





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)






































- CrowdStrike data scientists describe a new similarity paradigm to organize information and make it accessible, searchable and mappable
- The new similarity-based mapping of cybersecurity data associates disparate representations of various objects important for cybersecurity, providing scientists and analysts with the tools necessary to prevent and respond to breaches more effectively
The CrowdStrike Falcon® platform harnesses massive amounts of data, collected from trillions of events that are routinely captured on a daily basis. This data must be organized in a way that facilitates the confluence of disparate representations before the inherent value of that data can be realized.
Cybersecurity data consists not only of files, event data, behavioral sequence data, network traffic, etc., but also the representations thereof. The leveraging of this data is currently task-specific, i.e., collections of objects and their representations are siloed according to use case. For example, files are parsed in terms of both static features and event sequence data; the former representation is for use in training static classifiers and the latter in training time series-based classifiers. This separation of representation is necessary to quickly develop and train classifiers, but presents a major risk moving forward as attacks become more multifaceted and complex.
The key to understanding cybersecurity data and leveraging its true value to prevent breaches is similarity, both within fixed representations and across disparate representations.
This post describes a new paradigm for how we must think about similarity and the long-term goals that emanate from this new paradigm. At a high level, similarity should be thought of as a route to organizing information and making it accessible, searchable and mappable. The creation of a mapping that associates disparate representations of various objects important for cybersecurity will provide scientists and analysts the tools to prevent and respond to breaches more effectively. The realization of this map, or set thereof, could take the form of visualizations, searchable tabular databases, graph databases, vector databases or universal embeddings, and in all cases should be the result of solving a well-posed optimization problem.
Consider for a moment a topographical map of the United States, which represents mountains, highways and state lines and is perhaps color-coded for vegetation, waterways and average rainfall. An economist may, strictly from intercity trade statistics, make an inference about geography or infrastructure, but it is the map that immediately reveals the truth of that inference. Our goal as cybersecurity researchers and scientists should be the construction of such a map for cybersecurity data.
Defining Similarity
Similarity is the area of study that quantifies the extent to which objects of interest are related. In cybersecurity, these objects include executable files, behavioral sequence data, documents, scripts, logs, critical assets, networks and network traffic. To make certain abstract topics more concrete, we focus on executable files and their various representations in this post.
Because the quantification of similarity is ultimately a mathematical endeavor, we adopt the convention that two objects are similar if they are close in some embedding space V. By “similarity measure” we mean a function
D:V x V → R≥0
that associates to each pair of objects (v,w) a real number D (v,w) such that
D(v,w)<D(v',w')
if v and w are more similar to each other than v'and w'are to each other.
Why Similarity Is Important in Cybersecurity
Consider the following concrete use cases:
- Given a false positive or false negative, remediation requires finding similar samples that contain features on which the model is overfitting.
- Parasitic file infector remediation requires querying for true negatives near a given false negative.
- Given a set of samples on which the model is misclassifying, a similarity-based querying tool facilitates discovery of similar samples that can be upweighted in training.
- Similarity allows for the curation of training and test sets in more sophisticated and useful ways than randomly splitting the corpus.
- Given samples representative of several subfamilies, query for more samples from each subfamily to obtain a corpus consisting of subfamilies in specified proportions, which may be those observed in the wild across customers.
- Given a similarity threshold, one can prevent information leak between training and test sets, which improves models by preventing a false sense of performance. By “information leak” we mean the presence of files in the disjoint training and test sets, the similarity of which is beyond a given threshold (i.e., the files are nearly identical).
- Facilitate online clustering for the sake of creating high-trust labels for use downstream in training a new machine learning model.
While each of the above examples leverages a homogeneous storage scheme along with a querying capability, the true value of similarity is in the construction of a map that coalesces disparate object representations.
Before making this notion comprehensible and concrete, we must gain a deeper understanding of the objects of interest, their various representations, and how to measure similarity among and between these representations.
Similarity, Classification and Models
How an object is mapped to the representation of that object defines an implicit paradigm when comparing objects via the given representation.
One of our primary interests in cybersecurity is in classifying objects (files, behaviors, system states, etc.) as either benign or malicious. This task is accomplished at scale by leveraging a parser along with a machine learning classifier, the latter of which we typically term a “model.” Referring to the model as a model of malware is misleading in the following sense: A model is a representation of a system or object in a form that facilitates the study of that system or object. More appropriate would be to refer to the parser itself as the file model, and to what we term the model as a scoring function. When we study files, our primary concern is file execution, and it is the choice of parser that determines the modeling paradigm. A file can be parsed — that is, “modeled” — in many different ways. These include byte sequences, static feature vectorization, detonation (event time series data) and disassembly, which can comprise both sequence and graph data.
Each of these methods models the file from a different point of view, but all serve as proxies for file behavior at runtime in the wild.
Nature of the Model (Parser)
Understanding the above distinction between the file model and the scoring function is critical for several reasons. If, for example, the parser is too coarse, the parser may map very different files to the same point in feature space. This may not present a problem for the scoring function because the collided files may have the same label, but it presents a major obstruction to studying similarity. On the other hand, if the parser is too fine, semantically identical versions of a fixed file may be mapped to disparate regions of feature space, which also obstructs the study of similarity — but in a different way. As in the previous example, this may not present a problem for the scoring function, as long as the scoring function has a sufficient number of parameters to adapt to the higher-variance embedding.
An important thing to note is that the parser itself does not know which features are important for classification. The scoring function, through training, is how features that are useless for classification are filtered out in favor of valuable features. There is no such analog when computing similarity on a feature space designed for use in classification. While it is true that parsers are engineered in part to describe a given file’s characteristics in a label-agnostic way, the reality is that many of those features are indicators of maliciousness and are not suitable for measuring label-agnostic similarity. To truly statically model files for the sake of measuring similarity, the parser itself must be optimized for this task. This can be done in a variety of ways, but the point is that the engineering of the parser must be, as with classification via a scoring function, viewed as an optimization problem.
In the absence of expert advice, quantification of similarity for a column of a given dataset can only be performed by considering the distribution of the values contained in that column. We infer the meaning of closeness for that column from the nature of the density over the sample space as well as near the considered points. Specifically, we may want to define D(a,b) as a function of P(a≤x≤b) rather than |a-b| for a,b — two values in the considered column. We also must ensure that columns exist on the same scale, which is typically addressed through some sort of linear rescaling, quantile bucketing, or through the application of a monotonic function like natural log. Selecting and implementing these transformations in an algorithmic way is a necessary tradeoff we must accept when the dimensionality of the feature space exceeds the number of transformations that can be engineered by hand. However, these transformations do not represent a complete solution. For example, being within one percentile of normalized file size may mean something very different than being within one percentile of normalized entropy.
Another challenge is that the similarity function itself may be local in nature, meaning the way we compute similarity depends on where in feature space the similarity function is being applied. Consider the following idealized situation: Let f,g denote two files, and let
u=(u1,u2,...,un), v=(v1,v2,...,vn)
denote their respective featurizations. Assume we have a metric D defined on feature space. Now perturb f to f' and g to g' in such a way that their new vectorizations are given by replacing u1 by u1= u'1+r and v1 by v'1= v'1+r.
These perturbations have resulted in sliding the pair (u,v) along the first axis to arrive at the pair (u',v'). While it remains true that ||u-v|| =||u'-v'||, it may not be what we actually want. It may not adequately quantify our knowledge of the difference in similarity between the pair (f,g) as opposed to the pair (f',g'). For example, the perturbation may have been the addition of a specific malicious action that renders the perturbations far more similar than indicated by the vector similarity between u’ and v’. The application of Riemannian geometry to measuring similarity on tabular data is beyond the scope of this piece but is an area of active research.
One must also take care to embed categorical features in a way that respects the absence of the ordering of the values of the categorical variable. The embedding must be constructed in a way that uniformizes pairwise distances between the values. This is key because if a single pair of categorical values is closer in the embedding space than other pairs, the corresponding samples could be closer than is semantically optimal under the chosen metric.
For these reasons, the representation itself should be obtained via an optimization problem in which the loss function is solely informed by the utility of the embedding for similarity. One could accomplish this by training an embedding on the sequence of raw bytes, where the loss function would be constructed by measuring the distance between pairs in this space and comparing to something like a Jaccard distance on bytes.
Constructing a Map of Cybersecurity Data
The challenges when constructing a map of cybersecurity data fall into two distinct categories. The first category consists of the difficulties in measuring the similarity between objects when the nature of the parser is fixed, which were discussed in detail above. The parser defines the paradigm within which the analyst studies the given set of objects. One might also take a different point of view by parsing the same set of files via disassembly, detonation, byte sequences, etc. The second category consists of constructing mappings across paradigms, which we term “cross-paradigm inference.”
Mapping across paradigms is difficult not because the associated optimization problems are infeasible, but because it is unclear what should be optimized. The mapping optimization problem can be split into three distinct subproblems:
- The learning of a faithful representation of files for each of our defined points of view.
- A way of quantifying the similarity between the representations across files for a fixed point of view.
- A way of mapping between disparate representations.
For example, imagine we have the ability to represent a given file via a static feature vectorization and as a representation in terms of behavioral sequence data. If we had a mapping between these two representations, then we would have the ability to query across paradigms. A simple use case is as follows: We observe a malicious sequence of events on a customer machine or network, map the behavioral sequence representation to a feature vector via the cross-paradigm map, and query for nearest neighbors so that these hashes can be blocklisted.
Consider the following two constructions that could serve as initial steps toward the realization of a map of cybersecurity data:
- Construct a table, the rows of which are indexed by file hashes and the columns indexed by cluster IDs resulting from clustering different representations of the same files. Cross-paradigm inference in this case would be as simple as choosing a SHA-256, performing a cluster ID lookup for a given column and then indexing into other columns to find hashes associated with the query hash for a variety of disparate representations.
- Analysts have the ability to marginalize — i.e., aggregate over unimportant details of a given file to arrive at a humanly understandable behavioral description. The development of a tool in the form of a neural network, which consumes static feature vectors and outputs descriptive tags, would allow scientists and analysts to study feature vectors from the same high-level point of view without needing access to the original binary. Unoccupied regions of feature space could also be similarly explored and described.
Hypothetical Case Study: Sality (Parasitic File Infector)
Malware Feature Summary
- Infects Microsoft systems.
- Communicates over peer-to-peer networks to form a botnet (i.e., a network of computers, each running a bot) for spam, proxying communications, exfiltrating sensitive data, compromising web servers and coordinating distributed computing tasks.
- Incorporates rootkit functions, which can give root access to an attacker or malicious program.
Behavioral Description
- Is polymorphic, which means the code is different every time it runs, while persisting the same functionality.
- Targets .exe or .scr files.
- Obfuscates the entry point by:
- Persisting the host file’s entry point.
- Replacing the original host code to be executed at the entry point with a stub redirecting execution to the polymorphic viral code, which has been inserted in the final section of the host file.
- The stub code decrypts and executes the loader, which runs in a separate thread within the infected process and eventually loads the Sality payload that executes the actual malware.
- Is run mostly in the context of other processes.
This sort of file is likely to result in the static scoring function yielding a false negative because the vast majority of the binary’s code is perfectly benign.
Assume we have constructed a cybersecurity map consisting of static feature vectors, embedded behavioral sequence data, descriptive tag data and similarity functions on each space, with mappings between the three spaces. Also assume a file infected with Sality has run on a given machine. Because of the polymorphic nature of the infector, any associated file discovered on the system could produce a hash that differs from that of the original infected file. Because the file was able to evade the machine learning scoring function, the file presumably ran on the system, producing behavioral event sequence data. This event sequence data would then be embedded into a pre-trained event sequence embedding space, hosted as part of a vector database with fast nearest neighbors querying. The returned vectors would be mapped back to static feature space and a fuzzy blocklist could then be pushed to the sensors. These same feature vectors would be passed through the descriptive autotag neural network so that researchers could provide a human-readable account of the false negative as well as the pushed fuzzy blocklists.
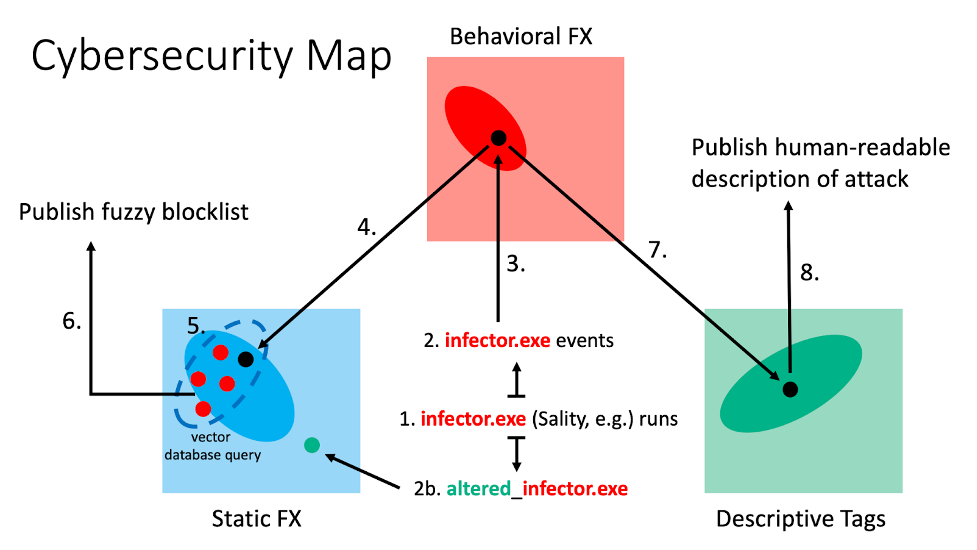 Click to enlarge
Click to enlargeConclusion
Future breaches can be prevented only if we possess a deep understanding of cybersecurity data in the form of a cybersecurity data map that both faithfully represents this data and facilitates the translation between disparate representations.
This similarity-based mapping initiative is just the latest example of how CrowdStrike researchers and data scientists are constantly pushing the envelope to stay ahead of even the most sophisticated adversaries. While customers of the CrowdStrike Falcon platform obviously benefit from their innovative work, publishing their findings publicly also helps to advance the cybersecurity industry in general. The effort is part of CrowdStrike’s ongoing commitment to industry leadership that includes becoming a Research Partner in the MITRE Engenuity Center for Threat-Informed Defense research program.
Additional Resources
- Learn more about the CrowdStrike Falcon platform by visiting the product webpage.
- Learn more about CrowdStrike endpoint detection and response by visiting the CrowdStrike Falcon® Insight XDR webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of CrowdStrike Falcon® Prevent next-gen antivirus today.

