O que é machine learning?
Machine learning (ML) é um subconjunto da inteligência artificial (IA) e se refere ao processo de ensinar os algoritmos a aprender padrões de dados existentes para prever respostas sobre novos dados.
Embora os termos IA e ML sejam frequentemente usados de forma intercambiável, há diferenças importantes entre os dois conceitos. IA refere-se à tecnologia que treina máquinas para imitar ou simular processos de inteligência humana em ambientes do mundo real, enquanto ML refere-se aos sistemas de computador resultantes ("modelos") que aprendem com dados para fazer previsões.
Em essência, "aprendizagem" refere-se ao processo no qual os modelos mapeiam funções matemáticas para transformar dados subjacentes a fim de fazer previsões precisas. Enquanto os computadores podem ser programados para executar tarefas simples e previsíveis seguindo instruções explicitamente programadas ou encadeadas, os modelos de ML desenvolvem uma abordagem generalizada para a solução de problemas.
Três tipos de machine learning
Neste artigo, vamos analisar as três classes comuns de machine learning:
1. Aprendizagem supervisionada
A aprendizagem supervisionada ocorre quando um modelo é treinado com entradas rotuladas e resultados desejados, e o objetivo é ensiná-lo a desempenhar uma tarefa quando são apresentados dados novos ou desconhecidos. Na cibersegurança, um uso comum dessa aprendizagem é para treinar modelos sobre amostras benignas e maliciosas, a fim de ensiná-los a prever se novas amostras serão maliciosas.
2. Aprendizagem não supervisionada
A aprendizagem não supervisionada ocorre quando um modelo é treinado com dados não rotulados e deve encontrar estrutura, relações e padrões nos dados, como clusters ou agrupamentos. Na cibersegurança, isso pode ser usado para revelar novos padrões de ataque ou comportamentos do adversário (por exemplo, detecção de anomalias) em grandes pools de dados.
3. Aprendizagem por reforço
A aprendizagem por reforço ocorre quando um modelo não recebe entradas ou saídas rotuladas. Em vez disso, aprende por meio de tentativa e erro, visando maximizar uma recompensa cumulativa. Essa forma de machine learning imita de perto como a aprendizagem humana ocorre, sendo especialmente útil para identificação de formas criativas e inovadores de solucionar problemas. Alguns exemplos de aplicações de aprendizagem por reforço na cibersegurança são: soluções para sistemas cibernéticos-físicos, detecções de intrusões autônomas e ataques de negação de serviço distribuídos (DDoS).
Benefícios do machine learning em cibersegurança
Há muitos benefícios no uso de machine learning para problemas na área de cibersegurança, incluindo:
1. Sintetizar rapidamente grandes volumes de dados: um dos maiores desafios enfrentados pelos analistas é a necessidade de sintetizar rapidamente a inteligência gerada na superfície de ataque, que normalmente é gerada com muito mais rapidez do que suas equipes conseguem processar manualmente. O machine learning analisa rapidamente grandes volumes de inteligência histórica e dinâmica, permitindo que as equipes operacionalizem dados de várias fontes quase em tempo real.
2. Ativar a inteligência especializada em escala: ciclos regulares de treinamento habilitam modelos para aprender continuamente com sua crescente população de amostra, o que inclui detecções rotuladas por analistas ou alertas revisados por analistas. Isso impede a recorrência de falsos positivos e permite que os modelos aprendam e apliquem as informações verdadeiras geradas por especialistas.
3. Automatizar tarefas manuais e repetitivas: o uso de machine learning em tarefas específicas pode ajudar a liberar as equipes de segurança de tarefas repetitivas e monótonas, agindo como um multiplicador de força que permite a elas dimensionar sua resposta a alertas recebidos e redirecionar tempo e recursos a projetos complexos e estratégicos.
4. Aumentar a eficiência dos analistas: o machine learning pode aumentar os insights dos analistas com inteligência atualizada e em tempo real, permitindo que as pessoas que trabalham com investigação de ameaças e operações de segurança priorizem recursos para lidar com vulnerabilidades críticas da organização e investiguem detecções de alertas de ML urgentes.
Casos de uso do machine learning em cibersegurança
O machine learning tem uma ampla e crescente gama de casos de uso no espaço da cibersegurança. Podemos pensar nesses casos de uso em duas categorias:
- Detecção e resposta a ameaças automatizadas
- Operações lideradas por analistas com o auxílio de machine learning
Detecção e resposta a ameaças autônomas
Na primeira categoria, o machine learning permite às organizações automatizar o trabalho manual, especialmente em processos em que é fundamental manter altos níveis de precisão e responder com velocidade comparável à da máquina, como detecção e resposta automáticas a ameaças ou classificação de novos padrões de adversários.
O uso de machine learning nesses cenários amplia os métodos de detecção de ameaças baseados em assinatura com uma abordagem generalizada que aprende as diferenças entre amostras benignas e maliciosas e pode detectar rapidamente novas ameaças in the wild.
Aumento da eficiência dos analistas com machine learning
Os modelos de machine learning também podem auxiliar nas investigações lideradas por analistas alertando as equipes para investigar detecções ou enviando vulnerabilidades priorizadas para correção. A revisão por analistas pode ser especialmente valiosa em cenários onde não há dados suficientes para que os modelos prevejam resultados com altos níveis de confiança ou investiguem comportamentos aparentemente benignos que podem passar despercebidos pelos classificadores de malware.
Casos de uso adicionais de machine learning em cibersegurança
Esta é uma lista de exemplos comuns (não exaustiva) de maneiras de usar o machine learning na área de cibersegurança.
| Caso de uso | Descrição |
|---|---|
| Gerenciamento de vulnerabilidade | Fornece priorização recomendada de vulnerabilidades com base na gravidade para as equipes de TI e segurança |
| Análise estática de arquivo | Prevê uso mal-intencionado do arquivo com base em suas características para antecipar ameaças |
| Análise comportamental | Analisa o comportamento do adversário no tempo de execução para modelar e prever padrões de ataque em toda a cyber kill chain |
| Análise comportamental e estática híbrida | Compõe análise de arquivo estática e análise comportamental para oferecer detecção avançada de ameaças |
| Detecção de anomalias | Identifica anomalias nos dados para informar a pontuação de risco e direcionar as investigações de ameaças |
| Análise forense | Realiza contrainteligência para analisar a progressão do ataque e identificar vulnerabilidades do sistema |
| Análise de malware no sandbox | Analisa amostras do código em ambientes isolados e seguros para identificar e classificar comportamentos maliciosos, bem como mapeá-los a adversários conhecidos |
Avaliação da eficácia de modelos de máquina
Eficácia do modelo para classificadores de malware:
Um dos usos mais comuns do ML na cibersegurança é a classificação de malware. Os classificadores de malware geram uma previsão pontuada sobre se uma determinada amostra é maliciosa. A pontuação refere-se ao nível de confiança associado à classificação resultante. Uma maneira de avaliar o desempenho desses modelos é representando previsões ao longo de dois eixos: precisão (se um resultado foi classificado corretamente; "verdadeiro" ou "falso") e saída (a classe que um modelo atribui a uma amostra; "positiva" ou "negativa").
Observe que os termos "positiva" e "negativa" nesse framework não significam que uma amostra seja respectivamente "benigna" ou "maliciosa". Se um classificador de malware fizer uma detecção "positiva", isso indica que o modelo está prevendo que uma determinada amostra é maliciosa, com base na observação de características que ele aprendeu a associar a amostras maliciosas conhecidas.
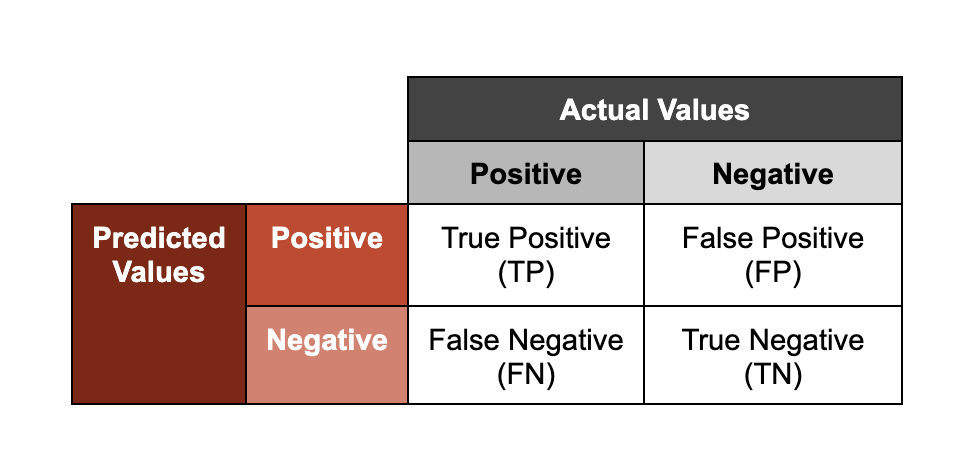
Para ilustrar o que esses agrupamentos significam, vamos usar o exemplo de modelos treinados para analisar arquivos maliciosos.
- Verdadeiro positivo: o modelo previu corretamente que um arquivo era malicioso
- Verdadeiro negativo: o modelo previu corretamente que um arquivo não era malicioso
- Falso positivo: o modelo previu incorretamente que um arquivo era malicioso (não era)
- Falso negativo: o modelo previu incorretamente que um arquivo não era malicioso (era)
Equilíbrio de verdadeiros positivos e falsos positivos
Embora verdadeiros positivos sejam essenciais para a detecção e resposta de ameaças, os falsos positivos também são uma medida importante do desempenho do modelo. Os falsos positivos têm um custo de oportunidade associado ao tempo e aos recursos que as equipes de segurança gastam investigando cada detecção, e pode ser especialmente caro se acionarem processos de remediação automática que bloqueiam ou interrompem aplicações críticas para as operações de uma organização.
Ao calibrar a agressividade ou a sensibilidade do modelo, os cientistas de dados devem otimizar as taxas de verdadeiro-positivos e falsos positivos, com uma compensação crítica: reduzir o limite de verdadeiros positivos (ou seja, os requisitos que precisam ser cumpridos para que um modelo classifique uma amostra como "positiva") traz o risco de também reduzir o limite de falso-positivos (o que pode resultar em perda de produtividade do analista e agravar o excesso de alertas). Chamamos essa compensação de eficácia de detecção.
O objetivo final da construção de modelos de machine learning de alto desempenho é maximizar a eficácia da detecção: maximizar as detecções de verdadeiros positivos e minimizar os falsos positivos. Para ilustrar a complexidade desse equilíbrio, considere que não é incomum que classificadores de malware tenham taxas de verdadeiros positivos de 99% ou próximas a isso, em comparação com taxas de falsos positivos, que ficam bem abaixo de 1%.
Desafios e restrições do machine learning
Embora os modelos de machine learning possam ser ferramentas poderosas, cada um opera dentro de suas limitações únicas:
Dados de alta qualidade suficientes: treinar modelos de alta confiança geralmente requer acesso a conjuntos de dados grandes, tanto para treinar como para testar os modelos de machine learning. Para testá-los, um subconjunto dos dados é normalmente separado do conjunto de treinamento para teste do desempenho do modelo. Esses dados devem ter uma sobreposição mínima de características com os dados de treinamento; por exemplo, representando um período diferente de coleta de dados ou provenientes de uma fonte diferente. Se não houver dados de alta qualidade suficientes, um determinado cenário do problema pode não ser adequado para o machine learning aplicado.
Equilíbrio entre verdadeiros positivos e falsos positivos: como mencionamos, a sensibilidade de cada modelo precisa ser calibrada para equilibrar o limite de detecção entre verdadeiros positivos e falsos positivos para maximizar a eficácia.
Explicabilidade: refere-se à capacidade de explicar como e por que um modelo tem determinado desempenho. Isso permite às equipes de ciência de dados compreender quais características em uma amostra influenciam o desempenho do modelo e seus pesos relativos. A explicabilidade é essencial para responsabilização, confiança, conformidade com políticas de dados e, em última análise, para a melhoria contínua do desempenho no machine learning.
Repetibilidade: também conhecida como reprodutividade, refere-se à capacidade de experimentos de machine learning serem reproduzidos de forma consistente. Ela gera transparência em relação ao uso do machine learning, que tipos de modelos são usados, quais dados são usados para treiná-los e em quais ambientes ou versões de software eles operam. A repetibilidade minimiza a ambiguidade e possíveis erros conforme os modelos vão passando do teste para a implementação e em ciclos futuros de atualização.
Otimização para o ambiente de destino: cada modelo deve ser otimizado para seu ambiente de produção de destino. Cada ambiente varia em disponibilidade de recursos computacionais, memória e conectividade. Portanto, cada modelo deve ser projetado para o desempenho em seu ambiente de implementação, sem sobrecarregar ou interromper as operações no host de destino.
Fortalecimento contra ataques adversários: os modelos de machine learning têm sua própria superfície de ataque que pode ser vulnerável a ataques de adversários que tentam explorar ou modificar o comportamento do modelo (como fazer com que o modelo classifique amostras incorretamente). Para minimizar a superfície de ataque explorável dos modelos, os cientistas de dados os "fortalecem" no treinamento para assegurar um desempenho robusto e resiliência contra ataques.
Dois equívocos sobre machine learning
Equívoco n.º 1: o machine learning é melhor do que métodos analíticos ou estatísticos convencionais.
Embora o machine learning possa ser uma ferramenta muito eficaz, pode não ser adequado para uso em todos os cenários de problemas. Outros métodos analíticos ou estatísticos podem produzir resultados altamente eficazes e precisos ou podem consumir menos recursos que a abordagem de machine learning, além de ser mais adequados a certos cenários.
Equívoco n.º 2: o machine learning deve ser usado para automatizar o maior número de tarefas possível
O machine learning pode consumir muitos recursos, geralmente exigindo acesso a grandes quantidades de dados, recursos computacionais e equipes de ciência de dados dedicadas para criar, treinar e manter os modelos. Para maximizar o ROI da manutenção de modelos, ele é melhor usado quando os problemas visados têm alto valor, são recorrentes, exigem velocidade e precisão e têm conjuntos de dados de alta qualidade suficientes para treinamento e teste contínuos.
A abordagem da CrowdStrike para machine learning
A CrowdStrike utiliza machine learning em toda a plataforma CrowdStrike Falcon® para oferecer proteção avançada contra ameaças.
Inteligência inigualável da CrowdStrike Security Cloud™:
Os modelos da CrowdStrike são treinados com a rica telemetria do CrowdStrike Security Cloud, que correlaciona trilhões de pontos de dados do CrowdStrike® Asset Graph, do CrowdStrike Intel Graph e do CrowdStrike Threat Graph® patenteado para oferecer visibilidade inigualável e inteligência de ameaças continuamente refinada nas superfície de ataque de uma organização.
O que enriquece esse conhecimento é um corpus cada vez maior de informações verdadeiras geradas por equipes de especialistas da CrowdStrike, incluindo as equipes de investigação de ameaças (Falcon OverWatch™), do Malware Research Center e de Detecção e Resposta Gerenciada (MDR) (Falcon Complete™).
Ampliação da expertise humana:
Os modelos da CrowdStrike alimentam a detecção e resposta autônomas a ameaças, além de ampliar a expertise humana em domínios liderados por especialistas, como investigação de ameaças e operações de TI e segurança. Os modelos de machine learning na plataforma Falcon operam para fornecer uma bancada de trabalho de analistas de última geração que automatiza a detecção e a resposta, maximiza a eficiência dos analistas com detecção de alertas gerados por machine learning de alta fidelidade e fornece recomendações inteligentes de gerenciamento de vulnerabilidades para defesa proativa (com o modelo ExPRT.AI do Falcon Spotlight™).
Várias camadas de defesa:
A CrowdStrike utiliza machine learning em toda a plataforma Falcon para oferecer uma defesa robusta e multicamadas em todo o ciclo de vida do processo (pré-execução, tempo de execução e pós-execução). Os modelos de machine learning de pré-execução, no sensor e baseados na nuvem operam de forma síncrona para detectar e responder automaticamente a ameaças, equipando o agente leve do Falcon com uma primeira linha de defesa forte. A capacidade de sincronização constante entre os modelos de machine learning na nuvem e no sensor possibilita que detecções feitas no sensor sejam aplicadas globalmente em uma superfície de ataque, além de possibilitar que as detecções feitas por modelos baseados na nuvem sejam aplicadas instantaneamente a todos os endpoints protegidos.
Para ampliar essa abordagem, a CrowdStrike também usa análise comportamental avançada no tempo de execução, utilizando modelos baseados em nuvem para analisar eventos de endpoint a fim de classificar indicadores de ataque (IOAs). Os IOAs com tecnologia IA detectam de forma proativa as ameaças emergentes independentemente do malware ou das ferramentas usadas, além de operarem de forma assíncrona para que modelos no sensor acionem análises locais de comportamentos suspeitos com base em inteligência de ameaças do mundo real.
Os indicadores comportamentais pós-execução são usados para avaliar atividades anômalas na superfície de ataque de uma organização (conforme indicado pela métrica CrowdStrike CrowdScore™, que fornece uma indicação em tempo real do nível de ameaça de uma organização), e também são usados pelo Falcon OverWatch para investigar ameaças avançadas, como atividades com acesso interativo, e-crimes e ataques sigilosos.
Saiba mais
Saiba como a CrowdStrike combina o poder da nuvem com tecnologias de ponta, como TensorFlow e Rust, para acelerar o treinamento de modelos em centenas de vezes.
Lucia Stanham é Gerente Sênior de Marketing de Produtos na CrowdStrike com foco em proteção de endpoint (EDR/XDR) e IA em cibersegurança. Trabalha na CrowdStrike desde junho de 2022.
