to see improvements in the upcoming version of the model with the new data that becomes available for re-training purposes.
Conclusion
In this article, we have introduced a specific use case for malware detection where we target PowerShell scripts as the tool used by potential attackers. Our approach uses a CNN that operates at the character level on the contents of the scripts executed on users’ machines. The technique used and its preliminary results, after being trained on relatively modest amounts of data, have also been discussed in this post. Are you an expert in designing large-scale distributed systems? The CrowdStrike Engineering team wants to hear from you! Check out the openings on our career page.Additional Resources
- Learn more about the CrowdStrike Falcon®® platform by visiting the product webpage.
- Learn more about CrowdStrike endpoint detection and response by visiting the Falcon InsightTM webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.

