What is machine learning?
Machine learning (ML) is a subset of artificial intelligence (AI), and refers to the process of teaching algorithms to learn patterns from existing data in order to predict answers on new data.
Although the terms AI and ML are often used interchangeably, there are important differences between the two concepts. AI refers to technology that trains machines to imitate or simulate human intelligence processes in real-world environments, while ML refers to the resulting computer systems (“models”) that learn from data to make predictions.
In essence, “learning” refers to the process in which models map mathematical functions to transform underlying data in order to make accurate predictions. Whereas computers can be programmed to perform simple, predictable tasks by following explicitly programmed or chained instructions, ML models develop a generalized approach to solving problems.
3 types of machine learning
In this article, we’ll review three common classes of machine learning:
1. Supervised learning
Supervised learning occurs when a model is trained on labeled inputs and desired outcomes, where the aim is to teach it to perform a task when presented with new or unfamiliar data. Within cybersecurity, one common application of supervised learning is training models on benign and malicious samples to teach them to predict whether new samples are malicious.
2. Unsupervised learning
Unsupervised learning occurs when a model is trained on unlabeled data and is left to find structure, relationships and patterns in the data, such as clusters or groupings. In cybersecurity, this can be used for uncovering new attack patterns or adversary behaviors (e.g., anomaly detection) in large pools of data.
3. Reinforcement learning
Reinforcement learning occurs when a model is not given labeled inputs or outputs and instead learns through trial and error, aiming to maximize a cumulative reward. This form of machine learning closely mimics how human learning occurs and is especially useful for identifying creative and innovative ways of solving problems. Some applications of reinforcement learning in cybersecurity include solutions for cyber-physical systems, autonomous intrusion detections and distributed denial of service (DDOS) attacks.
Benefits of machine learning in cybersecurity
There are many benefits to applying machine learning to problems in the cybersecurity space. These include:
1. Rapidly synthesize large volumes of data: One of the biggest challenges faced by analysts is the need to rapidly synthesize intelligence generated across their attack surface, which is typically generated much faster than their teams can manually process. Machine learning is able to quickly analyze large volumes of historical and dynamic intelligence, enabling teams to operationalize data from various sources in near real-time.
2. Activate expert intelligence at scale: Regular training cycles enable models to continuously learn from their evolving sample population, which includes analyst-labeled detections or analyst-reviewed alerts. This prevents recurring false positives and enables models to learn and enforce expert-generated ground truth.
3. Automate repetitive, manual tasks: Applying machine learning to specific tasks can help alleviate security teams from mundane, repetitive tasks, acting as a force-multiplier that enables them to scale their response to incoming alerts and redirect time and resources toward complex, strategic projects.
4. Augment analyst efficiency: Machine learning can augment analyst insight with real-time, up-to-date intelligence, enabling analysts across threat hunting and security operations to effectively prioritize resources to address their organization’s critical vulnerabilities and investigate time-sensitive ML-alerted detections.
Use cases of machine learning in cybersecurity
Machine learning has a broad, ever-growing range of use cases in the cybersecurity space. We can think of these use cases as falling into two main groups:
- Automated threat detection and response
- Analyst-led operations assisted by machine learning
Autonomous threat detection and response
In the first category, machine learning enables organizations to automate manual work, especially in processes where it is critical to maintain high levels of accuracy and to respond with machine-level speed - such as automatic threat detection and response, or classifying new adversary patterns.
Applying machine learning in these scenarios augments signature-based methods of threat detection with a generalized approach that learns the differences between benign and malicious samples and can rapidly detect new in-the-wild threats.
Driving analyst efficiency with machine learning
Machine learning models can also assist in analyst-led investigations by alerting teams to investigate detections or by providing prioritized vulnerabilities for patching. Analyst review can be especially valuable in scenarios where there is insufficient data for models to predict outcomes with high degrees of confidence or to investigate benign-appearing behavior that may go unalerted by malware classifiers.
Additional machine learning cybersecurity use cases
Below is a list of common examples (not exhaustive) of ways machine learning can be used in the cybersecurity space.
| Use Case | Description |
|---|---|
| Vulnerability Management | Provides recommended vulnerability prioritization based on criticality for IT and security teams |
| Static File Analysis | Enables threat prevention by predicting file maliciousness based on a file’s features |
| Behavioral Analysis | Analyzes adversary behavior at runtime to model and predict attack patterns across the cyber kill chain |
| Static & Behavioral Hybrid Analysis | Composes static file analysis and behavioral analysis to provide advanced threat detection |
| Anomaly Detection | Identifies anomalies in data to inform risk scoring and to direct threat investigations |
| Forensic Analysis | Runs counterintelligence to analyze attack progression and identify system vulnerabilities |
| Sandbox Malware Analysis | Analyzes code samples in isolated, safe environments to identify and classify malicious behavior, as well as map them to known adversaries |
Evaluating the efficacy of machine models
Model efficacy for malware classifiers:
One of the most common applications of ML in cybersecurity is malware classification. Malware classifiers output a scored prediction on whether a given sample is malicious; with “scored” referring to the confidence level associated with the resulting classification. One way we assess the performance of these models is by representing predictions along two axes: accuracy (whether an outcome was correctly classified; “true” or “false”), and output (the class a model assigns to a sample; “positive” or “negative”).
Note that the terms “positive” and “negative” in this framework do not mean that a sample is respectively “benign” or “malicious.” If a malware classifier makes a “positive” detection, this indicates that the model is predicting that a given sample is malicious, based on observing features that it has learned to associate with known malicious samples.
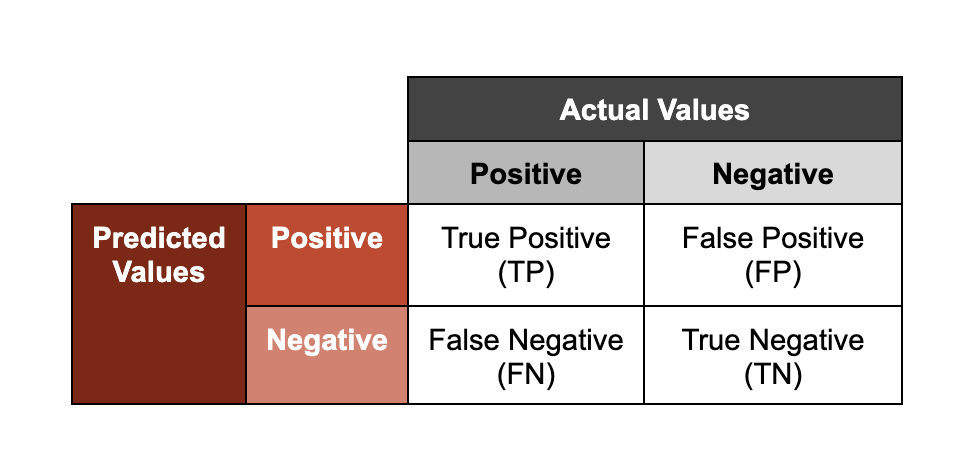
To illustrate what these groupings mean, we’ll use the example of models trained to analyze malicious files.
- True Positive: The model correctly predicted a file was malicious
- True Negative: The model correctly predicted that a file was not malicious
- False Positive: The model incorrectly predicted that a file was malicious (and it wasn’t)
- False Negative: The model incorrectly predicted that a file wasn’t malicious (and it was)
Balancing true and false positives
Although true positives are essential for threat detection and response, false positives are also an important measure of model performance. False positives have an opportunity cost associated with the time and resources security teams spend investigating each detection, and can be especially costly if they trigger automatic remediation processes that block or interrupt applications that are critical for an organization’s operations.
When calibrating model aggressiveness or sensitivity, data scientists must optimize for both true positive and false positive rates, facing a critical tradeoff: lowering the threshold for true positives (that is to say, the requirements that need to be met for a model to classify a sample as “positive”) comes with the risk of also lowering the threshold for false positives (which could result in lost analyst productivity and aggravate alert fatigue). We refer to this tradeoff as detection efficacy.
The ultimate goal of building high-performing machine learning models is to maximize detection efficacy: maximizing true positive detections while minimizing false positives. To illustrate the complexity of this balance, consider that it is not uncommon for malware classifiers to have true positive rates at or near 99%, balanced against false positive rates well below 1%.
Challenges & constraints of machine learning
While machine learning models can be powerful tools, every model operates under unique limitations:
Sufficient high-quality data: Training high-confidence models often requires access to large data sets, both to train and to test machine learning models. To test models, a subset of the data is typically set aside from the training set to test model performance. This data should have minimal feature overlap with the training data; for instance, representing a different timespan of data collection or emanating from a different data source. If there is insufficient high-quality data, a given problem space might not be a suitable scenario for applied machine learning.
Tradeoffs between true and false positives: As discussed earlier, each model’s sensitivity needs to be calibrated to balance the threshold of detection between true and false positives to maximize detection efficacy.
Explainability: Explainability refers to the ability to explain how and why a model performs as it does. This enables data science teams to understand what features in a sample influence the model’s performance and their relative weights. Explainability is critical for driving accountability, building trust, ensuring compliance with data policies and ultimately, enabling continuous performance improvement in machine learning.
Repeatability: Also known as reproducibility, this refers to the ability of machine learning experiments to be consistently reproduced. Repeatability drives transparency around how machine learning is used, what types of models are used, what data they are trained on and what software environments or versions they operate in. Repeatability minimizes ambiguity and potential errors as models move from testing to deployment and through future update cycles.
Optimization for target environment: Each model must be optimized for their target production environment. Each environment will vary in its availability of computational resources, memory and connectivity. Subsequently, each model should be designed to perform in its deployment environment, without burdening or interrupting operations of the target host.
Hardening against adversarial attacks: Machine learning models have their own attack surface that can be vulnerable to adversary attacks, where adversaries may try to exploit or modify model behavior (such as causing the model to misclassify samples). To minimize the exploitable attack surface of models, data scientists “harden” models in training to ensure robust performance and resilience against attacks.
2 Misconceptions about machine learning
Misconception #1: Machine learning is better than conventional analytical or statistical methods.
Although machine learning can be a highly effective tool, it may not be suitable for use across every problem space. Other analytics or statistical methods may produce highly accurate and effective results or may be less resource-intensive than a machine learning approach, and be the more suited approach for a given problem space.
Misconception #2: Machine learning should be used to automate as many tasks as possible
Machine learning can be very resource intensive, often requiring access to large quantities of data, computational resources and dedicated data science teams to build, train and maintain models. To maximize the ROI of maintaining models, it is best applied when target problems are high-value, frequently recurring, require speed and accuracy and have sufficient high-quality data sets for ongoing training and testing.
CrowdStrike’s approach to machine learning
CrowdStrike applies machine learning across the CrowdStrike Falcon® platform to deliver advanced threat protection.
Unparalleled intelligence of the CrowdStrike Security Cloud:
CrowdStrike’s models are trained on the rich telemetry of the CrowdStrike Security Cloud, which correlates trillions of data points across CrowdStrike’s asset graph, intel graph and patented Threat Graph® to deliver unparalleled visibility and perpetually refining threat intelligence across an organization’s attack surface.
Enriching this knowledge is an ever-expanding corpus of ground truth generated by expert teams across CrowdStrike, including CrowdStrike’s threat hunting teams (Falcon OverWatch™), Malware Research Center and Managed Detection and Response teams (Falcon Complete™).
Augmenting human expertise:
CrowdStrike’s models fuel autonomous threat detection and response while also augmenting human expertise in expert-led domains, such as threat hunting and IT and security operations. Machine learning models across the Falcon platform operate to deliver a next-generation analyst workbench that automates detection and response, maximizes analyst efficiency with high-fidelity machine learning-alerted detections, and provides intelligent vulnerability management recommendations for proactive defense (with the ExPRT.AI model of Falcon Spotlight™).
Multiple layers of defense:
CrowdStrike applies machine learning throughout the Falcon platform to offer a robust, multi-layered defense across the process lifecycle (pre-execution, runtime and post-execution). Pre-execution, on-sensor and cloud-based machine learning models operate synchronously to automatically detect and respond to threats, equipping the lightweight Falcon agent with a robust first line of defense. The constant synchronicity between cloud and on sensor machine learning models enables detections made on-sensor to be globally enforced across an attack surface and, similarly, enables detections made by cloud-based models to be instantly enforced across all protected endpoints.
To augment this approach, CrowdStrike also applies advanced behavioral analysis at runtime, using cloud-based models to analyze endpoint events to classify indicators of attack (IOAs). AI-powered IOAs proactively detect emerging threats regardless of malware or tools used and operate asynchronously to on-sensor models to trigger local analysis of suspicious behavior based on real-time threat intelligence.
Post-execution, behavioral indicators are used to assess anomalous activity across an organization's attack surface (as indicated by the CrowdStrike CrowdScore™ metric, which provides a real-time indication of an organization’s threat level), and are also used by Falcon OverWatch to investigate advanced threats, such as hands-on-keyboard activity, ecrime and stealthy attacks.
Learn More
Learn how CrowdStrike combines the power of the cloud with cutting-edge technologies like TensorFlow and Rust to make model training hundreds of times faster.
Lucia Stanham is a product marketing manager at CrowdStrike with a focus on endpoint protection (EDR/XDR) and AI in cybersecurity. She has been at CrowdStrike since June 2022.
