





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)








































This blog was originally published Jan. 6, 2020 on humio.com. Humio is a CrowdStrike Company.
Humio is purpose-built to aggregate and retain billions of streaming logs, then analyze and visualize them to determine the health of the environment — something we describe as “feeling the hum of the system.” Humio developers tenaciously optimize data ingest, retention, compression, and storage to take advantage of today’s modern hardware. In a talk at QCon 2019 called Real-time Log Analytics at Scale with Kafka, our CTO Kresten Krab Thorup describes some of the technology powering Humio. He explains how Humio is able to ingest hundreds of terabytes of streaming data per day and still deliver instant ingest, real-time alerts and reports, and lightning-fast search results.Optimized search is at the heart of Humio
The primary way users interact with Humio is to perform searches to explore the data to find answers to questions and get to the root-cause of issues. At the heart of the Humio platform are advanced proprietary algorithms that provide search results with sub-second latency. One way we optimize performance is to bypass indexing the data. As a result, the moment the data is ingested, alerts and reports are updated, and the data is available to search. But without an index, Humio needs to be clever about how search is implemented.How Humio optimizes brute-force search
There are lots of clever ways to perform a search. The simplest to conceptualize is a brute-force linear search that sequentially checks every element. But when it’s used with a large number of candidates, it can be really slow. So it may surprise you that we make Humio so incredibly fast by using brute-force methods to search logs. You may cringe thinking about using brute-force to search so much log data. It sounds like a huge waste of resources. Isn’t it a tool from the stone ages?! Our engineers have discovered that when brute-force search is altered to increase efficiency, it becomes as fast as index-based searching, enabling you to search streaming data as well as stored data!Mechanical sympathy
Humio engineers understand the intricacies of the hardware, using principles of mechanical sympathy - looking at the performance from the machine’s perspective and attempting to make it easier to do its job successfully. The term was coined by race car driver Jackie Stewart, who said, “You don’t have to be an engineer to be a racing driver, but you do have to have mechanical sympathy.” So when Humio uses brute-force searching, they implement it in a way that makes the work easiest for your processors. Instead of searching your entire database, Humio uses time- and metadata-selection to reduce the problem space. We further enhance our brute-force searching by using principles of mechanical sympathy to decrease processing time, speed up the search by compressing data, and pull data from cached memory whenever possible. An optimized brute-force search with Humio can run at 30-40x the speed of a regular search!How brute-force search becomes fast
- Normal time to search 1 GB of data from a drive takes
1.1 seconds - If you compress the data by 10x, it takes less time to search, so it now takes
0.7 seconds - Add more cores - split data into four cores of 256 MB and it takes less time:
0.225 seconds - Divide your data bunches into single MB chunks of decompressed data rather than 256 MB. Move compressed data from the main memory to the CPU, and use CPU cache so you don’t have to scan it in again from main memory. Now it only takes
0.1265 seconds - In practice, you’re often searching for current and recent data that can be kept in the page cache, so you can get search times down to
0.0265 seconds,
which is 30-40x speed of a normal search!
Why Humio uses brute-force search
The need to make streaming data instantly searchable creates a need for brute-force searching. Streaming data querying happens near-instantly, giving you no time to apply complex indexes that could make searching faster. To search streaming and historical data at fast speeds, we bring in optimized brute-force searching. Many conventional log management systems that heavily index will search faster thantypical
brute-force searching, but not faster than Humio’s optimized brute-force search. And by heavily indexing, many of these conventional logging systems sacrifice streaming access to their data.
How we reduce the problem space
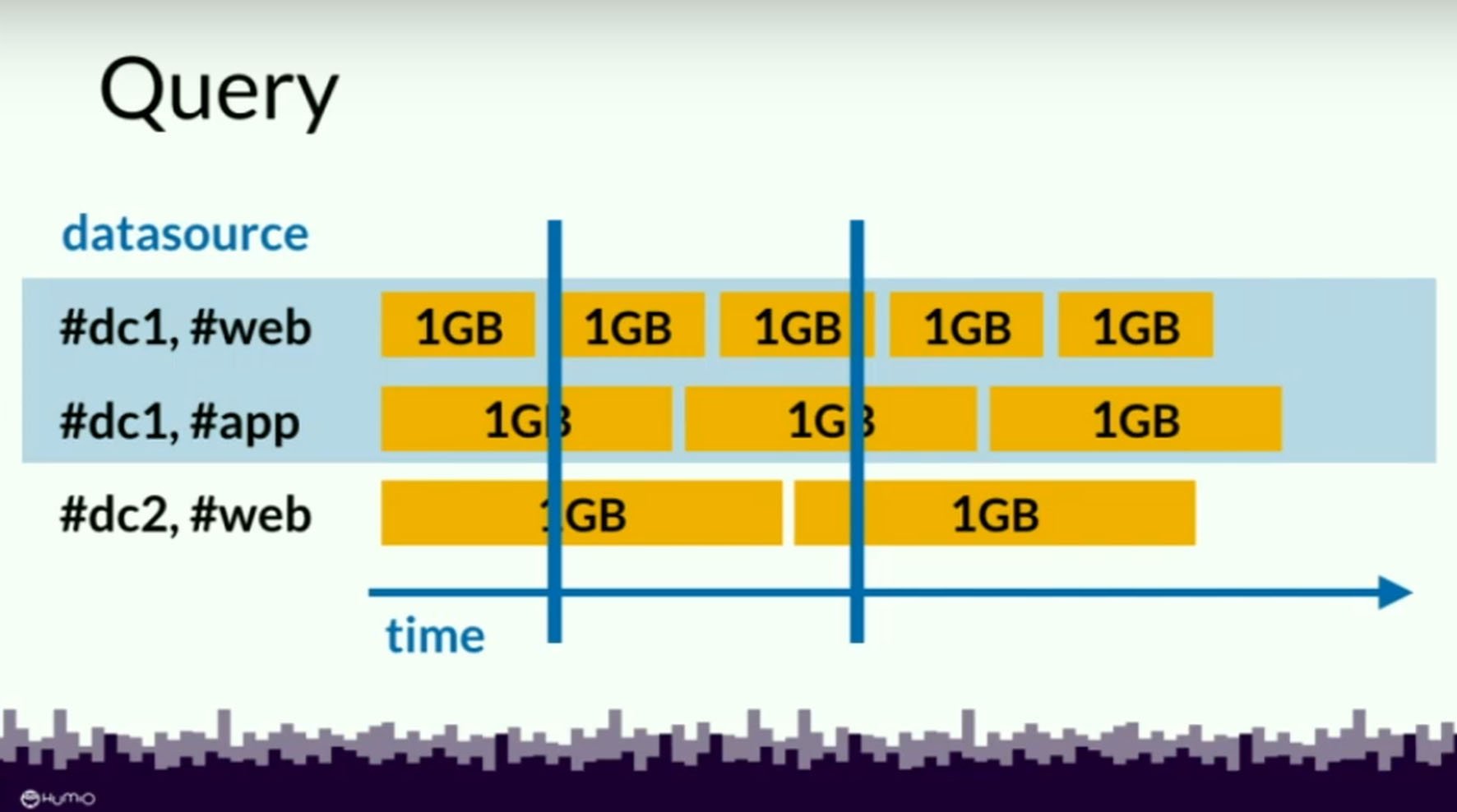 We don’t brute-force search all of our data! We use time ranges to reduce the problem space, allowing us to target 1 GB segments of data that fall within our range. We further reduce the data set by using Bloom filters, designed to efficiently determine whether an element definitely is not in the set.
We don’t brute-force search all of our data! We use time ranges to reduce the problem space, allowing us to target 1 GB segments of data that fall within our range. We further reduce the data set by using Bloom filters, designed to efficiently determine whether an element definitely is not in the set.
We do index...but just barely
While we consider Humio to be index-free, we do index time series information so all ingested data can be found based on its time. The index information is small enough that it can be stored in memory on nodes in the cluster. Each 10 GB chunk has an index entry. To store 30 GB of logs for a month, we have an index file that’s less than 1 MB. The indexing is so minimal, it doesn’t slow down the ingest process, nor does it vary much when ingesting massive amounts of data. One month of storage of 1 TB of logs also has an index file that’s less than 1 MB! Since our index information is kept in memory, it doesn’t create any additional strains on the processes on ingesting or accessing data. Conventional indexed databases can’t claim that.Getting the benefits of Kafka
We aren’t masochists. We aren’t using brute-force to make our jobs harder. We use brute-force because it makes our jobs easier by enabling us to use the Kafka streaming platform. Kafka’s reliability and customizability features protect against crashes and facilitate high-speed data processing. They made it worthwhile to develop brute-force methods for dealing with historical search.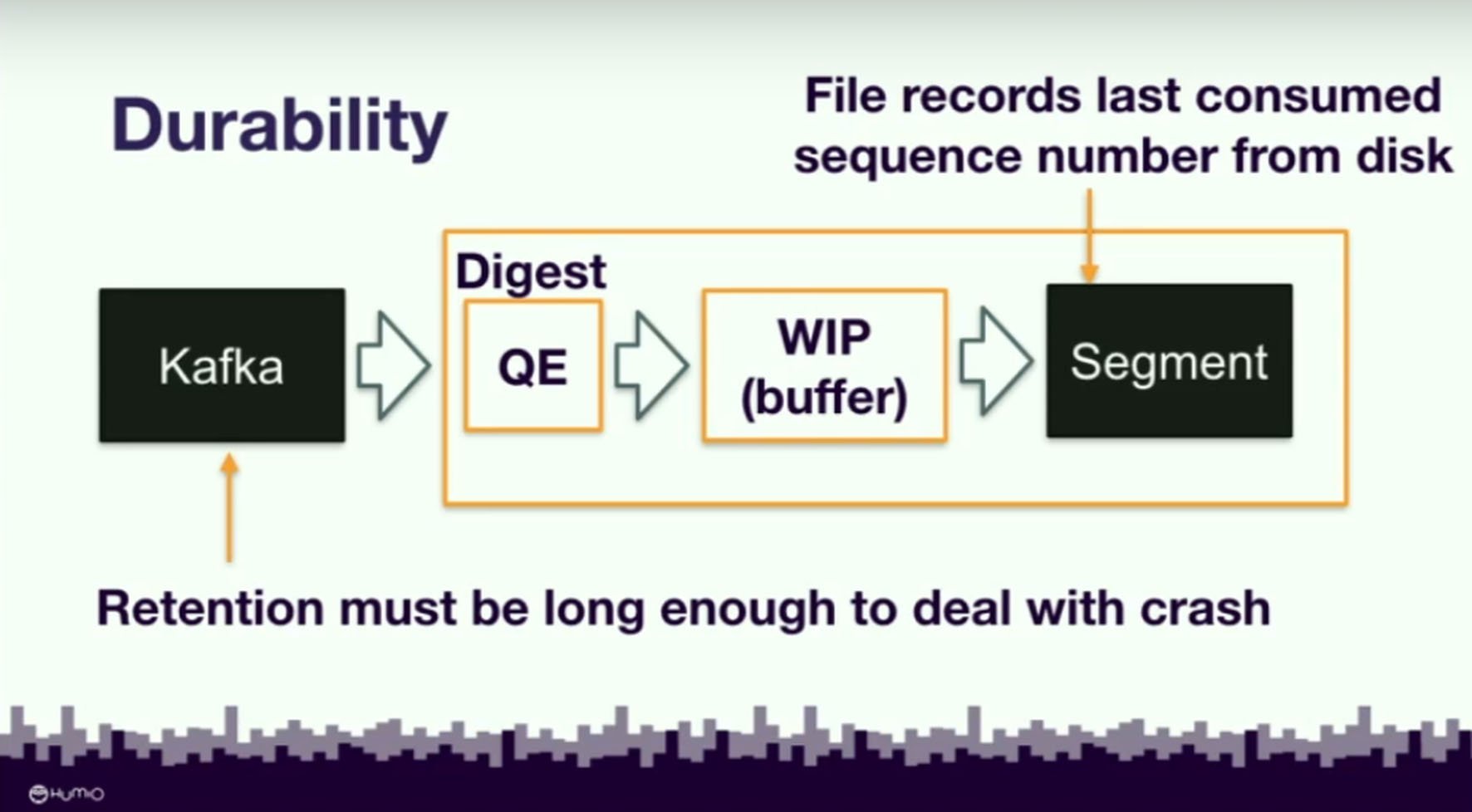 Kafka enables us to process data in a compressed form, which lets us keep it in memory longer, greatly reducing data transfer loads.
In Kafka, it’s easy to create new partitions to store a lot of data. It’s easy to scale out the number of consumers to do processing. These are two areas that are classically bottlenecks in large-scale data processing. Using Kafka liberates our data from both.
Kafka is also a highly stable way of processing data in real time. If the digest system crashes, it keeps running smoothly by reading the last segment number of the data before the commit marker. If we lose work in progress, we can read the last segment number we go back and we reread what we lost from the Kafka queue.
Kafka enables us to process data in a compressed form, which lets us keep it in memory longer, greatly reducing data transfer loads.
In Kafka, it’s easy to create new partitions to store a lot of data. It’s easy to scale out the number of consumers to do processing. These are two areas that are classically bottlenecks in large-scale data processing. Using Kafka liberates our data from both.
Kafka is also a highly stable way of processing data in real time. If the digest system crashes, it keeps running smoothly by reading the last segment number of the data before the commit marker. If we lose work in progress, we can read the last segment number we go back and we reread what we lost from the Kafka queue.
