機械学習とは
機械学習 (ML) は、人工知能 (AI) のサブセットであり、既存のデータからパターンを学習し、新しいデータを基に回答を予測するようアルゴリズムに指示するプロセスを指します。
AIとMLという用語は区別なく使用されることが多いですが、この2つの概念には重要な違いがあります。AIは、実際の環境における人間のインテリジェンスプロセスを模倣またはシミュレーションするように機械をトレーニングする技術のことです。一方MLは、その結果作成された、データから学習して予測を行うコンピューターシステム(「モデル」)を指します。
つまり、「学習」とは、正確な予測を行うためにモデルが数学関数をマッピングして、基になるデータを変換するプロセスを指します。コンピューターは、明示的にプログラムされた命令または連鎖した命令に従って、単純で予測可能なタスクを実行するようにプログラムすることができます。一方、MLモデルは問題を解決するための一般化されたアプローチを開発します。
機械学習の3つのタイプ
この記事では、機械学習の一般的な3つのクラスを見ていきます。
1. 教師あり学習
教師あり学習では、ラベル付けされた入力と必要な結果を基にモデルがトレーニングされます。その目的は、新しいデータやよく知らないデータが提示された場合に、タスクを実行するようにモデルを教育することです。サイバーセキュリティにおける教師あり学習の一般的な利用法には、無害なサンプルと悪意のあるサンプルを基にモデルをトレーニングして、新しいサンプルが悪意のあるものかどうかを予測できるように教育するというものがあります。
2. 教師なし学習
教師なし学習では、ラベル付けされていないデータを基にモデルをトレーニングし、クラスターやグループなどの構造やパターンをデータの中から検出させます。サイバーセキュリティにおいては、大量のデータプールの中から新しい攻撃パターンや攻撃者の振る舞いを明らかにする(異常検知など)ために使用できます。
3. 強化学習
強化学習は、モデルにラベル付きの入力や出力を与えず、代わりに、累積報酬を最大化することを目的として、試行錯誤を通じてモデルに学習させるものです。この形式の機械学習は、人間の学習方法を非常に厳密に模倣します。これは、問題を解決するための創造的な方法や革新的な方法を見つけるために特に役立ちます。サイバーセキュリティにおける強化学習の利用法には、サイバーフィジカルシステム、自律型侵入検知、分散型サービス拒否 (DDOS) 攻撃などのソリューションがあります。
サイバーセキュリティにおける機械学習の利点
サイバーセキュリティ分野の問題に機械学習を応用することには多くの利点があります。例えば、次のようなものがあります。
1. 大量のデータを迅速に合成する:アナリストが直面する最大の課題の一つは、攻撃対象領域から生成されるインテリジェンスを迅速にまとめる必要があることです。これらは通常、チームが手動で処理できる速度をはるかに超えた速度で生成されます。機械学習は、大量の過去のインテリジェンスや動的インテリジェンスを迅速に分析できるため、チームはさまざまなソースからのデータをほぼリアルタイムで実用化できます。
2. 専門家のインテリジェンスを大規模に有効化する:定期的なトレーニングサイクルによって、モデルは進化するサンプル母集団から継続的に学習することができます。これには、アナリストがラベル付けした検知内容やアナリストがレビューしたアラートが含まれます。これにより、フォールスポジティブを繰り返し検知することが防がれ、専門家が生成したグラウンドトゥルースをモデルが学習し、適用できるようになります。
3. 繰り返し行う手動タスクを自動化する:特定のタスクに機械学習を適用することで、日常的に繰り返し行うタスクからセキュリティチームを解放できます。その結果、受信するアラートへの対応を拡大でき、複雑な戦略的プロジェクトに時間とリソースを振り分けられるようになるなど、チームの成果が倍増します。
4. アナリストの効率を高める:機械学習は、リアルタイムの最新インテリジェンスでアナリストのインサイトを増強し、脅威ハンティングやセキュリティ運用を行うアナリストがリソースに効果的に優先順位を付けて、組織の重大な脆弱性に対処し、MLから通知された、早急な対応が必要な検知内容を調査できるようにします。
サイバーセキュリティにおける機械学習のユースケース
サイバーセキュリティ分野における機械学習のユースケースにはさまざまなものがあり、拡大し続けています。これらのユースケースは、次の2つの主なグループに分類することができます。
- 自動の脅威検知と対応
- 機械学習が支援するアナリスト主導の運用
自律型の脅威検知と対応
最初のカテゴリでは、機械学習によって組織の手動作業を自動化できます。特に、自動の脅威検知と対応や新しい攻撃者パターンの分類など、高い精度を維持し、機械と同等の速度で対応する必要があるプロセスでの手動作業を自動化します。
このようなシナリオに機械学習を適用すると、シグネチャベースの脅威検知方法が、無害なサンプルと悪意のあるサンプルの違いを学習して、新しい「In-the-Wild(実際に感染報告がある)」脅威を迅速に検知できる、一般化されたアプローチで補強されます。
機械学習によるアナリストの効率向上
機械学習モデルは、検知内容を調査するようにチームに通知し、脆弱性に対するパッチ適用の優先度を示すことで、アナリスト主導の調査を支援することもできます。アナリストによるレビューは、モデルが高い確度で結果を予測するために十分なデータがない場合や、マルウェア分類器では検知されない可能性がある、無害に見える振る舞いを調査する場合に特に有用です。
その他のサイバーセキュリティにおける機械学習のユースケース
以下に、サイバーセキュリティ分野での機械学習の一般的な利用方法を示します(すべてを網羅しているわけではありません)。
| ユースケース | 説明 |
|---|---|
| 脆弱性管理 | ITおよびセキュリティチームにとっての重要度に基づいて推奨される脆弱性の優先度を示す |
| 静的ファイル分析 | ファイルの特徴に基づいて悪意のあるファイルかどうかを予測することで、脅威防御を可能にする |
| 振る舞い分析 | ランタイム時の攻撃者の振る舞いを分析して、サイバーキルチェーンにおける攻撃パターンをモデル化し、予測する |
| 静的および振る舞いのハイブリッド分析 | 静的ファイル分析と振る舞い分析を組み合わせて、高度な脅威検知を提供する |
| 異常検知 | データの異常を特定して、リスクのスコア決定に情報を提供し、脅威を調査するように指示する |
| フォレンジック分析 | カウンターインテリジェンスを実施して攻撃の進行度を分析し、システムの脆弱性を特定する |
| Sandboxマルウェア分析 | 隔離された安全な環境でコードサンプルを分析し、悪意のある振る舞いを特定して分類するとともに、それらを既知の攻撃者に対応付ける |
機械モデルの有効性の評価
マルウェア分類のモデルの有効性:
サイバーセキュリティにおけるMLの最も一般的な利用方法の一つは、マルウェアの分類です。マルウェア分類器は、特定のサンプルが悪意のあるものであるかどうかについて、スコア付けされた予測を出力します。「スコア」とは、生成された分類に関連付けられている信頼度を指します。これらのモデルのパフォーマンスを評価する方法の一つは、精度(出力が正しく分類されたかどうか:「トゥルー」または「フォールス」)と出力(モデルがサンプルに割り当てたクラス:「ポジティブ」または「ネガティブ」)の2つの軸で予測を表すことです。
このフレームワークにおける「ポジティブ」と「ネガティブ」という用語は、サンプルがそれぞれ「無害」または「悪意がある」ことを意味するわけではないことに注意してください。マルウェア分類器が「ポジティブ」な検知を行った場合、これはモデルが既知の悪意があるサンプルに関連付けるように学習している、観測された特徴に基づいて、特定のサンプルが悪意があるものであると予測したことを示しています。
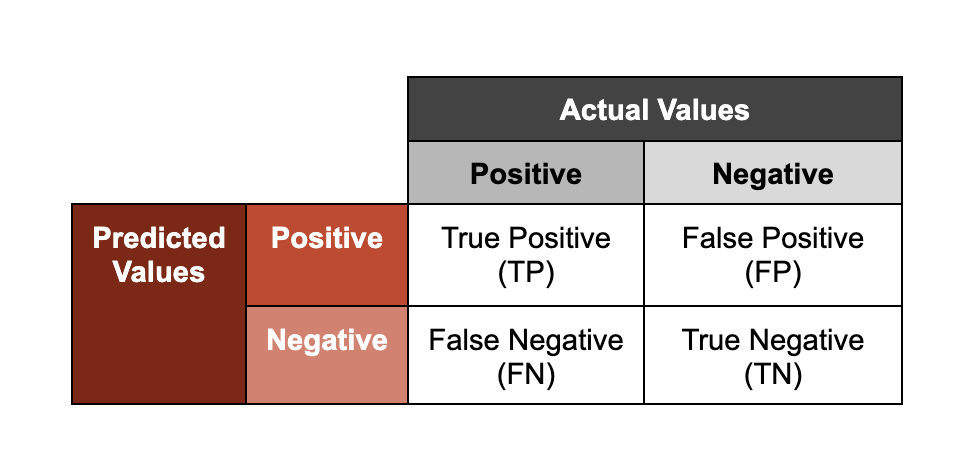
これらのグループの意味を説明するために、悪意のあるファイルを分析するようにトレーニングされたモデルの例を使用します。
- トゥルーポジティブ:モデルはファイルが悪意のあるものであることを正しく予測した
- トゥルーネガティブ:モデルはファイルが悪意のあるものでないことを正しく予測した
- フォールスポジティブ:モデルはファイルが悪意のあるものであると誤って予測した(実際は悪意のないファイル)
- フォールスネガティブ:モデルはファイルが悪意のあるものでないとを誤って予測した(実際は悪意のあるファイル)
トゥルーポジティブとフォールスポジティブのバランス
トゥルーポジティブは脅威検知と対応にとって必要不可欠ですが、フォールスポジティブもモデルのパフォーマンスの重要な指標となります。フォールスポジティブでは、各検知項目をセキュリティチームが調査する時間とリソースに関連する機会コストが生じます。特に、フォールスポジティブによって、組織の運用にとって重要なアプリケーションをブロックまたは中断する自動修復プロセスがトリガーされる場合は多大なコストが生じる可能性があります。
データサイエンティストはモデルの積極性や感度を調整する際、トゥルーポジティブ率とフォールスポジティブ率の両方を最適化する必要があるため、深刻なトレードオフに直面します。これは、トゥルーポジティブのしきい値(つまり、モデルがサンプルを「ポジティブ」と分類するために満たす必要がある要件)を下げると、フォールスポジティブのしきい値も下がる(これにより、アナリストの生産性が失われ、アラート疲れが悪化する可能性があります)というリスクが生じるというものです。このトレードオフを検知の有効性と呼びます。
パフォーマンスの高い機械学習モデルを作成する際の最終目標は、検知の有効性を最大化すること:つまり、トゥルーポジティブの検知を最大化しながらフォールスポジティブを最小限に抑えることです。このバランスの複雑さを説明するには、マルウェア分類器では、トゥルーポジティブ率が99%またはそれに近い値になることは珍しくなく、それとバランスを取るにはフォールスポジティブ率は1%をはるかに下回ることを考えてみてください。
機械学習の課題と制約
機械学習モデルは強力なツールかもしれませんが、あらゆるモデルの動作には独自の制約があります。
十分な高品質データ:確度の高いモデルをトレーニングするには、一般に、機械学習モデルのトレーニングとテスト両方のために大量のデータセットが必要になります。モデルをテストする際には、モデルのパフォーマンスのテスト用に、データのサブセットをトレーニング用のセットとは分けておくのが一般的です。このデータとトレーニングデータでは、重複する特徴が最小限である必要があります。例えば、データ収集の異なる期間を代表するものである、または異なるデータソースから取得されたものであるなどです。高品質データが十分にない場合、その問題空間は適用される機械学習に適したシナリオではない可能性があります。
トゥルーポジティブとフォールスポジティブの間のトレードオフ:前述したように、検知の有効性を最大化するためには、トゥルーポジティブとフォールスポジティブの検知のしきい値のバランスを考えて各モデルの感度を調整する必要があります。
説明可能性:説明可能性とは、モデルがそのようなパフォーマンスを示している理由とその仕組みを説明できることを言います。これによりデータサイエンスチームは、モデルのパフォーマンスに影響しているサンプルの特徴と、特徴の相対的な重みを理解できます。説明可能性は、説明責任の推進、信頼の構築、データポリシーのコンプライアンスの確保、そして最終的に、機械学習における継続的なパフォーマンスの向上を可能にするために重要です。
反復性:再現性とも言います。これは、機械学習の実験を一貫して再現できることを指します。反復性は、機械学習がどのように使用されているか、使用されているモデルの種類、トレーニングに利用しているデータ、モデルが動作しているソフトウェアの環境またはバージョンに関する透明性を高めます。反復性がある場合、モデルがテストから展開に移行したとき、および将来の更新サイクルにおいて、曖昧さと潜在的なエラーが最小限に抑えられます。
ターゲット環境の最適化:各モデルは、そのターゲットとなる本番環境に合わせて最適化する必要があります。各環境は、計算リソース、メモリ、接続の使用可能性がそれぞれ異なります。続けて、ターゲットホストの運用に負荷をかけたり、中断したりせずに、その展開環境で実行できるように各モデルを設計する必要があります。
敵対的な攻撃に対する強化:機械学習モデルには、攻撃者による攻撃に対して脆弱になる可能性がある独自の攻撃対象領域があります。攻撃者はこの領域で、モデルの振る舞いの悪用や改ざんを試みます(モデルにサンプルを誤分類させるなど)。モデルの悪用可能な攻撃対象領域を最小限にするために、データサイエンティストはトレーニングでモデルを「強化」して、堅牢なパフォーマンスと攻撃に対する回復力を確保します。
2 機械学習に関する誤解
誤解1:機械学習は従来の分析手法や統計手法よりも優れている
機械学習は非常に効果的なツールかもしれませんが、すべての問題空間での使用に適しているわけではありません。他の分析手法や統計手法のほうが、機械学習アプローチよりも高い精度を示すことや、効果的な結果を生成することもありますし、リソース消費量が少ないこともあります。また、特定の問題空間により適したアプローチであることもあります。
誤解2:機械学習はできるだけ多くのタスクを自動化するために使用すべきである
機械学習は非常に多くのリソースを消費する可能性があり、一般に、モデルを構築、トレーニング、保守するために、大量のデータ、計算リソース、専用のデータサイエンスチームを使用できる必要があります。モデルの保守に対するROIを最大化するためには、対象の問題の価値が高く、頻繁に繰り返され、速度と正確性が必要で、継続的なトレーニングとテストのために十分な量の高品質データセットがある場合に、モデルを適用するのが最適です。
機械学習に対するクラウドストライクのアプローチ
クラウドストライクでは、CrowdStrike Falcon®プラットフォーム全体で機械学習を適用し、高度な脅威保護を提供しています。
CrowdStrike Security Cloudの比類のないインテリジェンス:
クラウドストライクのモデルは、CrowdStrike Security Cloudの豊富なテレメトリを基にトレーニングされています。このモデルは、CrowdStrike® Asset Graph™、CrowdStrike Falcon® Intel Graph、および特許取得済みのCrowdStrike Threat Graph®における何兆個ものデータポイントを関連付けて、比類のない可視性を実現し、組織の攻撃対象領域全体で脅威インテリジェンスを絶えず改良しています。
このようにナレッジが拡充されることで、クラウドストライクの脅威ハンティングチーム(Falcon OverWatch™)、Malware Research Center、およびMDRチーム(Falcon Complete™)などの、クラウドストライクの専門家チームが生成するグラウンドトゥルースのコーパスは拡大され続けます。
人間の専門知識の強化:
クラウドストライクのモデルは、自律型の脅威検知と対応を促進するだけでなく、脅威ハンティングやITとセキュリティの運用といった専門家が主導する分野において人間の専門知識を強化します。Falconプラットフォーム全体で動作する機械学習モデルは、検知と対応を自動化し、高精度の機械学習が検知を通知することでアナリストの効率を最大限に高め、プロアクティブな防御のための脆弱性管理の推奨事項をインテリジェントに提案する(Falcon Spotlight™のExPRT.AIモデルを使用)、次世代のアナリストワークベンチを提供します。
多層防御:
クラウドストライクでは、Falconプラットフォーム全体で機械学習を活用し、プロセスのライフサイクル(実行前、ランタイム時、実行後)全体にわたって堅牢な多層防御を提供しています。実行前は、オンセンサーおよびクラウドベースの機械学習モデルが同期的に動作して、脅威を自動的に検知して対応します。これは、軽量のFalconエージェントにとって堅牢な最初の防御線となります。クラウドおよびオンセンサーの機械学習モデルは常に同期されているため、オンセンサーで検知された内容を攻撃対象領域にグローバルに適用することができます。同様に、クラウドベースのモデルで検知された内容は保護されているすべてのエンドポイントに瞬時に適用することができます。
このアプローチを強化するために、クラウドストライクではランタイム時に高度な振る舞い分析も適用しています。クラウドベースのモデルを使用して、エンドポイントのイベントを分析し、攻撃の痕跡 (IOA) を分類します。AIを活用したIOAは、使用されているマルウェアやツールにかかわらず、新たな脅威を能動的に検知し、オンセンサーモデルと非同期的に動作して、リアルタイムの脅威インテリジェンスに基づいて疑わしい振る舞いのローカル分析をトリガーします。
実行後は、振る舞いの痕跡を使用して、組織の攻撃対象領域における異常な活動を評価します(CrowdStrike CrowdScore™メトリックで示されます。これは、組織の脅威レベルに関するリアルタイムの指標となります)。振る舞いの痕跡は、Falcon OverWatchによって、ハンズオンキーボード活動、サイバー犯罪 (eCrime)、ステルス型攻撃などの高度な脅威を調べるためにも使用されます。
ルシア・スタンハムは、クラウドストライクのプロダクトマーケティングマネージャーとして、サイバーセキュリティにおけるエンドポイント保護 (EDR/XDR) とAIを担当しています。2022年6月よりクラウドストライクに勤務しています。
