¿Qué es el aprendizaje automático?
El aprendizaje automático (ML) es un subconjunto de la inteligencia artificial (IA) y hace referencia al proceso de enseñar algoritmos y aprender patrones de los datos existentes con el objeto de predecir respuestas ante datos nuevos.
Aunque los términos IA y ML se utilizan a menudo indistintamente, existen diferencias importantes entre ambos conceptos. La IA se refiere a la tecnología que entrena modelos para imitar o simular procesos de inteligencia humana en entornos del mundo real, mientras que el ML se refiere a los sistemas informáticos resultantes ("modelos") que aprenden de los datos para hacer predicciones.
En esencia, el "aprendizaje" se refiere al proceso en el que los modelos asignan funciones matemáticas para transformar los datos subyacentes con el fin de hacer predicciones precisas. Mientras que los ordenadores pueden programarse para realizar tareas sencillas y predecibles siguiendo instrucciones explícitamente programadas o encadenadas, los modelos de ML desarrollan un enfoque generalizado para resolver problemas.
Tres tipos de aprendizaje automático
En este artículo, repasaremos las tres clases más habituales de aprendizaje automático:
1. Aprendizaje supervisado
El aprendizaje supervisado se produce cuando un modelo se entrena con entradas etiquetadas y resultados deseados, con el objetivo de enseñarle a realizar una tarea cuando se le presentan datos nuevos o desconocidos. En el ámbito de la ciberseguridad, una aplicación común del aprendizaje supervisado es el entrenamiento de modelos sobre muestras inofensivas y maliciosas con el objeto de enseñarles a predecir si las nuevas muestras son maliciosas.
2. Aprendizaje no supervisado
El aprendizaje no supervisado se produce cuando se entrena un modelo con datos no etiquetados y se le deja que encuentre estructuras, relaciones y patrones en los datos, como clústeres o agrupaciones. En ciberseguridad, puede utilizarse para descubrir nuevos patrones de ataque o comportamientos de adversarios (por ejemplo, detección de anomalías) en grandes conjuntos de datos.
3. Aprendizaje por refuerzo
El aprendizaje por refuerzo se produce cuando un modelo no recibe entradas o resultados etiquetados, sino que aprende por ensayo y error, con el objetivo de alcanzar una recompensa acumulativa. Esta forma de aprendizaje automático imita a la perfección el aprendizaje humano y es especialmente útil para identificar formas creativas e innovadoras de resolver problemas. Algunas aplicaciones del aprendizaje por refuerzo en ciberseguridad incluyen soluciones para sistemas ciberfísicos, detección autónoma de intrusiones y ataques de denegación de servicio distribuidos (DDoS).
Ventajas del aprendizaje automático en ciberseguridad
Aplicar el aprendizaje automático a los problemas del ámbito de la ciberseguridad tiene numerosas ventajas, entre las que se incluyen:
1. Sintetizar rápidamente grandes volúmenes de datos. Uno de los mayores retos a los que se enfrentan los analistas es la necesidad de sintetizar rápidamente la inteligencia generada a través de su superficie de ataque, que normalmente se genera mucho más rápido de lo que sus equipos pueden procesar manualmente. El aprendizaje automático es capaz de analizar rápidamente grandes volúmenes de inteligencia histórica y dinámica, lo que permite a los equipos hacer operativos los datos procedentes de diversas fuentes casi en tiempo real.
2. Activar la inteligencia experta a escala. Los ciclos de entrenamiento regulares permiten a los modelos aprender de forma continua de su población de muestra en desarrollo, que incluye detecciones etiquetadas por analistas o alertas revisadas por analistas. Esto evita los falsos positivos recurrentes y permite a los modelos aprender y aplicar la verdad de base generada por los expertos.
3. Automatizar tareas manuales repetitivas. Aplicar el aprendizaje automático a tareas específicas puede liberar a los equipos de seguridad de tareas rutinarias y repetitivas, actuando como un multiplicador de esfuerzos que les permite escalar su respuesta en función de las alertas entrantes y redirigir tiempo y recursos hacia proyectos estratégicos y complejos.
4. Aumentar la eficacia de los analistas. El aprendizaje automático puede aumentar el conocimiento de los analistas con inteligencia actualizada en tiempo real, lo que permite a los analistas de Threat Hunting y las operaciones de seguridad priorizar eficazmente los recursos para abordar las vulnerabilidades críticas de la organización e investigar detecciones sensibles al tiempo generadas por ML.
Casos de uso del aprendizaje automático en ciberseguridad
El aprendizaje automático tiene una amplia y creciente gama de casos de uso en el ámbito de la ciberseguridad. Podemos dividir estos casos de uso en dos grupos principales:
- Detección y respuesta automatizadas ante amenazas
- Operaciones dirigidas por analistas y asistidas por aprendizaje automático
Detección y respuesta autónomas ante amenazas
En la primera categoría, el aprendizaje automático permite a las organizaciones automatizar el trabajo manual, especialmente en procesos en los que es fundamental mantener altos niveles de precisión y responder con máxima velocidad, como la detección y respuesta automáticas ante amenazas o la clasificación de nuevos patrones de adversarios.
La aplicación del aprendizaje automático en estos escenarios aumenta los métodos de detección de amenazas basados en firmas con un enfoque generalizado que aprende las diferencias entre muestras inofensivas y maliciosas y puede detectar rápidamente nuevas amenazas en circulación.
Impulso de la eficiencia de los analistas con el aprendizaje automático
Los modelos de aprendizaje automático también pueden ayudar en las investigaciones dirigidas por analistas alertando a los equipos para que investiguen las detecciones o priorizando las vulnerabilidades para la aplicación de parches. La revisión por parte de los analistas puede ser especialmente valiosa en situaciones en las que no hay datos suficientes para que los modelos puedan predecir resultados con un alto grado de confianza o para investigar comportamientos de apariencia inofensiva que pueden pasar desapercibidos para los clasificadores de malware.
Otros casos de uso del aprendizaje automático en ciberseguridad
A continuación se incluye una lista de ejemplos comunes (no exhaustiva) de cómo puede utilizarse el aprendizaje automático en el ámbito de la ciberseguridad.
| Caso de uso | Descripción |
|---|---|
| Gestión de vulnerabilidades | Proporciona una priorización de vulnerabilidades recomendada basada en la criticidad para los equipos de TI y seguridad. |
| Análisis estático de archivos | Permite la prevención de amenazas mediante la predicción de la peligrosidad de un archivo basándose en sus características. |
| Análisis de comportamiento | Analiza el comportamiento de los adversarios mientras se ejecuta para modelar y predecir patrones de ataque en toda la cadena de ciberataques. |
| Análisis híbrido estático y de comportamiento | Combina el análisis estático de archivos y el análisis de comportamiento para proporcionar una detección avanzada de amenazas. |
| Detección de anomalías | Identifica anomalías en los datos para informar sobre la puntuación de riesgos y orientar las investigaciones de amenazas. |
| Análisis forense | Ejecuta actividades de contrainteligencia para analizar la progresión de los ataques e identificar vulnerabilidades del sistema. |
| Análisis de malware de Sandbox | Analiza muestras de código en entornos aislados y seguros para identificar y clasificar comportamientos maliciosos, así como asignarlos a adversarios conocidos. |
Evaluación de la eficacia de los modelos de aprendizaje automático
Eficacia de los modelos para clasificadores de malware:
Una de las aplicaciones más comunes del aprendizaje automático en ciberseguridad es la clasificación de malware. Los clasificadores de malware generan una predicción puntuada sobre si una muestra dada es maliciosa; donde "puntuada" se refiere al nivel de confianza asociado con la clasificación resultante. Una forma de evaluar el rendimiento de estos modelos es representando las predicciones en dos ejes: precisión (si un resultado se ha clasificado correctamente; "verdadero" o "falso") y resultado (la clase que un modelo asigna a una muestra; "positivo" o "negativo").
Ten en cuenta que los términos "positivo" y "negativo" en este marco no significan que una muestra sea respectivamente "inofensiva" o "maliciosa". Si un clasificador de malware realiza una detección con valor "positivo", esto indica que el modelo está prediciendo que una muestra dada es maliciosa, basándose en la observación de características que ha aprendido a asociar con muestras maliciosas conocidas.
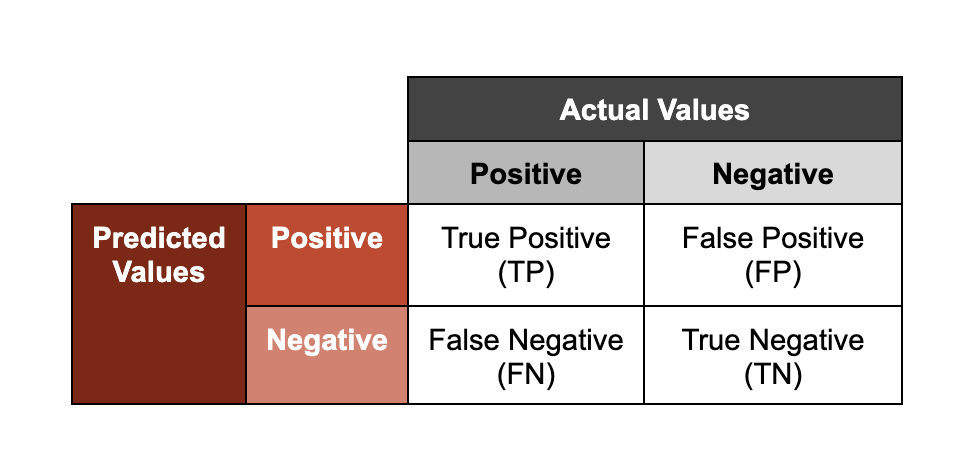
Para ilustrar lo que significan estas agrupaciones, utilizaremos el ejemplo de modelos entrenados para analizar archivos maliciosos.
- Verdadero positivo: el modelo predijo correctamente que un archivo era malicioso.
- Verdadero negativo: el modelo predijo correctamente que un archivo no era malicioso.
- Falso positivo: el modelo predijo incorrectamente que un archivo era malicioso (y no lo era).
- Falso negativo: el modelo predijo incorrectamente que un archivo no era malicioso (y lo era).
Equilibrio entre verdaderos y falsos positivos
Aunque los verdaderos positivos son esenciales para la detección y respuesta ante amenazas, los falsos positivos también son una medida importante del rendimiento del modelo. Los falsos positivos tienen un coste de oportunidad asociado al tiempo y los recursos que los equipos de seguridad dedican a investigar cada detección, y pueden ser especialmente costosos si desencadenan procesos automáticos de corrección que bloquean o interrumpen aplicaciones críticas para las operaciones de una organización.
A la hora de calibrar la agresividad o sensibilidad del modelo, los científicos de datos deben optimizar tanto el índice de verdaderos positivos como el de falsos positivos, enfrentándose a una disyuntiva crítica: reducir el umbral de los verdaderos positivos (es decir, los requisitos que deben cumplirse para que un modelo clasifique una muestra en "positivo") conlleva el riesgo de reducir también el umbral de los falsos positivos (lo que podría provocar una pérdida de productividad de los analistas y agravar la fatiga de las alertas). A este compromiso lo denominamos eficacia de la detección.
El objetivo final de crear modelos de aprendizaje automático de alto rendimiento es potenciar la eficacia de la detección: incrementar las detecciones de verdaderos positivos reduciendo los falsos positivos. Para ilustrar la complejidad de este equilibrio, consideremos que no es raro que los clasificadores de malware tengan índices de verdaderos positivos cercanos al 99 %, con índices de falsos positivos muy por debajo del 1 %.
Retos y limitaciones del aprendizaje automático
Aunque los modelos de aprendizaje automático pueden ser herramientas potentes, cada modelo funciona con limitaciones propias:
Datos suficientes de alta calidad. El entrenamiento de modelos de alta confianza suele requerir el acceso a grandes conjuntos de datos, tanto para entrenar como para probar los modelos de aprendizaje automático. Para probar los modelos, normalmente se aparta un subconjunto de datos del conjunto de entrenamiento para probar el rendimiento del modelo. Estos datos deben tener un solapamiento mínimo de características con los datos de entrenamiento. Representar, por ejemplo, un periodo de tiempo diferente de recopilación de datos o proceder de una fuente de datos distinta. Si no hay suficientes datos de alta calidad, un determinado espacio problemático podría no ser un escenario adecuado para el aprendizaje automático aplicado.
Compensaciones entre verdaderos y falsos positivos. Tal como se mencionó anteriormente, la sensibilidad de cada modelo debe calibrarse para equilibrar el umbral de detección entre verdaderos y falsos positivos, con el fin de ampliar la eficacia de la detección.
Explicabilidad. La explicabilidad se refiere a la capacidad de explicar cómo y por qué un modelo se comporta de determinada manera. Esto permite a los equipos de ciencia de datos comprender qué características de una muestra influyen en el rendimiento del modelo y cuál es su peso relativo. La explicabilidad es fundamental para fomentar la responsabilidad, generar confianza, garantizar el cumplimiento de las directivas de datos y, en última instancia, permitir la mejora continua del rendimiento en el aprendizaje automático.
Repetibilidad. También conocida como reproducibilidad, se refiere a la capacidad de replicar de manera consistente los experimentos de aprendizaje automático. La repetibilidad impulsa la transparencia en torno a cómo se utiliza el aprendizaje automático, qué tipos de modelos se emplean, con qué datos se entrenan y en qué entornos o versiones de software funcionan. La repetibilidad reduce al mínimo la ambigüedad y los posibles errores a medida que los modelos pasan de las pruebas a la implementación y a través de futuros ciclos de actualización.
Optimización para el entorno de destino. Cada modelo debe optimizarse para su entorno de producción de destino. Cada entorno variará en cuanto a disponibilidad de recursos informáticos, memoria y conectividad. Por consiguiente, cada modelo debe diseñarse para funcionar en su entorno de implementación, sin sobrecargar ni interrumpir las operaciones del host de destino.
Refuerzo contra ataques de adversarios. Los modelos de aprendizaje automático tienen su propia superficie de ataque que puede ser vulnerable a ataques de adversarios, quienes pueden intentar aprovechar o modificar el comportamiento del modelo (por ejemplo, haciendo que el modelo clasifique erróneamente las muestras). Para reducir al mínimo la superficie de ataque aprovechable de los modelos, los expertos en ciencia de datos "refuerzan" los modelos en el entrenamiento para garantizar un buen rendimiento y resiliencia frente a los ataques.
Dos ideas erróneas sobre el aprendizaje automático
Idea errónea n.° 1: el aprendizaje automático es mejor que los métodos analíticos o estadísticos convencionales.
Aunque el aprendizaje automático puede ser una herramienta muy eficaz, puede que no sea adecuada para su uso en todos los espacios problemáticos. Otros métodos analíticos o estadísticos pueden producir resultados muy precisos y eficaces o consumir menos recursos que un enfoque de aprendizaje automático, y ser el enfoque más adecuado para un determinado espacio problemático.
Idea errónea n.° 2: el aprendizaje automático debe utilizarse para automatizar tantas tareas como sea posible.
El aprendizaje automático puede requerir numerosos recursos, a menudo acceso a grandes cantidades de datos, recursos informáticos y equipos dedicados a la ciencia de datos para crear, entrenar y mantener modelos. Para potenciar el ROI en el mantenimiento de modelos, lo ideal es aplicarlos cuando los problemas objetivo tienen un alto valor, se presentan con frecuencia, requieren velocidad y precisión, y cuentan con conjuntos de datos de alta calidad para un proceso de entrenamiento y prueba continuo.
El enfoque de CrowdStrike del aprendizaje automático
CrowdStrike aplica el aprendizaje automático en toda la plataforma CrowdStrike Falcon® para ofrecer una protección avanzada frente a las amenazas.
La inteligencia sin precedentes de CrowdStrike Security Cloud
Los modelos de CrowdStrike se entrenan en la potente telemetría de CrowdStrike Security Cloud, que correlaciona billones de puntos de datos a través del Asset Graph, Intel Graph y el Threat Graph® patentado de CrowdStrike para ofrecer una visibilidad sin precedentes y una inteligencia sobre amenazas en constante evolución a lo largo de la superficie de ataque de una organización.
Este conocimiento se enriquece con un corpus cada vez mayor de datos reales generados por equipos de expertos de CrowdStrike, incluidos los equipos de Threat Hunting de CrowdStrike (Falcon OverWatch™), el Centro de investigación de malware y los equipos de Detección y respuesta gestionadas (Falcon Complete™).
Aumento de la experiencia humana
Los modelos de CrowdStrike impulsan la detección autónoma de amenazas y la respuesta, al tiempo que aumentan la experiencia humana en dominios dirigidos por expertos, como el Threat Hunting y las operaciones de TI y seguridad. Los modelos de aprendizaje automático en toda la plataforma Falcon operan para ofrecer un entorno de trabajo de última generación para analistas, que automatiza la detección y respuesta, maximiza la eficiencia del analista con detecciones de alta precisión generadas por aprendizaje automático y proporciona recomendaciones inteligentes de gestión de vulnerabilidades para una defensa proactiva (con el modelo ExPRT.AI de Falcon Spotlight™).
Varias capas de defensa
CrowdStrike aplica el aprendizaje automático en toda la plataforma Falcon para ofrecer una defensa sólida de varias capas en todo el ciclo de vida del proceso (antes de la ejecución, durante la ejecución y después de la ejecución). Los modelos de aprendizaje automático previos a la ejecución, en el sensor y basados en la nube operan de manera sincronizada para detectar y responder automáticamente a las amenazas, proporcionando al agente ligero de Falcon una sólida primera línea de defensa. La sincronización constante entre los modelos de aprendizaje automático en la nube y en el sensor permite que las detecciones realizadas en el sensor se apliquen globalmente en toda la superficie de ataque y, del mismo modo, permite que las detecciones realizadas por los modelos basados en la nube se apliquen instantáneamente en todos los endpoints protegidos.
Para ampliar este enfoque, CrowdStrike también aplica un análisis de comportamiento avanzado en tiempo de ejecución, utilizando modelos basados en la nube para analizar los eventos de los endpoints y clasificar los indicadores de ataque (IOA). Los IOA impulsados por IA detectan de forma proactiva las amenazas emergentes independientemente del malware o las herramientas utilizadas y funcionan de forma asíncrona a los modelos en el sensor para activar el análisis local de comportamientos sospechosos basándose en la inteligencia sobre amenazas en tiempo real.
Tras la ejecución, los indicadores de comportamiento se utilizan para evaluar la actividad anómala en toda la superficie de ataque de una organización (como indica la métrica CrowdStrike CrowdScore™, que proporciona una indicación en tiempo real del nivel de amenaza de una organización), y también son utilizados por Falcon OverWatch para investigar las amenazas avanzadas, como la actividad hands-on-keyboard, la delincuencia electrónica y los ataques sigilosos.
Más información
Descubre cómo CrowdStrike combina la potencia de la nube con tecnologías de vanguardia como TensorFlow y Rust para que el entrenamiento de modelos sea cientos de veces más rápido.
Lucia Stanham ocupa el puesto de Senior Product Marketing Manager en CrowdStrike y se centra en la protección de endpoints (EDR/XDR) y en la IA en ciberseguridad. Forma parte de CrowdStrike desde junio de 2022.
