





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)








































- The CrowdStrike Falcon® platform leverages similarity search at scale to drive up efficacy
- PowerShell-based attacks are on the rise and many malware authors save time and effort by using artificial intelligence (AI) tools like ChatGPT to help reuse and tweak source code
- Threat researchers at CrowdStrike can search data in the CrowdStrike® Security Cloud to identify similar script-based attack techniques
- CrowdStrike leverages deep-learning-based feature descriptors to facilitate near-instant search over hundreds of thousands of malicious scripts
According to the AV-TEST Institute, more than 1.2 billion strains of malware and potentially unwanted applications (PUA) have been created. Those numbers are growing rapidly, with more than 250,000 new pieces of malware and PUA detected every day.
One of the main reasons for this rapid growth is that malware creators frequently reuse source code. They modify existing malware to meet the specific objectives of an attack campaign or to avoid signature-based detection.
This reuse of code provides an opportunity for detection by comparing incoming files against known malware for similarities. Given the sheer volume of data involved — the CrowdStrike® Security Cloud can regularly correlate trillions of security events a day — this is a monumental task. However, CrowdStrike threat researchers have completed a project that leverages techniques inspired from computer vision — a field of AI focused on extracting meaningful information from digital images — and that applies similar object search to the PowerShell scripts favored by many adversaries
The result of this project is the ability to search hundreds of thousands of suspect PowerShell script samples and compare them against known malware for similarities in mere seconds. This is another example of how threat researchers continue to build on the Falcon platform’s industry-leading ability to stop breaches.
ChatGPT Has the Potential to Accelerate this Malware Trend
The availability of open source tools and leaked red-teaming software has made it easier than ever for even those with little experience to generate malicious code based on existing malware. However, the emergence of AI tools such as ChatGPT threatens to open the floodgates. In the case of ChatGPT, restrictions are in place to prevent the chatbot from being used for malicious purposes such as writing malware code. However, that hasn’t stopped hackers from finding workarounds. It has been reported that the API supplied for integrating ChatGPT into external applications was compromised by hackers, who then sold access as a service. The compromised version was able to be used for malicious content creation, including generating malware code.
While OpenAI may lock down this particular exploit, the writing is on the wall: ChatGPT and other AI-powered tools will enable even coding neophytes to churn out endless variations of existing malware, with each new version capable of evading traditional signature-based security software
This makes it more important than ever for cybersecurity solutions to be able to rapidly identify malware variants.
Motivation
The CrowdStrike Security Cloud regularly correlates trillions of security events every day with the industry’s leading threat intelligence and enterprise telemetry. The exponential growth in volume of the new threats observed has created the need for developing an intelligent hunting tool that can establish if an instance of malware is similar to previously analyzed samples in our database. We are also interested in spotting other variants of this particular sample that are present in our rich telemetry.
Similarity work makes sense in the cybersecurity space now that creating new variants of existing malware programs has become relatively easy, even for inexperienced aggressors. The current tendency of malware authors leans toward reusing existing source code and slightly tweaking it to meet their needs. Automatically identifying reused code using deep-learning-based tools enables threat researchers to scale their response to incoming alerts with less effort and to get a deeper understanding of the behavior of complex threats.
In this blog post, we introduce a research project that leverages the advanced capabilities of the Falcon platform and the CrowdStrike Security Cloud to detect “new” malware that reuses existing code. We provide insights into how we repurpose our existing deep learning malware detection algorithms for script-based attacks to be employed for similarity search. Our primary intent is to show that generating a compact feature descriptor extracted from one of our deep learning models for PowerShell provides the exciting prospect of making these scripts searchable at scale by using approximate nearest neighbor search.
Approach
In this blog post, we focus on determining similarity between PowerShell scripts, which have become a very popular tool among attackers. In a previous blog post, Seeing Malware Through the Eyes of a Convolutional Neural Network, we showed how distinctive features of various malicious PowerShell attacks can be extracted and explained using deep learning models such as character-level convolutional neural networks (charCNNs).
In addition to their explainability potential, convolutional neural networks provide several other benefits from a modeling standpoint. To understand how this modeling approach can be integrated into a similarity search pipeline, we briefly shift our field of view toward computer vision and more specifically to the representational power of convolutional layers.
The main idea behind CNNs is that as information flows through the network, more and more complex representations are formed inside of the convolutional layers, giving the model a better ability to accurately classify the data. These representations can be extracted from the network and used as feature descriptors for other downstream tasks.
Computer vision literature features a variety of approaches to construct reliable feature descriptors for similar instance retrieval such as the ones presented in the work of Babenko et al. (2014) or Radonevic et al. (2018), to give two examples. We look to borrow insights from their findings and apply them to the field of cybersecurity. As such, we have constructed a rich feature descriptor based on the intrinsic representations derived from one of our deep learning models, which was trained for detecting PowerShell-based threats. Our aim is to leverage the compact nature of this custom-built feature descriptor for performing similarity-based queries in the vector space generated by this novel representation of PowerShell scripts.
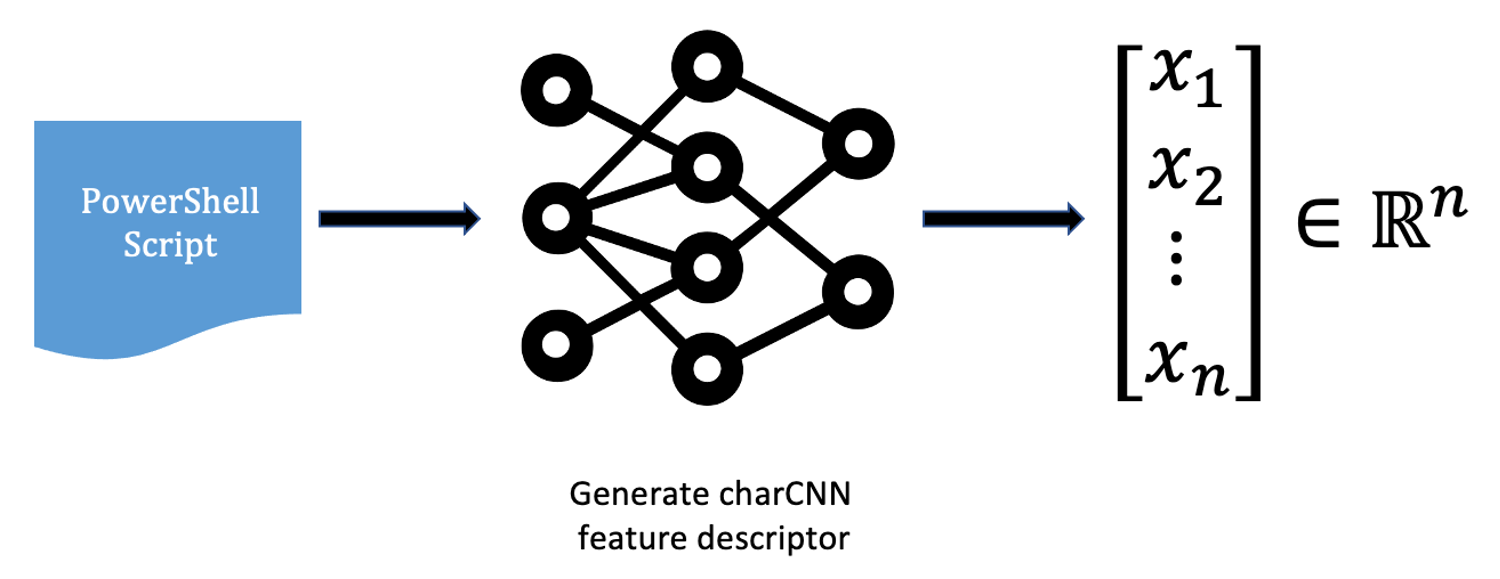 Figure 1. Extracting a vector representation from a PowerShell script
Figure 1. Extracting a vector representation from a PowerShell scriptThrough this process, we are able to embed each PowerShell script in an n-dimensional space, which is able to capture meaningful dependencies between samples.
To search over this newly created vector space, we leverage approximate nearest neighbor (ANN) search — a new paradigm of searching for similar objects. This technique is currently at the core of many AI applications that provide search, recommendation or ranking capabilities over unstructured data (such as text, images or audio files). ANN search techniques are so popular because they enable fast querying over very large datasets by leveraging vector representations of the data and compressing them in an easily searchable space.
One of the most popular frameworks that enables ANN search is Facebook AI similarity search (FAISS), an open source library for efficient similarity search at scale. FAISS is implemented in C++ for efficiency reasons and provides Python bindings for ease of use. Most importantly, FAISS is inherently parallelizable, providing both multi-CPU and multi-GPU support for fast indexing and fast searching capabilities. With FAISS, it becomes easy to search over billions of vectors using a wide range of different distance metrics (both linear and nonlinear).
Similarity Search at Work
Figure 2 describes how threat researchers can query for similar PowerShell scripts using a similarity engine based on approximate nearest neighbor search. This scenario would typically occur whenever an analyst is uncertain with respect to a given sample and would benefit from analyzing a number of scripts side-by-side in order to better profile a particular threat.
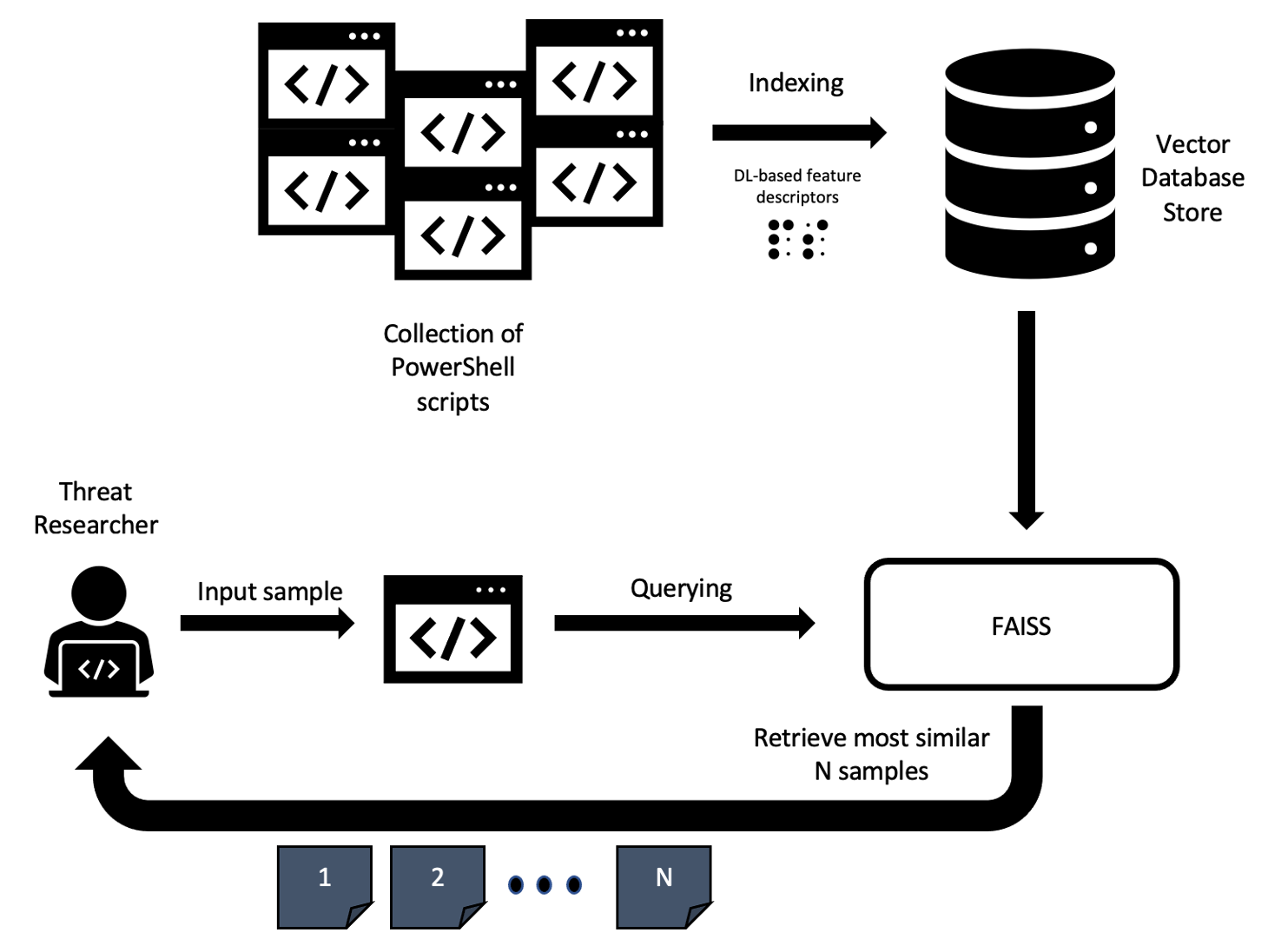 Figure 2. Workflow for retrieving the most similar PowerShell scripts for a given query (Click to enlarge)
Figure 2. Workflow for retrieving the most similar PowerShell scripts for a given query (Click to enlarge)Having near instantaneous access to a large collection of similar samples allows the specialist to assess how threat actors could conceal their attacks by leveraging different tactics while keeping the core functionality of the malware intact. Figure 3 shows how fast query results can be obtained from the PowerShell similarity search engine in a hypothetical scenario where we try to query over an increasingly larger database of scripts, depending on the number of samples the analyst wants to include in their analysis.
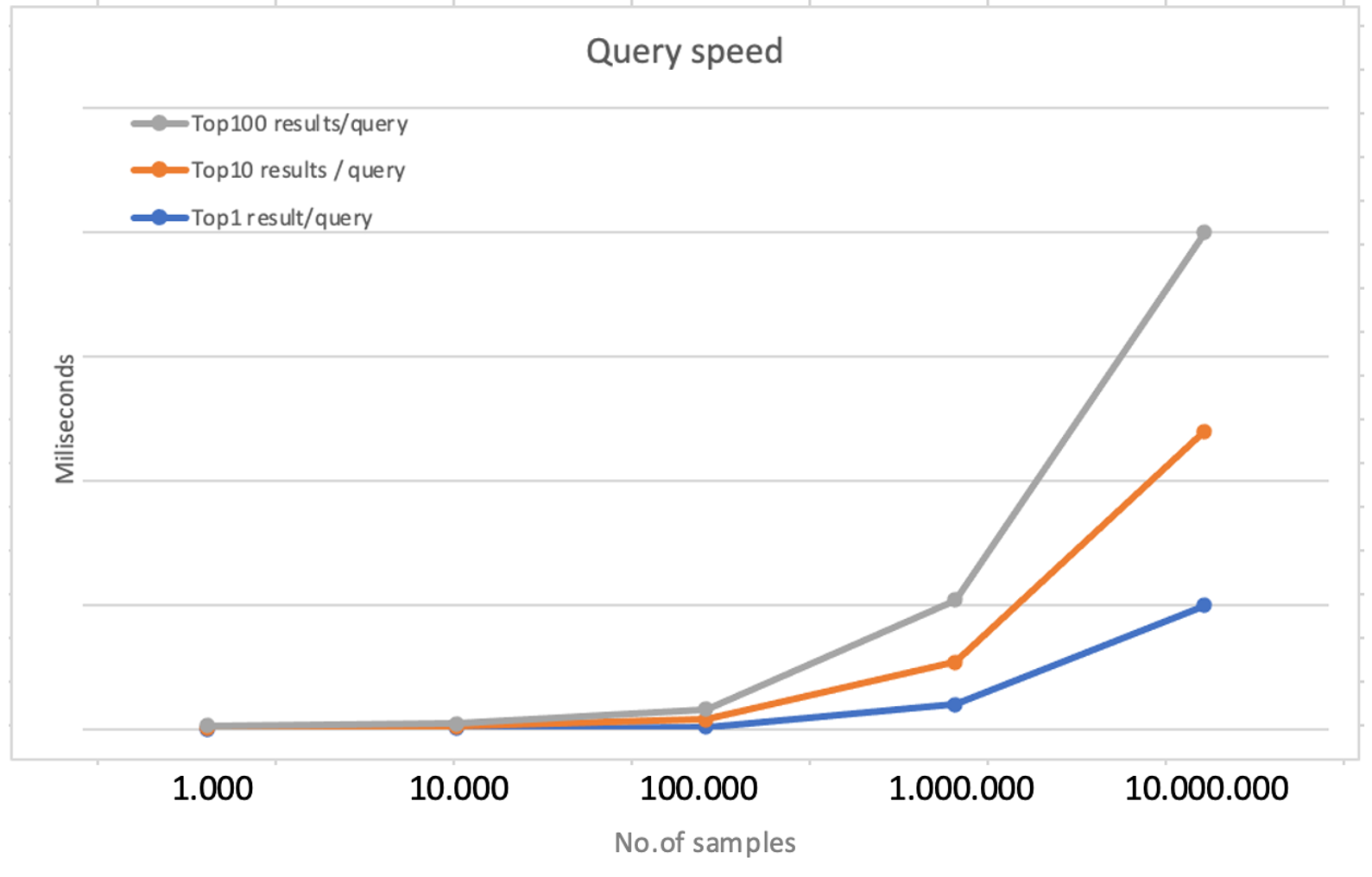 Figure 3. Query speeds over an increasingly larger number of indexed samples (Click to enlarge)
Figure 3. Query speeds over an increasingly larger number of indexed samples (Click to enlarge)As we can see, several milliseconds are enough to retrieve results for a given query. If we’re content to obtain only the top 1 result for a given query, it is straightforward to do so. Retrieval times increase progressively with the number of samples indexed in our collection. The more samples we try to get back from the system (10 or even 100, for example), the more time it will take for the computation to finalize.
Typically, there is no need to perform an exhaustive search — rather, we are more interested in the quality of the results returned. In their work, analysts usually aim to use their time as efficiently as possible and would prefer directing their attention to a targeted set of suitable candidates to derive insights from the data.
Next we illustrate a few results on samples publicly available that highlight the power of our rich feature descriptor and its ability to capture meaningful dependencies in the data (such as being able to assist analysts in uncovering complex similarities between samples).
For example, while using this tool, we have identified scripts 4b1574522eff2217787b9a0bdd967b6597d6a4fff2a445737fca05a7386169aa (further described as script1.ps1) and 6cc0d53c8972447cba2bd4396f7d08ee9f49c0624a28ece72b05b238bc120e8f (further referred to as script2.ps1) to be very similar. To be more specific, script2.ps1 is actually the top 1 result for query script1.ps1. As we can see in Figure 4, the two scripts have marginal differences between them.
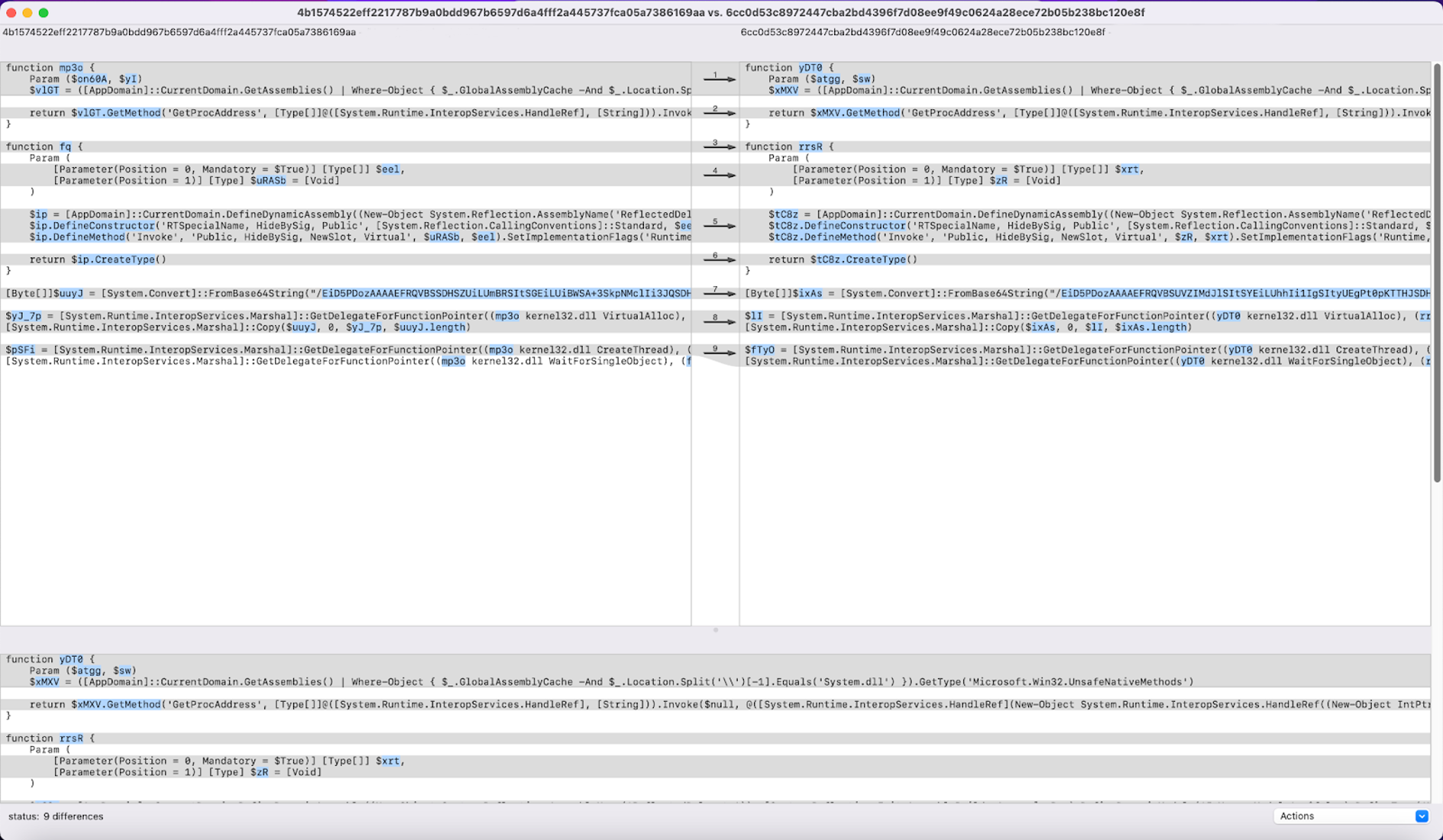 Figure 4. Side-by-side comparison of script1.ps1 (left) and script2.ps1 (right) (Click to enlarge)
Figure 4. Side-by-side comparison of script1.ps1 (left) and script2.ps1 (right) (Click to enlarge)The most notable differences here are derived from variable and function names as well as a Base64-encoded string with a slightly altered content. Another very similar pair is that between query 81dd67b8ec3c9e74d43124857c6fc8ce6bc21a2e2316d684bcfede206d8829e4 (further referred to as script3.ps1) and one of its top 5 results, c937a365669231557cd4fa7ae70532f0dc64ab67db8627532011cf64776c847b (from now on called script4.ps1).
Here, in script3.ps1 (in this scenario, the query) we can see that a dummy function is inserted along with an always true conditional statement. The overall behavior of the sample remains unchanged with regard to the result we got by querying the system. What differs in the second sample, script4.ps1, from the query, script3.ps1, is that the byte values are concatenated in order — instead of being written at once — in an effort to cover up what is going on to the untrained eye.
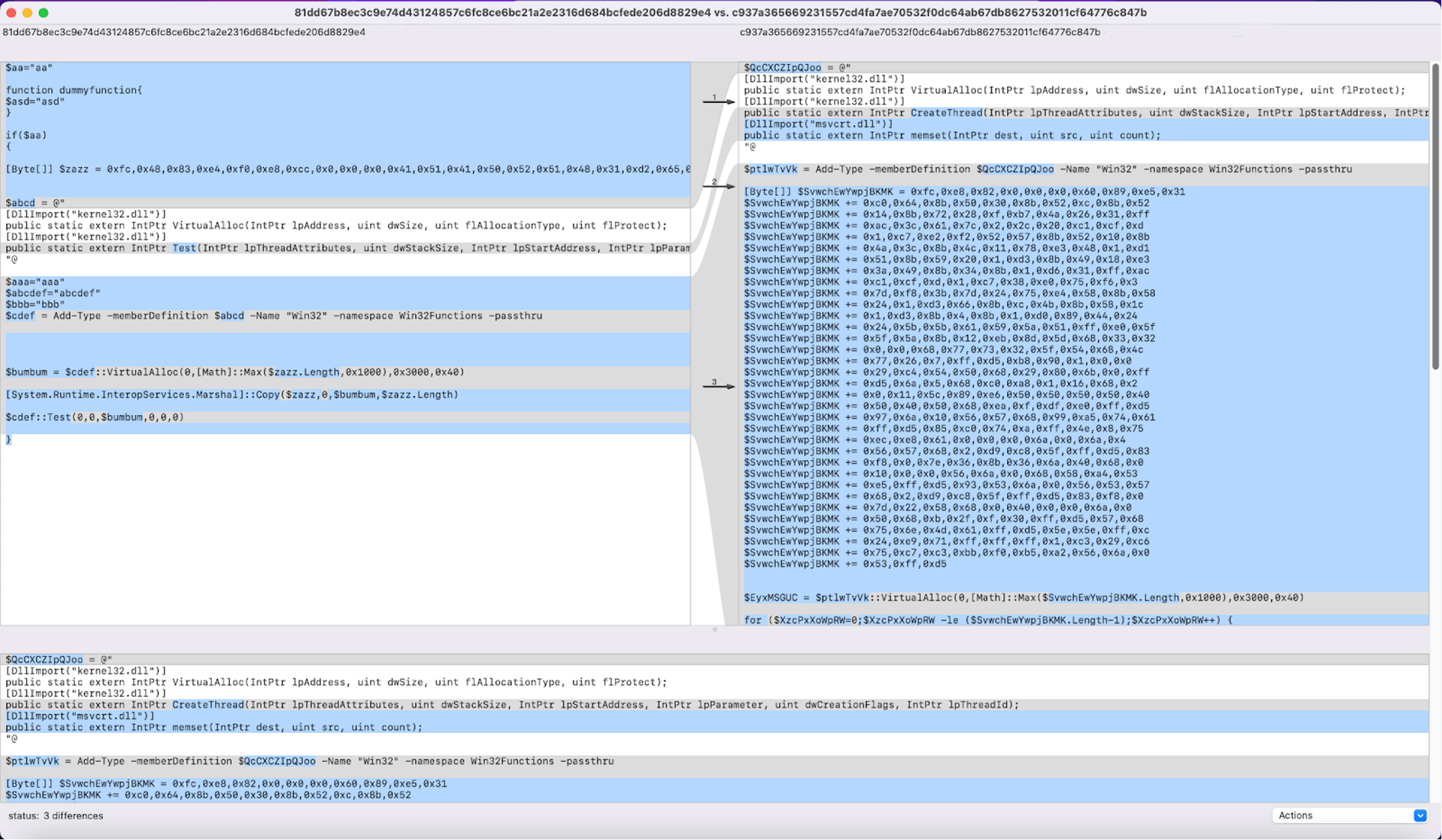 Figure 5. Side-by-side comparison of script3.ps1 (left) and script4.ps1 (right) (Click to enlarge)
Figure 5. Side-by-side comparison of script3.ps1 (left) and script4.ps1 (right) (Click to enlarge)Even if the similarities between the two are striking, not all vendors manage to detect this threat with the same degree of confidence.
The previous examples consisted of smaller scripts, as far as overall number of characters is concerned. When performing a similarity search query for script5.ps1 (with SHA256 30731809924655ce6e9a02b3984af5c0bca7b7669229c69622f386eb78cd62e8) we can, in fact, observe more sizeable changes in the returned results. For example, when comparing script5.ps1 and its top 1 result script6.ps1 (with a SHA256 value of of9eb67b1d20bd59f12d1e20fb18756ef24c0e1bd87d5487f81b181f97d7440066), we can see there are a whopping 242 differences between them.
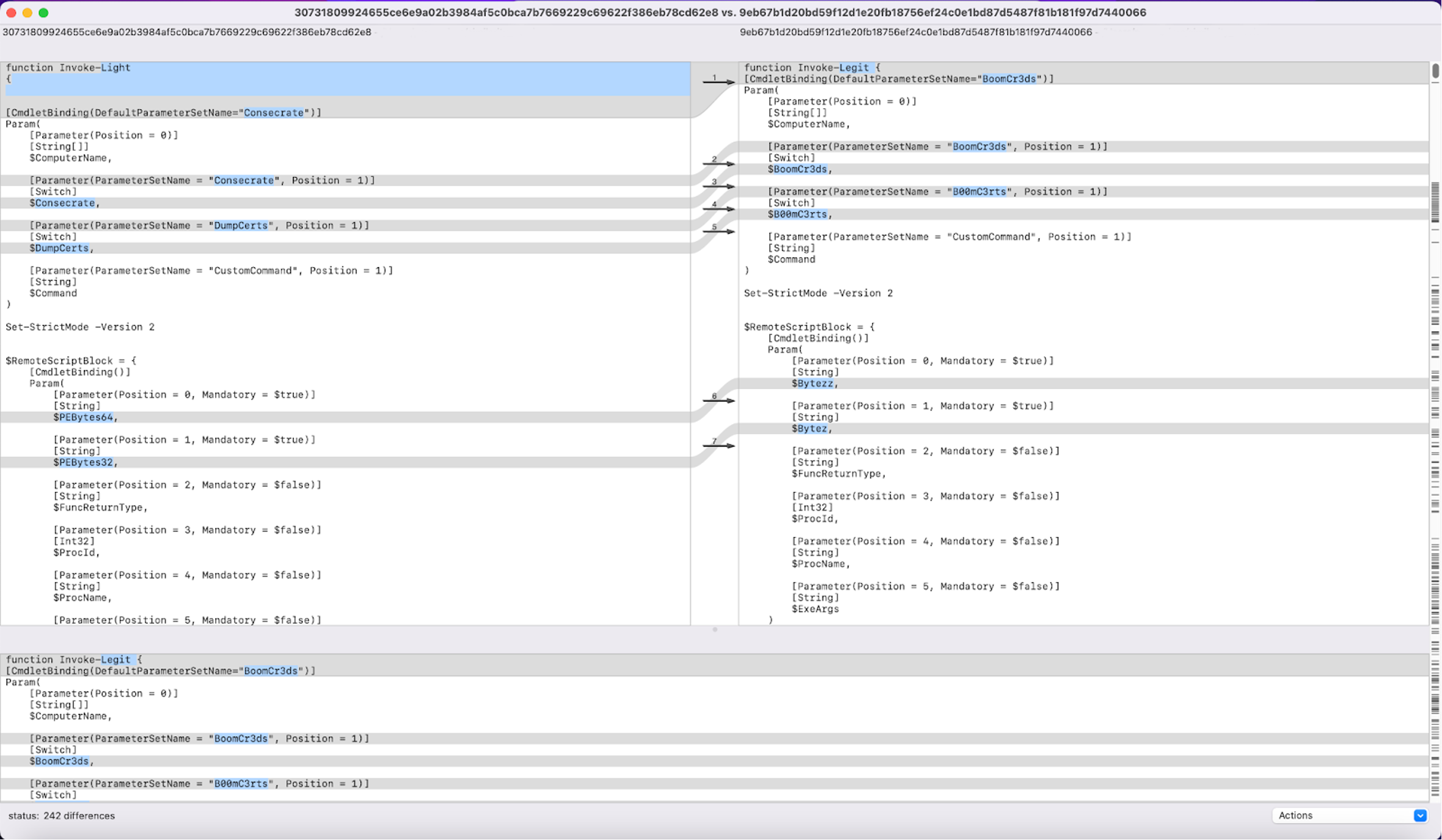 Figure 7. Side-by-side comparison of script5.ps1 (left) and script6.ps1 (right) (Click to enlarge)
Figure 7. Side-by-side comparison of script5.ps1 (left) and script6.ps1 (right) (Click to enlarge)However, AI-powered similarity search enabled us to correctly identify that these two scripts are near duplicates and exhibit the same behavior.
This kind of AI tooling ensures that we can keep our corpora and intelligence reports to the highest standard by facilitating a rigorous due diligence over code duplicates, a very important step when working on machine learning over source code. Abstracting away the complexity of source code analysis and allowing deep learning models to disentangle the problem space by learning efficient representations empowers threat researchers to work on important problems without the need to spend countless hours on menial tasks. Not only are they able to respond faster to emerging threats, they are also more available to contribute their expertise to building better and more representative datasets for improving our machine learning models.
In this way, artificial intelligence helps humans become more effective at their jobs. Moreover, this partnership also extends the other direction, guaranteeing data quality and empowering the training of cutting-edge deep learning classifiers through data-driven AI best practices. It further strengthens the value of the Falcon platform.
The industry-leading CrowdStrike Falcon platform sets the new standard in cybersecurity. Watch this demo to see the Falcon platform in action.
Takeaways
This blog post describes how deep-learning-based feature descriptors can be used for script similarity search. We tackled the usage of deep learning-based classifiers in constructing inner representations of their training data and how these representations can be leveraged in cybersecurity for similarity-based queries. We also showed how these representations can be integrated with an approximate nearest neighbor search framework to equip CrowdStrike threat researchers with the right tools to more effectively detect breaches.
The result of innovative exercises like these is the more effective leveraging of the data captured by the CrowdStrike Security Cloud, adding to the unsurpassed ability for the Falcon platform to prevent breaches, even as the potential misuse of technology like ChatGPT provides new and previously unanticipated challenges. It is yet another example of the research and development that goes into CrowdStrike’s continued cybersecurity industry leadership.
Additional Resources
- Learn more about the CrowdStrike Falcon platform by visiting the product webpage.
- Learn more about CrowdStrike endpoint detection and response by visiting the CrowdStrike Falcon Insight XDR webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent today.


