





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































- Machine learning models trained on both human expertise and machine intelligence are essential to synthesizing today’s volume of intelligence and maximizing model efficacy
- CrowdStrike’s machine learning cycle involves human expertise at each stage of development to optimize performance and minimize false positives>
- Register for our upcoming CrowdCast series to learn how CrowdStrike’s data science team builds world-class machine learning models
The Art of Balancing Performance with Efficacy
Security is a data problem. One of the most touted benefits of artificial intelligence (AI) and machine learning (ML) is the speed at which they can analyze potentially millions of events and derive patterns out of terabytes of files. Computational technology has progressed to the point where computers can process data millions of times faster than a human could.
For example, CrowdStrike’s cloud-based ML model automation can predict 500,000 feature vectors per second while processing 10TB of files per second to find detections. With organizations today generating more quantities of data than ever, it is virtually impossible for human analysts to process it all without first having automation tools do the heavy lifting. Without ML, it’s likely that potentially interesting or even critical data would go untapped.
The industry-leading CrowdStrike Falcon® platform sets the new standard in cybersecurity. Watch this demo to see the Falcon platform in action. Though processing speed is essential, models must also be highly accurate in their detections. They must maximize true positive detections while keeping false positives to a minimum to prevent alert fatigue and eroding the analyst experience. The tradeoff between total detections and false positives is referred to as a model’s “detection efficacy,” a measure that separates good models from great models. Left alone, machines excel at detecting anomalies and uncovering patterns in data, but to detect the most sophisticated attacks — those that aim to evade detection by appearing as benign, legitimate or innocuous — human expertise is needed to refine, correct and train models.
From security analysts to threat hunters to data scientists, skilled humans provide an inimitable ground truth and security context with their decades of experience, forged intuition and institutional knowledge. Underscoring this is the necessity of an approach that combines both human and machine elements: Organizations that don’t adopt AI or ML can’t keep up with the changing threat landscape. However, models developed without proper security context end up scanning for anomalies, driving up false positives and missing advanced adversary patterns.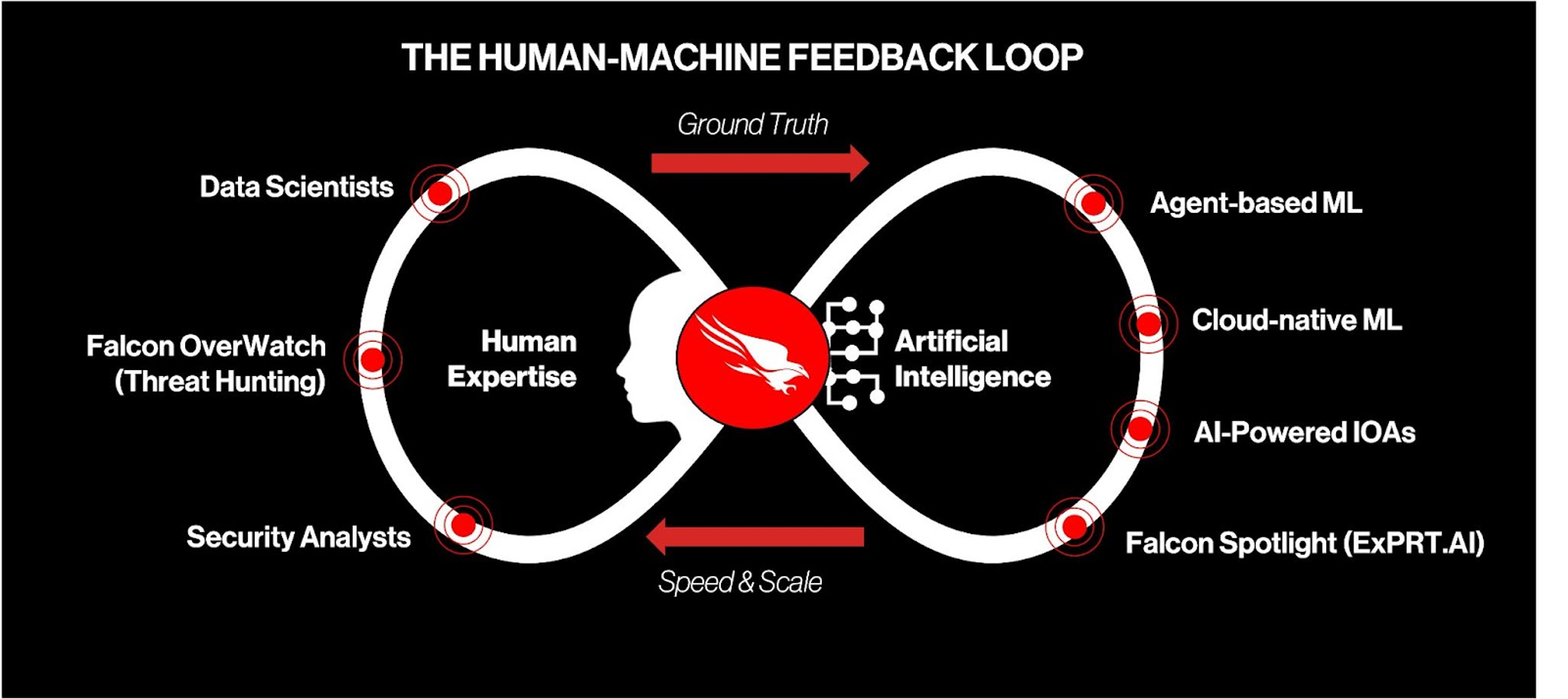
How to Maximize Machine Learning Model Efficacy
CrowdStrike data scientists and researchers are involved in every stage of building, training and retraining models to ensure they have the highest efficacy rates possible. Models are frequently retrained to prevent natural drift and capture analyst-generated detections to ensure models are up-to-date. The machine learning cycle is composed of six critical phases to ensure the best possible outcomes in model performance and efficacy.
Phase 1: Data Collection and Labeling
Data collection and labeling is the first and potentially most important aspect of building the training corpus. In ML, the model is a representation of the input data, and if the training corpus data is of poor quality (e.g., mislabelled, misrepresented, biased, highly imbalanced, etc.), the model outputs will be useless (“garbage in, garbage out”).High-quality labeled data is time-consuming and expensive to obtain, but ultimately necessary for training efficient ML models. There are several key requirements for success:
- Understanding the problem you want to solve
- Collecting qualitative and quantitative data
- Making certain the data represents the problem at hand (i.e., consistent, uniform and “fresh”)
These steps are all part of the principles and processes for building a training data set. The use of data versioning tools can also be part of this workflow, especially in reproducing, tracing and having a clear ML model lineage. At CrowdStrike, multiple data sources generate trillions of data points daily. Whether it’s data coming from customers, data from the CrowdStrike Falcon Sandbox™, data ingested into CrowdStrike Falcon LogScale from across the enterprise, or intelligence from research teams and industry partners, all data goes through automated data labeling processes that annotate files with metadata based on knowledge stemming from multiple systems, including the CrowdStrike Intel Graph.
A continuous corpus cleanup process then automatically checks for label dissonance, and includes expert human review to ensure no mislabeled files remain in the training corpus. This ensures data labeling accuracy is as close to 100% correct as possible.
Phase 2: Feature Engineering
Feature engineering is one of the most important steps in data science and ML as it speaks directly to the high value of the insights inferred by ML models. Feature engineering and selection uses data to create new variables to simplify and accelerate data transformations to boost model accuracy.
However, feature engineering is time-consuming and requires expert knowledge to identify and select the right features. Before creating new features, data scientists must understand the business problem they’re trying to solve. For example, building cybersecurity-centric ML models for detecting new and unknown malware or malicious behavior involves understanding what features are relevant for both clean and malicious files. That feature set, and the results achieved by those features, are then used to build powerful classification and detection models.
Phase 3: Model Training
Model training is the phase when the ML model is built to achieve the best representation of the relationship between data features — extracted from the corpus in Phase 2 — and target label. In cybersecurity applications (depending on the use case) those target labels might include “malicious,” “benign,” “dirty,” “clean” or “suspicious,” among others. Data scientists typically assess a model’s performance — e.g., how well the algorithm “learned” the data — against a validation data set containing labeled data that was not part of the training set by using a loss function, which evaluates the difference between the model’s current output and its expected or desired output. There are multiple loss functions data scientists can use during this process, but in any case if a model’s output deviates significantly from the expected result the model will need to be retrained. Some of the necessary processes in each of the phases described above are traditionally human-driven, which can make everything up to the model deployment phase very time-consuming. To alleviate this, CrowdStrike uses an end-to-end model automation pipeline that reduces model training to one day and the manual effort data scientists need to evaluate the model to one hour. This advanced approach enables agile model training, which supports a faster update cycle.
Phase 4: Model Deployment
Model deployment is when the finished ML model is placed into a live environment, making it available to other systems. When designing models, CrowdStrike’s data science team must take into account constraints unique to each environment, including on-sensor environments, cloud environments and hybrid environments that combine on-sensor and cloud. On-sensor models are built to factor in minimum resource consumption, millisecond response time and optimized inferencing speed and scan times. In the cloud, models have no such performance constraints and deliver protection via synchronous connection between sensor and cloud. In addition, cloud models benefit from data coming in from all protected endpoints, helping ML models make better inferences and predictions based on real-world data. In tandem, the use of on-sensor and in-the-cloud ML models presents numerous benefits. For example, if a file is not detected by the on-sensor model, a feature vector for that file is submitted to the cloud for an assessment; if the cloud-based model believes the file is malicious, it then sends instructions to the sensor to quarantine or block the process initiated by the file.
Phase 5: Expert Analysis and Review
Expert analysis and review involves measuring the performance and efficacy of the model in a production environment to identify and assess potential gaps that could be addressed in an upcoming iteration. Data scientists, researchers and analysts work together to map any potential false positives and queue that data to be used in a new training corpus.
Phase 6: Ongoing Learning and Retraining
As long as the model remains in production, data scientists monitor and tune performance through ongoing learning and retraining cycles, ensuring the corpus of training data contains the latest threat samples and models can accurately detect new and unknown threats. They also incorporate feedback from our customers as it is highly valuable when improving the performance of our models. As part of this process, we also use ML to generate adversarial samples using features derived from known threats. Retraining models with adversarial samples generated using a wide range of malicious file modifiers can improve model robustness and its ability to detect adversarial attacks.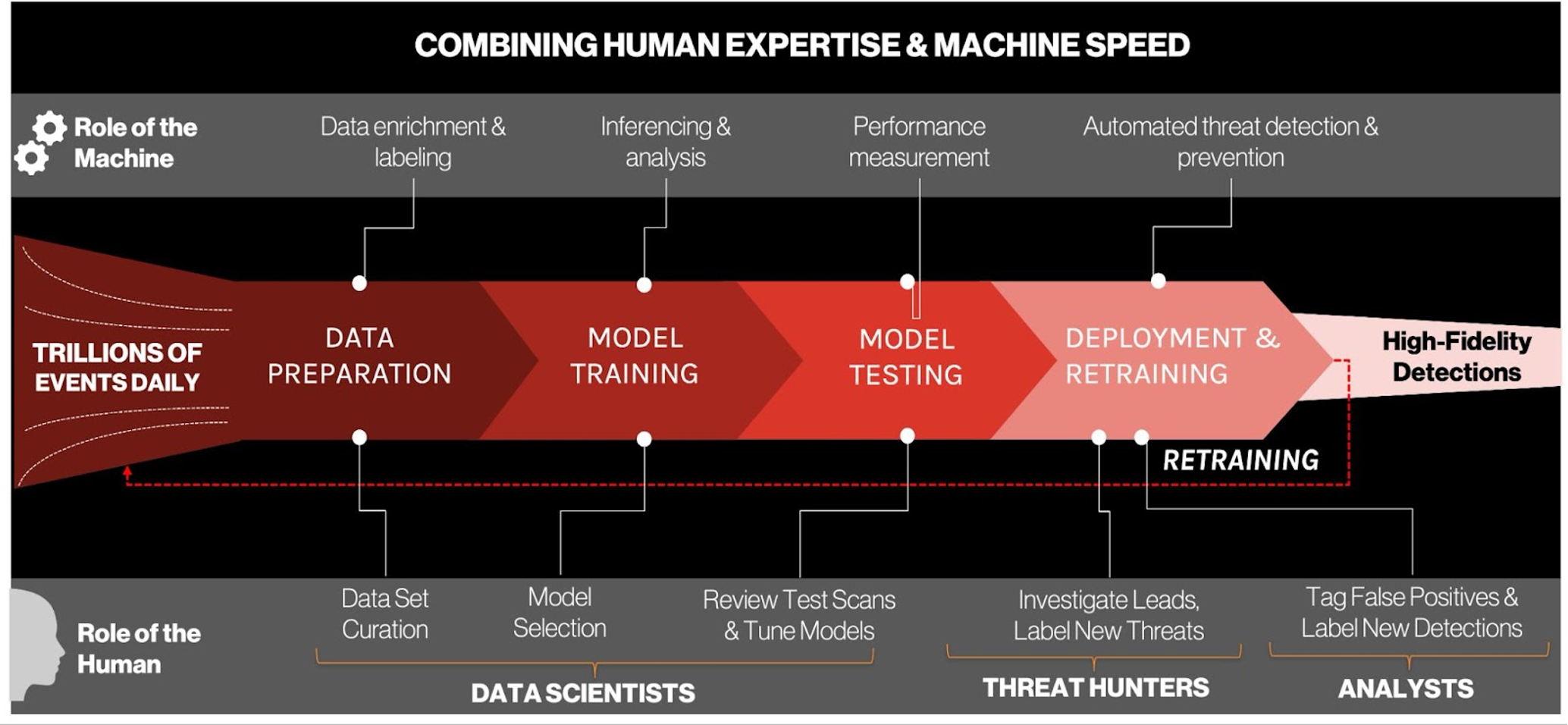
Winning the Race Against Threats
With more than 180 tracked adversaries and a 45% increase in interactive intrusions, as reported in the CrowdStrike 2022 Global Threat Report, staying ahead of threats is not a human-scale problem but one that demands the potent combination of machine learning and human expertise. We’ve also put our resulting model efficacy to the test: CrowdStrike has a rigorous testing record of participating in independent third-party evaluations from leading organizations, such as AV-Comparatives, SE Labs and MITRE, earning the achievement for the most tested next-gen endpoint protection platform. CrowdStrike’s approach to building world-class machine learning is rooted in performance, efficacy and transparency. These values are central to building data-driven solutions that deliver unparalleled protection against the most sophisticated adversaries.
See for yourself how the industry-leading CrowdStrike Falcon platform protects against modern threats like wipers and ransomware. Start your 15-day free trial today. To learn more about our approach to machine learning, we encourage you to register today for our upcoming two-part CrowdCast series, hosted by Joel Spurlock, senior director of data science at CrowdStrike. The series will air on November 3, 11 a.m. PT.
In this series, we’ll dive into:
- CrowdStrike’s approach to building world-class ML models
- How CrowdStrike uses ML across the CrowdStrike Falcon platform
- How behavioral ML and AI-powered indicators of attack help organizations stay ahead of adversaries
Additional Resources
- Register for live CrowdCasts and view on-demand CrowdCasts in the Resource Center.
- Read about how machine learning is used in cybersecurity.
- Download the white paper The Rise of Machine Learning in Cybersecurity.
- Learn more about the CrowdStrike Falcon® platform by visiting the product webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.