





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)








































Let's face it. The information security industry loves a new acronym. For industry long-timers, a new acronym might be just the latest reason for an eye roll. For folks new to the field, it can be very confusing. A constructive way to look at XDR — extended detection and response — is as an opportunity to take a fresh look at some old problems and gain clarity. CrowdStrike CTO Mike Sentonas recently made a crucial observation that at the end of the day, we need to understand the customer problem XDR is trying to solve. With this fresh perspective, let's dig a little deeper to see what problems we should be addressing with XDR.
More than Just More Data
A basic phrase that seems to underlie the majority of definitions of XDR in the security industry is "more data." In other words, don't rely just on endpoint data, don't rely on just firewall data, don't rely on just email data, etc. Synthesize all available data in order to construct a comprehensive and coherent view of your environment.This is easier said than done. After all, security information and event management (SIEM) is a decades-old approach to exactly this problem. If nothing else, we as an industry have learned a great deal in the intervening time about the increasing complexity of data source: conflicting data, redundant data, data that comes in different formats, data that arrives with different amounts of delay, widely varying and bursty data volumes, and various other challenges. Resolving all of these issues is challenging, to say the least.
Search: A Powerful Foundation
During a presentation at CrowdStrike’s Fal.Con 2021 cybersecurity conference, Zeki Turedi, CrowdStrike CTO-EMEA, provided some helpful context for defining XDR with special emphasis on what XDR is not. He shared, for example, that simply adding network data, SIEM capabilities, or orchestration to existing endpoint detection and response (EDR) does not amount to an effective XDR. Search is another capability that by itself is not a true XDR solution but is an important foundational function. What we can do with disparate and unreconciled data with the least effort is search. CrowdStrike's Humio search technology provides this foundational XDR capability. Got a known bad IP address and you want to search all of your logs to see where it's popped up recently?That's a job for search. The importance of search is that it frees us from always needing costly data reconciliation. There are always new data sources and changes to existing ones. Search is there to provide value without needing upfront work. But retrospective search capabilities cannot meet all needs.
In short, if all XDR amounts to "search," then XDR wouldn’t be anything new at all. But XDR should mean something more. And in the vision we propose, XDR is about addressing semantic gaps. XDR should not just about consuming "more data" but also about dealing with problems like missing data, reconciling contradictory data from different data sources, and reconciling entity aliases, all in an environment where the data represents many changes over short time spans.
These problems increase with the aggregation of different data sources. More data, by itself, is not a solution, but instead presents a host of challenges that must be solved in order to use that data to solve real-world customer problems. Ultimately, ingesting the right data is more important than ingesting all data.
An Intrusion Scenario to Illustrate the Data Challenge
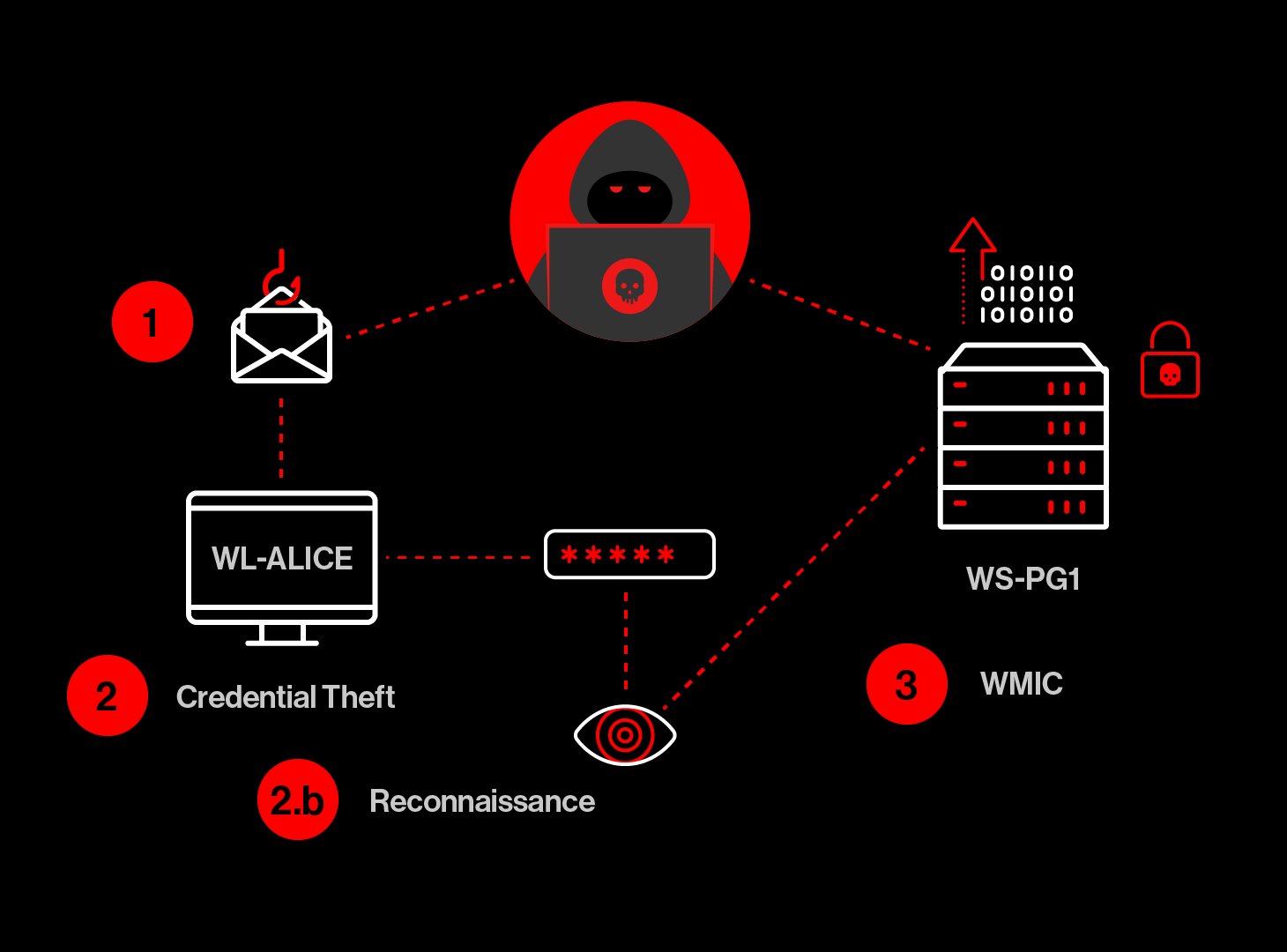
To help illustrate the challenges, let's consider a hypothetical intrusion. This intrusion starts with a phishing email to user Alice on her laptop, WL_ALICE. The attacker obtains control over Alice's user account on that laptop and also obtains her AD password by dumping host credentials. The attacker then performs some light reconnaissance and uses wmic.exe to create a shell on a remote database server, WS_PG1, to which user Alice has access and exfiltrates valuable data from that server.When Search Hits Its Limits
In the intrusion scenario outlined above, EDR alerts or hunting leads from WS_PG1 might lead a SOC team to notice that user Alice recently logged onto the host. That's useful information but doesn't yet tell the team from which host Alice logged in. Most likely, the endpoint data contains the IP address of the remote host. Perhaps that identifier can be used to determine the source host of the lateral movement. So we have data in a data lake that we can comb through to try and find the host to which the IP address was assigned. We need to correlate the IP address in such a way that we have other information about it — perhaps its hostname, which would help us identify it as Alice's laptop. If we can determine its canonical Falconidentifier, its agent identifier (AID), then we can get its hostname and lots of other useful context to better understand this intrusion. Obtaining this information via search means searching for AIDs that have had the IP address of interest assigned to them. But this is easier said than done. If we were to perform a search to find the AID for an IP address for every possible indication of lateral movement, we would quickly overload our search mechanism with redundant searches.
For every suspicious login that involves the IP address above, we would rediscover through each search that the address is currently assigned to WL_ALICE, and in a rather expensive way. At analyst time scales, this is not too problematic. But if we want to create this as a standing query, automating the query means that we need to pay close attention to scale.
Joins: Powerful but Expensive
This kind of "pivot" from one entity (WS_PG1) to another entity (WL_ALICE) via some identifier that unifies data between the two — in this case, the IP address — is called a "join" in traditional search terms. Joins can be expensive computationally and in the amount of required memory, and if you think about all of the elements of an intrusion, the importance and cost of joins quickly become apparent. To underscore the scope of the problem, consider that we have not yet looked at the initial phishing email component of the attack, which requires yet another join. To pin down the source of this intrusion to the email received by Alice, we need to recognize that Alice is identified not just by her Alice username in Active Directory, but also by her email address, alice.rosencrantz@example.com. Data about the email might come from another source like the company's Exchange server, or from a spam filter. We need some data that ties Alice's username and email address, and both of these to WL_ALICE. It is quickly becoming apparent that even in this simple scenario, multiple potentially expensive joins are required, and that search, though useful and powerful, is not a panacea. It is not feasible to rely on search to answer all of our security-relevant questions in all cases. Also, how far back should the search go? The longer the timespan of data search, the costlier it becomes.But the shorter the duration, the less likely it will be that I can find the data that tells me which host is assigned the source IP address. The importance of being able to do highly efficient joins was a central reason behind the reason CrowdStrike built the CrowdStrike Threat Graph®, which in a sense allows us to store data in "pre-joined" fashion. There is increasing buzz about the importance of graphs in information security today, and we at CrowdStrike are pleased to see broader recognition of the importance of graphs as a central component in security information architectures. Storing data in graphs is one way to build the data structures that address semantic gaps in ways that aren't feasible with traditional data search methods. To underscore the complications encountered in real-world data, let's look at some real data that demonstrates just how sticky a seemingly simple question like "Which host has this IP address?" really is.
Identifiers: What's in a Name?
IP addresses are often depicted in movies as being the way we can identify which system an attack originated from, but the reality is much more complicated. IP addresses are frequently reassigned. Taking your laptop to a meeting in a conference room is likely to cause your system to get another IP address assigned. In fact, your laptop is likely to have multiple IP addresses:one for your primary interface, one for a VPN, and possibly more, such as if you've still got a hardwired docking station. Network Address Translation (NAT) makes it completely legitimate that you might find multiple subnets in your organization that share the same class C prefix, meaning that multiple endpoints might simultaneously share the same IP address. The situation is even more complicated in different kinds of server environments. We were able to find an extreme end of this spectrum in live data with little effort. In the first case observed, we found two IP addresses that were assigned to nearly 1,000 distinct hosts in a little over a second. The underlying cause of this behavior was normal business activity, essentially reflecting the initialization of a Kubernetes IPVS Pod constituting a single logical server host backed by many homogenous server instances.
Resolving Identifiers Using Entity Resolution
In general, there are many kinds of data and many different entities involved in information infrastructure — such as users, hosts, load balancers, switches and routers — and many different ways of identifying them, like email addresses and usernames, IP and MAC addresses, hostnames, etc. The terms we use are "entity resolution" (determining what constitutes an entity and how we resolve the different possible ways that entity might be identified) and "entity modeling" to refer more broadly to how we represent complex entities. One of the more sophisticated examples of resolving entity identity in the CrowdStrike Falcon®® platformtoday occurs in the lateral movement detection of the CrowdStrike CrowdScore™ engine. If a logon event occurs, the IP address or hostname (depending on what data is available) is used to look up the remote endpoint(s) to which it recently appears to be assigned. When malicious activity occurs, the source entity (or host in this case) has indicator evidence of the activity according to the CrowdScore engine, and this can be thought of as an increased level of suspicion that an observed logon was likely to have originated from the endpoint where prior malicious activity occurred.
This method is highly accurate and significantly reduces the false positive entity resolutions that might be presented if we did not reconcile logons against CrowdScore data. In other words, if one host exhibits signs of malicious activity, we can have higher confidence that observed lateral movement from its IP address occurred from that particular host, despite many other hosts sharing the same IP address. And this kind of approach works well even in a situation like the Kubernetes IPVS Pod case outlined above. Efficiently reconciling data from multiple data sources means having a robust solution to the entity resolution problem. So if you see a solution claiming to provide XDR, compare that solution’s capabilities against how CrowdScore's lateral movement detection addresses the entity resolution problem.
XDR Must Provide a Richer Model
There are lots of lessons to learn digging into the "Have I seen lateral movement to this host?" question, but we'll highlight one in this post. To understand our environment, we need to understand the pieces, and our solutions need to understand those pieces. In the Kubernetes IPVS case, for example, we need to recognize that in most circumstances, all of the endpoints receiving the same IP address are really part of the same logical endpoint. We wouldn't expect to find a vulnerability on one and not the others. We wouldn't want to patch one and not the others. On the other hand, if malicious activity occurs, it could very well happen on one endpoint without also happening on the others. It is challenging to build models that provide the required level of flexible contextual understanding of an environment. Solutions that provide a rich model need to be a central focus of XDR. More data provides more opportunity for redundant checking of data, the filling in of missing gaps, and the building of a cohesive model that can express the nuances that arise in the real world, like the relationship between a proxying load balancer, a pod and its constituent endpoints — collectively, a unified logical endpoint sharing an IP address. In the simplest terms, the goal of XDR should be to better address semantic gaps.A New Vision to Address InfoSec Challenges
On the surface, it can sound as if "extending" detection and response to incorporate other data beyond the endpoint is a no-brainer for taking security to the next level. But the addition of different data sources on its own does little to address the hardest problems facing us in the information security problem domain. One useful way to think about XDR is as a fresh perspective from which to clarify some of the remaining challenges in the information security domain. When considering solutions that all claim to provide XDR, a good question to keep in mind is how that solution addresses the challenges of semantic gaps.Additional Resources
- Learn more about CROWDSTRIKE FALCON® XDR and the CrowdXDR Alliance.
- Learn how the powerful CrowdStrike Falcon® platform provides comprehensive protection across your organization, workers and data, wherever they are located.
- Get a full-featured free trial of CrowdStrike Falcon® Prevent™ and see for yourself how true next-gen AV performs against today’s most sophisticated threats.