





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































- Suspicious command lines differ from common ones in how the executable path looks and the unusual arguments passed to them
- Bidirectional Encoder Representations from Transformers (BERT) embeddings can successfully be used for feature extraction for command lines
- Outlier detectors on top of BERT embeddings can detect anomalous command lines without the need for data labeling
- Our BERT model assists detection in an unsupervised fashion, strengthening the protection of the CrowdStrike Falcon® platform
In our experiments, we use a pre-trained BERT model for the feature extraction step — a strategy for generating command line embeddings that wasn’t previously used in the literature. We compare a variety of anomaly detection algorithms, including principal component analysis (PCA), Isolation Forest (iForests), Copula-based Outlier Detection (COPOD), autoencoders (AE, pp. 237-263) and an ensemble of all of these algorithms. Most of these algorithms are implemented in the open-source PyOD library, which we also use in our implementation.
Approach
Input
The data used for the anomaly detection model consists mainly of Windows command lines extracted from our telemetry. The command lines have the structure illustrated in Figure 1. Figure 1. Windows command lines structure for firewall events
Figure 1. Windows command lines structure for firewall events
Learning Command Line Embeddings
The command lines might have different outcomes depending on the order of the tokens and the context in which they are used. We decided to learn a data representation from unlabeled command lines by pretraining a BERT model to better capture this diversity of outcomes. The first step in training BERT from scratch is having a command-line tokenizer. We trained a WordPiece tokenizer on over 45 million command lines to achieve this. Figure 2 shows an example of a tokenized command line.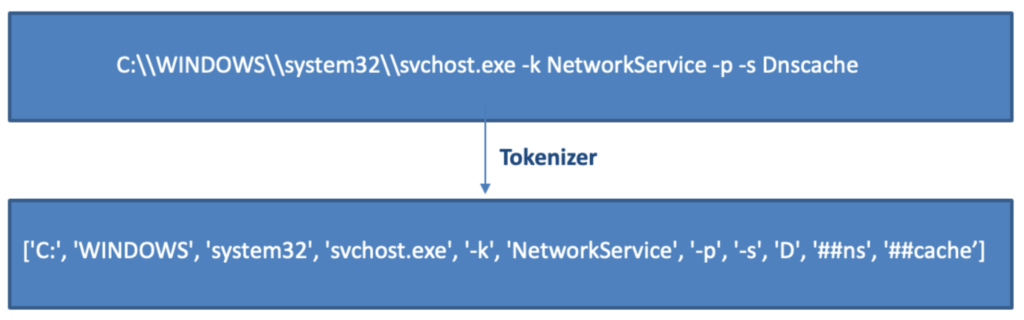 Figure 2. Example of a tokenized command line
Figure 2. Example of a tokenized command lineThe obtained model has a hidden size of 768, and it was trained on 1.5 million command lines extracted from CrowdStrike’s event data. After the pre-training stage, the BERT model is used as a feature extraction tool for command lines.
Detecting Anomalies
Detection time is a concern. Thus, on top of the contextualized embeddings, we use a few different outlier detection models with low computational overhead. In Figure 3, we show the general architecture of the anomaly detection pipeline. Out of the anomaly detectors tested, the ones listed below performed best and were the most computationally effective for our extensive high-dimensional data set:- PCA: Computes the outlier score as the sum of the projected distance of a sample on all eigenvectors. In our experiments, we use PCA to reduce the number of features by 90%.
- COPOD: A parameter-free model that estimates tail probabilities using empirical copula.
- Isolation Forest: “Isolates” observations by randomly selecting a split value from the range of values of a feature. The outlier score is equal to the number of splits required to isolate a sample. An outlier will require fewer splits until it is isolated from the rest of the data.
- Autoencoder: A deep learning model used in our experiments to detect outliers, by reducing the feature space and then computing the reconstruction errors.
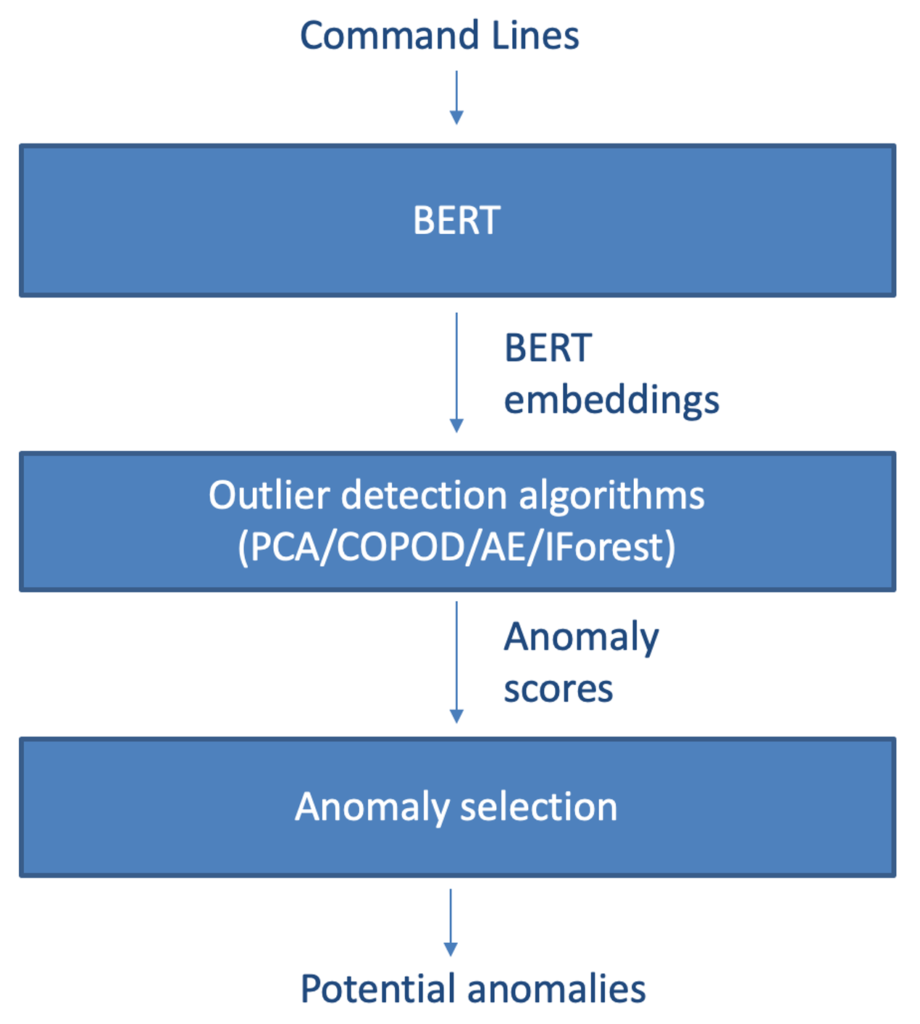 Figure 3. The general architecture of the anomaly detection model
Figure 3. The general architecture of the anomaly detection model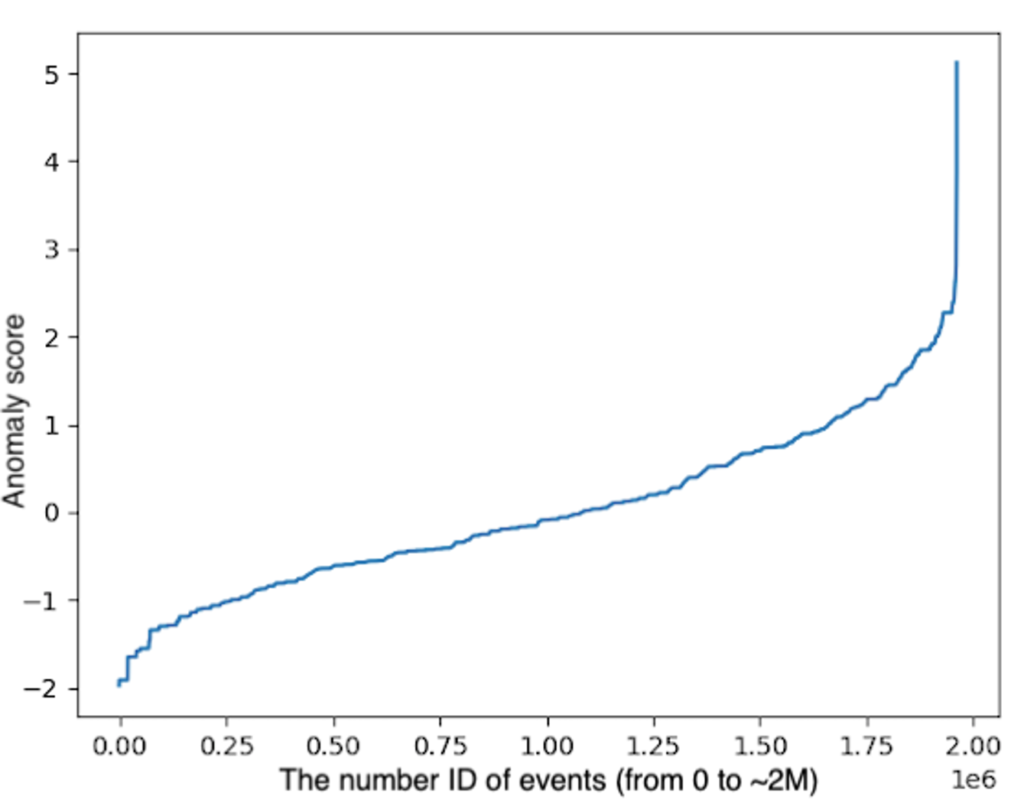 Figure 4. Distribution of the anomaly scores in our experiments
Figure 4. Distribution of the anomaly scores in our experimentsAnalysis
Comparing various outlier models proved to be a difficult task, as we do not have a specific metric for the unsupervised setup. To better understand how the anomalies are selected, we created a visual representation of the dataset. To this end, we use PCA to reduce the feature space from 768 to two components, and we select the first 250 distinct command lines with the highest anomaly score. It is worth mentioning that not all of the marked command lines are anomalies, rather only outliers. The right-hand plot in Figure 5 displays in red the anomalies detected by iForest. The iForest algorithm differs the most from the other models because it identifies anomalies with a very low occurrence rate.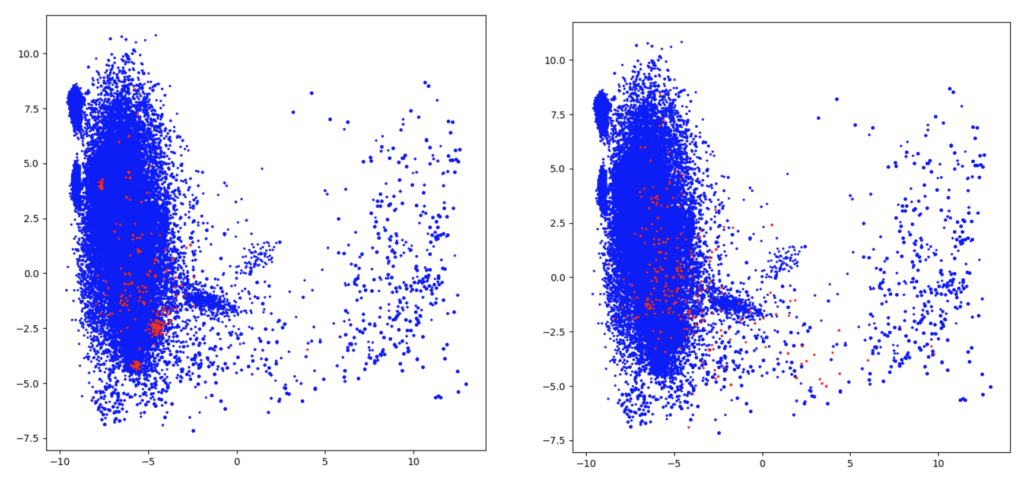 Figure 5. In red, the anomalies detected by COPOD (left) and the anomalies detected by iForest (right)
Figure 5. In red, the anomalies detected by COPOD (left) and the anomalies detected by iForest (right)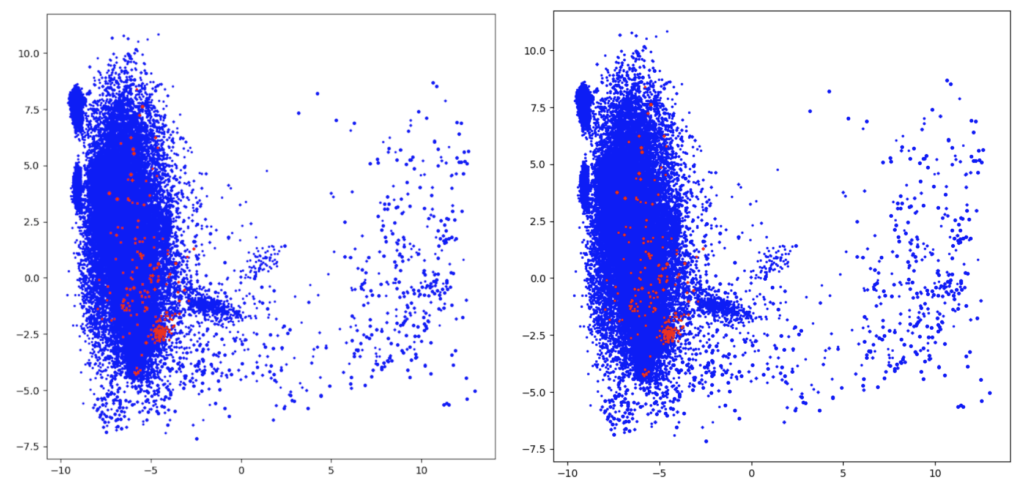 Figure 6. In red, the anomalies identified by PCA (left) and the anomalies detected by the AE model (right)
Figure 6. In red, the anomalies identified by PCA (left) and the anomalies detected by the AE model (right)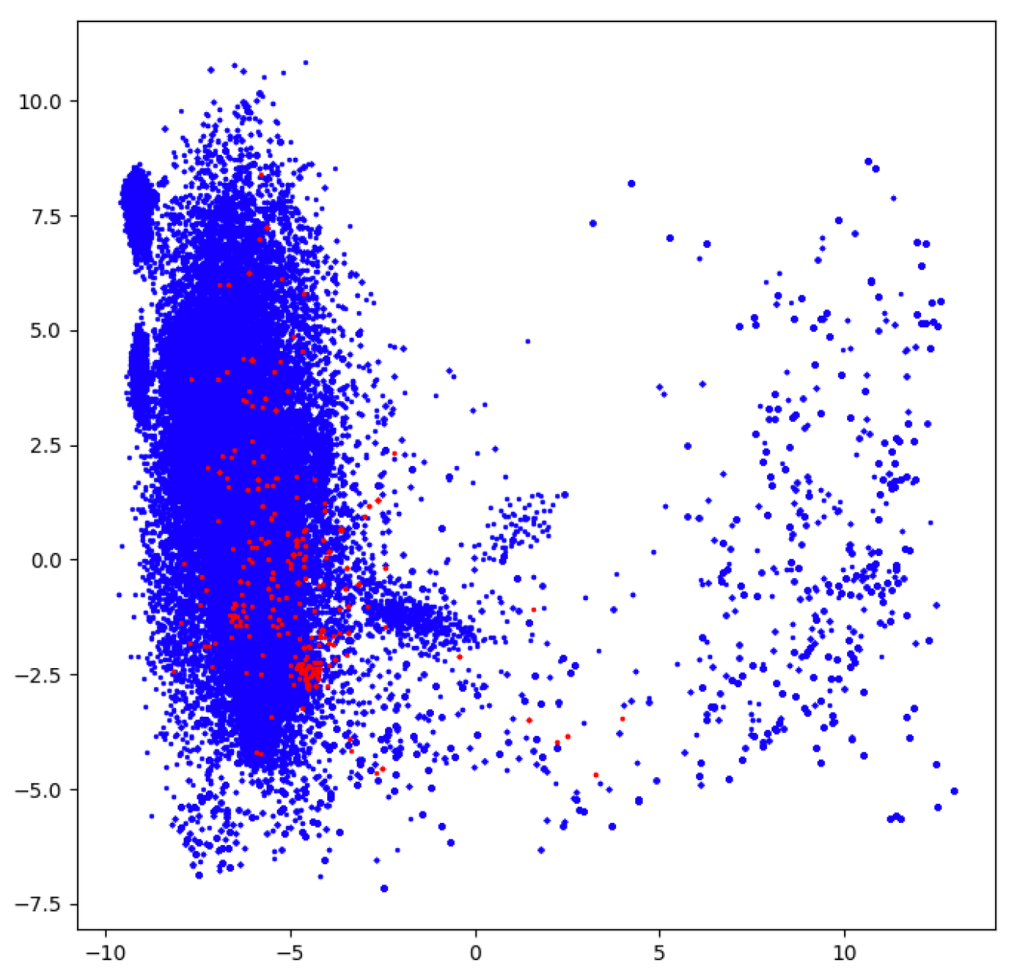 Figure 7. In red, the anomalies detected by the ensemble of PCA, iForest, COPOD and AE. This model is the most consistent as it combines multiple strategies of outlier detection.
Figure 7. In red, the anomalies detected by the ensemble of PCA, iForest, COPOD and AE. This model is the most consistent as it combines multiple strategies of outlier detection.We should mention that we considered only the first 250 distinct command lines with the highest outlier score as anomalies for these measurements. To motivate the rationale behind the ensemble model, let’s suppose that an anomaly x is ranked 300 by one of the models considered and 100 by another one. This is expected, as each model tackles the outlier detection problem differently. The ensemble model averages the scores of each outlier detector to provide a robust prediction. The neural network approach (AE) and PCA perform best out of the four standalone models. While PCA has lower training times than COPOD, AE and iForest, the autoencoder architecture is much more powerful than PCA because it employs non-linear transformations. The ensemble model combines the above four strategies to improve the individual performance of the anomaly detectors, albeit at the cost of having a slower processing time. We evaluate the results obtained in the research phase as promising, provided that the model detects commands that are different, to some extent, from the ones that we are regularly seeing in our telemetry. For example, it identifies incomplete command lines inconsistent with the format explained in the approach section (i.e., potential misconfigurations).
 Figure 8. Examples of anomalies detected. Some of the words in the command
Figure 8. Examples of anomalies detected. Some of the words in the commandlines were replaced with <$USER> and <$SHA1> due to client confidentiality.
Takeaways
The goal of this exercise was to describe a novel approach for using BERT models to detect anomalous command-line executions. We first pre-trained our BERT model in house using targeted command lines from firewall events, benefiting from a large set of unlabelled telemetry data. The BERT model is subsequently used to perform feature extraction on new samples, and the resulting command line embeddings are fed to a series of anomaly detectors. Finally, we compared the performance of the dedicated algorithms for outlier detection and discussed our modeling decisions, concluding that BERT embeddings can successfully be used for command-line feature extraction and as input for anomaly detection models. This model assists detection in an unsupervised fashion by filtering suspicious command lines from large amounts of events. Thus, the experiments conducted in this research help strengthen the protection of the CrowdStrike Falcon® platform.Additional Resources
- Learn more about the CrowdStrike Falcon® platform by visiting the product webpage.
- Learn more about CrowdStrike endpoint detection and response on the Falcon Insight webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.