





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































- CrowdStrike releases a free tool for data scientists for porting TensorFlow machine learning models to Rust pure safe code
- The tool, named tf2rust, enables data scientists to create leaner machine learning model builds utilizing less memory and with better performance
- Using the CrowdStrike tf2rust Rust conversion tool, data scientists can build machine learning models with remarkable boost in performance, without the dependencies and complexity of traditional frameworks
Deep learning is a core part of CrowdStrike’s arsenal of machine learning (ML) techniques, and we are constantly innovating in this area to boost the performance of our ML models. However, ML can consume large amounts of computing resources. To minimize the computing load and its associated costs, we strive to optimize performance and resource utilization for our models as well as address any safety issues related to the use of third-party tools. To this end, we turned to the use of low-level implementations of the trained ML models in languages such as Rust. In a previous blog post, we addressed why Rust is a powerful tool and outlined the reasons for using it.
As we discussed in our previous blog posts (Building on the Shoulders of Giants: Combining TensorFlow and Rust and Development Cost of Porting TensorFlow Models to Pure Rust), we developed an internal tool to convert those trained machine learning models into pure Rust code and ran a set of tests and benchmarks to assess their performance. As a result, we are pleased to announce that this tool, named tf2rust, is now publicly available on our GitHub to anyone that wants to run their own experiments and convert TensorFlow models to Rust.
Grab the free CrowdStrike tf2rust tool from GitHub here.
In this blog post, we provide guidance on how any interested party can start using the tool immediately.
Why TensorFlow and Rust
The impressive performance of neural networks comes at a computational cost. When deploying deep learning models in restricted environments like smartphones and laptops, it can often be a struggle to balance performance without consuming all available compute power.
In the process of ML model training and optimization, the use of computing resources is less of an issue, as training the model is expected to be resource-intensive. However, when deploying the ML model in production, it becomes crucial to minimize both computing resource consumption and time to prediction. This is where using Rust as the inference platform for trained TensorFlow models plays a critical role. Rust leads to leaner builds utilizing less memory and smaller footprint artifacts, without the dependencies and complexity of third-party dependencies, which leads to decreased attack surface for adversaries.
The goal here is not to replace Python and the ML ecosystem built by a plethora of frameworks. Rather, we are taking the best tools available, preparing our models and providing an inference implementation that is optimized for memory usage and performance. The resulting code is ready for deployment in resource-constrained environments — which is where Rust has proved it’s especially useful.
Performance by the Numbers
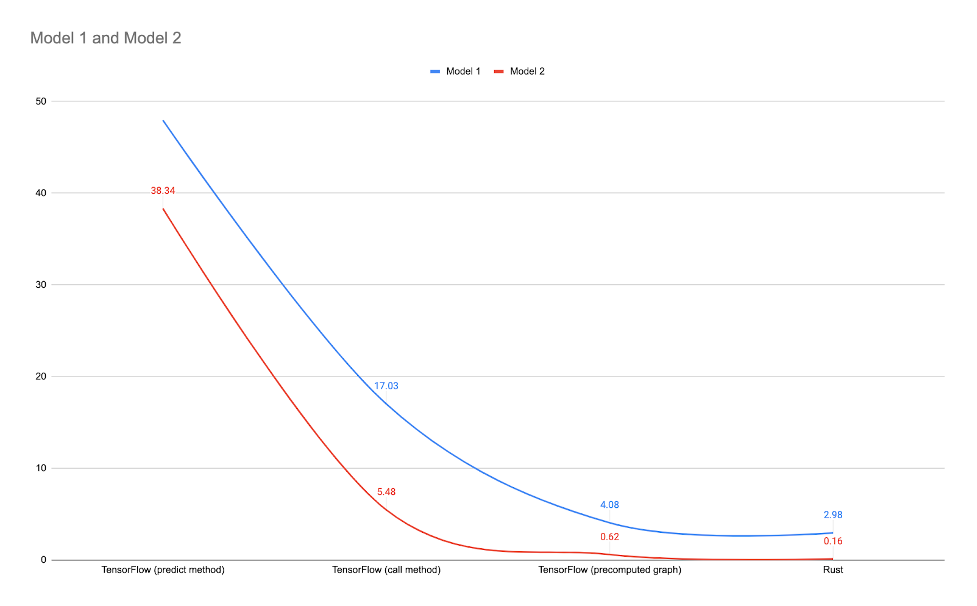
To summarize some of our findings regarding the improvements we observed, the diagram below represents results by comparing different optimization levels for TensorFlow inference and Rust inference on the same models. Even the most optimized TensorFlow version still performs anywhere from 27% to 74% worse than our standard Rust implementation.
For more in-depth details about measuring the performance of Rust models, read this blog post, which explores in detail the advantages of using Rust as the inference tool for trained models in TensorFlow.
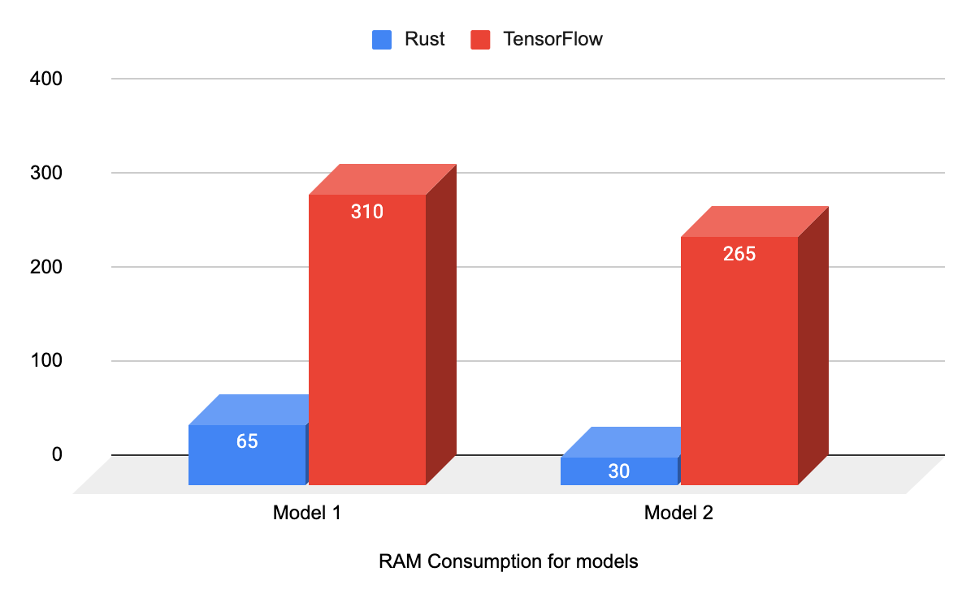
As for memory utilization, the numbers are also impressive. The maximum memory usage for one of the Tensorflow models reached 310MB, which was reduced to around 65MB as a Rust implementation, resulting in a decrease of about 80% in memory usage. The significant memory optimization enables Rust models to run on memory-restricted devices, like mobiles.
About CrowdStrike’s Free TensorFlow to Rust (tf2rust)
TensorFlow to Rust — or tf2rust — is a set of two repositories: a Rust crate tf-layers implementing neural layers and a Python package tf2rust Rust code generator.
The tf2rust package keeps only the relevant information for inference purposes as well as the final model conversion to Rust code, including prediction functions, tests and basic benchmarks.
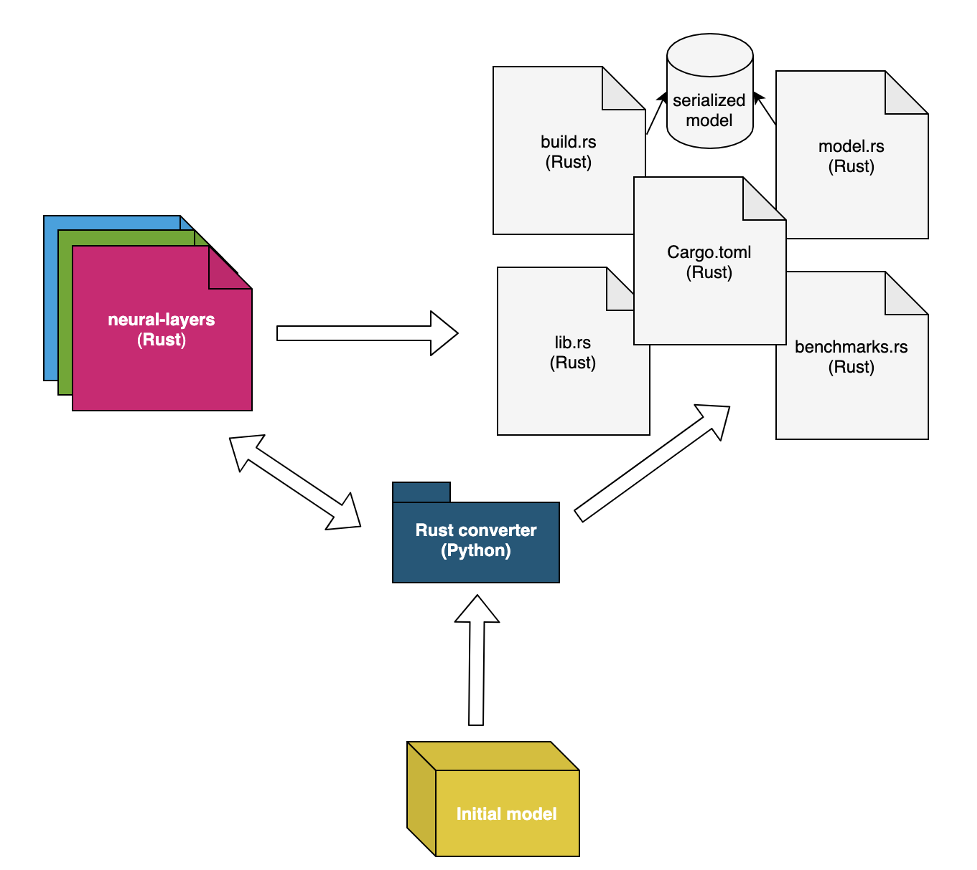
The above diagram shows the Python conversion and Rust code generation handled by the tf2rust package — the generated Rust code has a dependency on the tf-layers crate.
The tf-layers crate implements from scratch many layers of interest for deep learning architectures. To make the tf-layers representation very efficient to run in Rust, we applied several optimization techniques, such as: 1) replacing directly indexing the matrices with iterators, 2) offering support for batch serving capabilities and 3) using generalized matrix multiplication routines for the bottleneck layers (e.g., the convolutional layer). More details about performance improvements can be found in this blog.
How to Use tf2rust
Implemented Layers
Currently, the converter implements only a selection of layers (the layers number is expected to grow with the addition of further architectures):
- InputLayer — Input layer
- Multiply — Multiply layer
- Reshape — Reshape layer
- Conv1D — 1D convolutional layer
- Embedding — Embedding layer
- Dense — Dense layer
- Flatten — Flatten layer
- Concatenate — Concatenate layer
- GlobalAveragePooling — Global average pooling layer
- MaxPooling — Max pooling layer
- AveragePooling — Average pooling layer
- BatchNormalization — Batch normalization layer
- Add — Addition layer
- Mean — Mean layer over a specified axis
- Activation — Different types of activation are supported (can be used as an independent layer or inside different NN layers such as Dense, Conv1D, etc.); support is available for:
- Linear(Identity)
- Relu
- ThresholdedRelu
- Selu
- Sigmoid
- Softmax
- SoftPlus
- SoftSign
- Tanh
Please note that some layers may not fully support all TensorFlow implementations, but they are open for extension.
It is mandatory to use an InputLayer for each input that the model expects. It is also mandatory that InputLayer's type be exactly specified (default is float). For instance, if an InputLayer is followed by an EmbeddingLayer, then the type of that particular InputLayer must be set to int — e.g., int64.
Another requirement is to have the output_shape of each layer specified (the only unspecified size should be about the batch size). This is usually done by setting the input_shape parameter when initializing the InputLayer.
Command Line
The tf2rust tool implements a command line interface that provides a simple way to customize the model generation and supports automation where required.
The command line arguments we can use are:
--path_to_tf_model // string // mandatory
The path (relative or absolute) to the TensorFlow model to be converted into Rust code.
--path_to_save // string // mandatory
The path (relative or absolute) where to save the generated Rust code. --model_name // string // mandatory
The model name. A struct named <model_name>Model will be created in Rust (e.g., model_name = Test => TestModel). --binary_classification // boolean
Set this flag to true/false whether the model is a binary classifier or not (false for regression or multiclass classifiers). Default is true. --enable_inplace // boolean
Set this flag to true/false whether you want the model written in Rust to use in-place operations whenever possible (in the “predict_from_array” function). Default is true. --enable_memdrop // boolean
Set this flag to true/false whether you want the model written in Rust to free the memory of intermediate layers results as soon as possible (instead of the actual ending of the `predict_from_array` function). Default is true.
--path_to_fv // string // optional
Set the path to a npz array containing the FV for a bunch of samples. The keys for the arrays should match the keys from perform_fx from NeuralBrain (which must be the same as the InputLayers' names when building the model). Also, the expected predictions should be saved as an array in features.npz by the key predictions. This flag is optional.
Resulting Structure
What are the results of the conversion?
The generated Rust code comprises the following files:
* saved_model_from_tensorflow/:
* computation_graph.json: The computational dependencies.
* model_architecture.json: Different parameters for the actual NN layers (stride, pool_size, kernel_size, activation type, etc).
* model_overview.png: A graph image describing the model.
* model_weights.npz: model's weights.
* rust_generated_code/:
* build.rs: A Rust build file used in serialising the model by reading from model_weights.npz
* Cargo.toml: the place where all the imports are specified (and many more).
* rust_generated_code/model:
* model_weights.npz: model weights saved in a format that can be used by Rust.
* thresholds.json: the thresholds for `low`, `bottom`, `medium`, `high` confidence levels.
* rust_generated_code/src:
* model.rs: A Rust structure encapsulating all the logic behind prediction.
* lib.rs: the file containing the tests.
* rust_generated_code/testdata:
* features.npz: the features to be passed to the model (1D numpy ndarray).
* rust_generated_code/benches:
* benchmarks.rs: the file in charge of benchmarks.
Using tf2rust
Several steps are necessary to use the converter, which we cover in more detail below.
Step 1: Prepare the environment
This project targets Python 3.9 and Rust > 1.62; instructions on how to install Rust can be found here: https://rustup.rs/. You will need to install graphviz using your system dependency manager of choice. Additionally, the package uses TensorFlow scikit-learn and numpy, which can both be installed using requirements.txt and pip. We recommend using a virtual environment. To set up a virtualenv, run the following commands in the project root:
python -m venv .venv
. .venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt
Step 2: Prepare the model
The converter requires the model to be saved in PB format. Below is a snippet to convert an h5 model to PB:
from tensorflow.keras.models import load_model, save_model
# Note that models will have different metrics also saved with the models and expect the implementations for these metrics.
# We have these implemented in utils/scoring_metrics.py but these are not used, and we can also provide `None`.
model = load_model('new_model.h5', custom_objects={'tpr': None, 'tnr': None, 'auc': None})
save_model(model=model, filepath='tf_model/', include_optimizer=False)
Step 3: Use the converter to generate Rust code
python3 main.py \
--path_to_tf_model tests/data/mnist/tf_model/ \
--path_to_save tests/data/generated_classifiers/mnist \
--model_name MNIST \
--binary_classification True \
--enable_inplace True \
--enable_memdrop True \
--path_to_fv tests/data/MNIST/features.npz
Step 4: Test the generated code
In order to assess the performance of the model, run: cargo bench.
To test the predictions and check that the code translation went as expected, run: cargo test.
Note: All of these commands need to be executed in the rust_generated_code/ directory.
CrowdStrike’s Free Tool for Data Scientists
CrowdStrike is offering the free tf2rust tool to empower data scientists, engineers and machine learning experts to be more productive by having the right tool to drive and build high-performance ML models. Professionals interested in using tf2rust will find it easier and faster to deploy deep learning models in production, especially in resource-constrained environments.
We are very excited about the direction and pace that deep learning and AI in general are going. Please watch this space to keep up-to-date with the latest developments, and give tf2rust a try. Constructive feedback via GitHub Issues (tf-layers, tf2rust), as well as suggestions and contributions via GitHub Pull Requests (tf-layers, tf2rust) from the community are much appreciated as they will help us to continue to improve the tf2rust tool. TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc. Rust and the Rust logo are trademarks of the Mozilla Foundation.
Additional Resources
- Check out CrowdStrike’s free Community Tools.
- Learn about CrowdStrike’s Sandbox Scryer free threat-hunting tool.
- Learn more about the industry-leading protection of the CrowdStrike Falcon® platform.
- See how true next-gen AV performs against today’s most sophisticated threats — get a full-featured free trial of CrowdStrike Falcon® Prevent.

