![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)


?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)










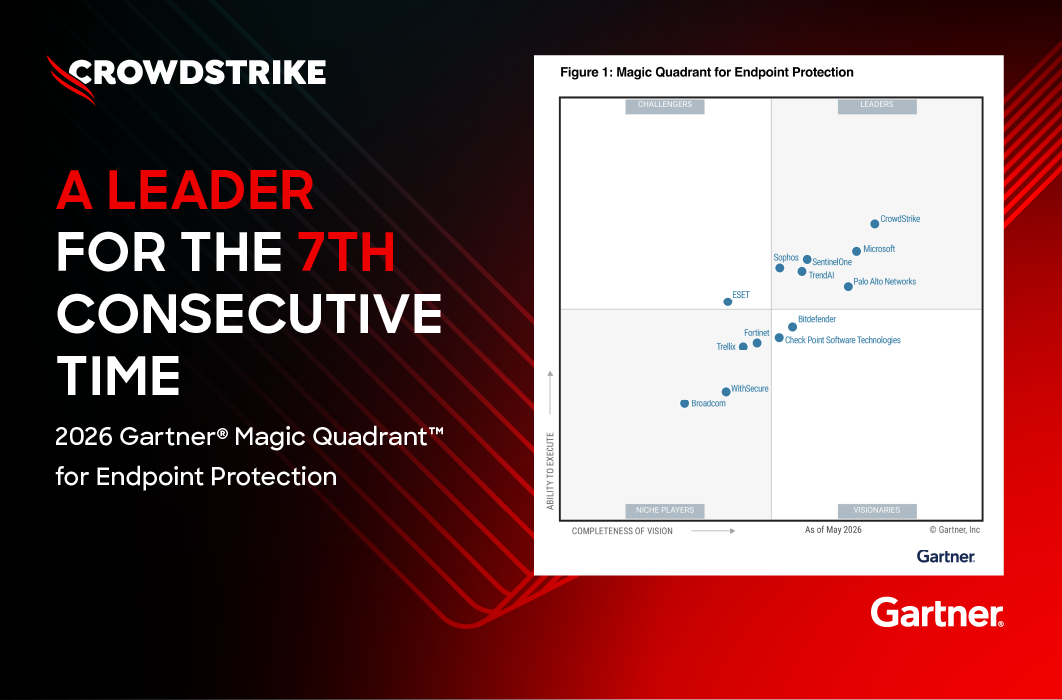





























- CrowdStrike research shows that contrastive learning improves supervised machine learning results for PE (Portable Executable) malware
- Applying self-supervised learning to PE files enhances the effectiveness of machine learning in cybersecurity, which is crucial to address the evolving threat landscape
- CrowdStrike researchers engineered a novel loss function to optimize contrastive learning performance on imbalanced datasets
The process of crafting new malware detection features is usually time-consuming and requires extensive domain knowledge outside the expertise of many machine learning practitioners. These factors make it especially difficult to keep up with a constantly evolving threat landscape. To mitigate these challenges, the CrowdStrike Data Science team explored the use of deep learning to automatically generate features for novel malware families.
Expanding on previous CrowdStrike efforts involving the use of a triplet loss to create separable embeddings, this blog explores how you can use contrastive learning techniques to improve upon this separable embedding space.
Furthermore, we will discuss a novel hybrid loss function that is capable of generating separable embeddings — even when the data is highly imbalanced.
What Is Contrastive Learning?
Contrastive learning techniques have had many successes as a self-supervised learning algorithm in the natural language processing and computer vision domains.
The goal of these techniques is to contrast different samples, such that similar ones are closer together and dissimilar ones are farther apart from one another — similar to how we as humans differentiate objects by comparing and contrasting them.
Over time, as we develop, we can differentiate things based on features we identify. For example, we can tell the difference between a bird and a cat based on features such as a bird having wings and a cat having pointy ears and a tail.
We can train a deep learning model to automatically capture these features by applying a contrastive loss function. This is generally done using a Siamese network, where two identical networks are fed different data. The networks are then trained with a loss function used to measure the similarity between the two inputs.
Below, we detail examples of contrastive learning techniques.
SimCLR
The Simple Contrastive Learning (SimCLR) framework is an algorithm developed by researchers at Google Research (formerly Google Brain). It works by applying augmented versions of the same image through a deep neural network, where the goal is to maximize agreement between these images. The framework is depicted in the image below (Figure 1).