In previous posts in this series, we introduced basic and advanced concepts related to Linux logging. Then, in Part Three, we focused on best practices when dealing with Linux logging. One of the best practices we touched upon is a centralized logging solution. A centralized log management system helps us to overcome the difficulty of processing and analyzing logs from a complex, distributed system of dozens (or even hundreds) of Linux hosts.
In this post, we’ll look at how to use Falcon LogScale Collector on our Linux systems in order to ship system logs to CrowdStrike Falcon LogScale. With a simple and unified logging layer, we can make queries across logs from multiple Linux hosts, handle multiple log formats and more.
Learn More
Explore the complete Linux Logging Guide series:
- Part 1: The Basics
- Part 2: Advanced Concepts
- Part 3: Best Practices
- Part 4: Centralized Logging
Set up the Collector for Linux
To begin, download and install Falcon LogScale Collector on your Linux hosts. The collector relies on ingest tokens — unique strings used for authentication — to send logs to the correct repositories. Generating an ingest token for your Falcon LogScale repository is straightforward.
Falcon LogScale Collector is configured through a YAML file and additional environment variables. Below is an example of a minimal configuration file that collects Linux kernel logs and sends them to Falcon LogScale.
dataDirectory: data<p>sources:</p>
<p>kernal_logs:</p>
<p>type: file</p>
<p>include: /var/log/kern.log</p>
<p>sink: my_humio_instance</p>
<p>sinks:</p>
<p>my_humio_instance:</p>
<p>type: humio</p>
<p>token: <ingest-token></p>
<p>url: https://cloud.community.humio.com</p>
dataDirectory: data<p>sources:</p>
<p>kernal_logs:</p>
<p>type: file</p>
<p>include: /var/log/kern.log</p>
<p>sink: my_humio_instance</p>
<p>sinks:</p>
<p>my_humio_instance:</p>
<p>type: humio</p>
<p>token: <ingest-token></p>
<p>url: https://cloud.community.humio.com</p>
dataDirectory: datasources:
kernal_logs:
type: file
include: /var/log/kern.log
sink: my_humio_instance
sinks:
my_humio_instance:
type: humio
token: <ingest-token>
url: https://cloud.community.humio.com
In the above example, you would make sure to replace
<ingest-token>
<ingest-token> with the ingest token generated for your repository. Also, the url
url you should use depends on your type of Falcon LogScale account. Reference the endpoints documentation to determine what you should use for url
url.
For more detailed information, check out how to configure Falcon LogScale Collector.
Processing
Logs sent to Falcon LogScale need to be processed before storing them. Parsers can process structured data (such as JSON) or unstructured data (such as application
stdout
stdout). Falcon LogScale has several built-in parsers available, or you can even create your own parser.
Indexing
Although most centralized solutions rely on indexing as an effective solution to maintain data and make querying efficient, Falcon LogScale offers an innovative solution and provides an index-free platform. Despite being index-free, Falcon LogScale demonstrates its ability to scale immensely while maintaining blazing-fast query speeds.
Querying
With your Linux logs available at a central location, you’re ready to dive into the data and make queries. Perform a query by searching the raw logs or selecting data from specific fields. For example, the following query gives the top three common HTTP methods with the exception of
PATCH
PATCH) with a status equal to or greater than 400
400:
status >=400<p>| method != PATCH</p>
<p>| top(method, limit=3)</p>
status >=400<p>| method != PATCH</p>
<p>| top(method, limit=3)</p>
status >=400| method != PATCH
| top(method, limit=3)
For more details, read about how to build queries in the official documentation, which also provides information on query best practices and example queries.
Based on query results in Falcon LogScale, you can build dashboards composed of widgets.
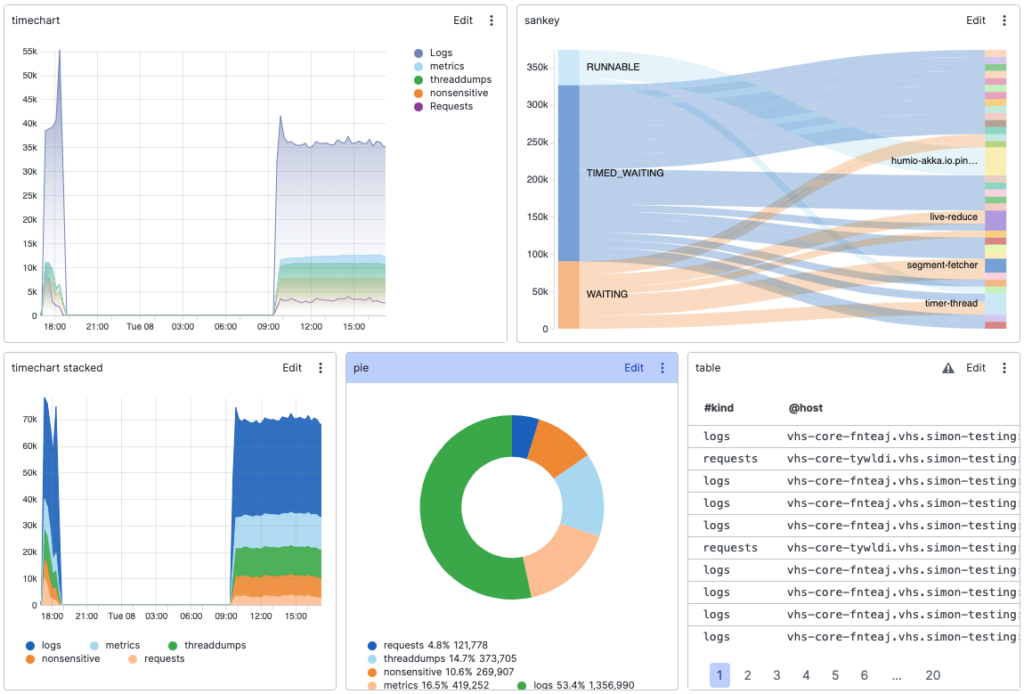
You can also configure each dashboard with several widgets, including raw or filtered data, which can be used to drill down to more specific data. For more details, read about how to create and maintain dashboards.
Log your data with CrowdStrike Falcon Next-Gen SIEM
Elevate your cybersecurity with the CrowdStrike Falcon® platform, the premier AI-native platform for SIEM and log management. Experience security logging at a petabyte scale, choosing between cloud-native or self-hosted deployment options. Log your data with a powerful, index-free architecture, without bottlenecks, allowing threat hunting with over 1 PB of data ingestion per day. Ensure real-time search capabilities to outpace adversaries, achieving sub-second latency for complex queries. Benefit from 360-degree visibility, consolidating data to break down silos and enabling security, IT, and DevOps teams to hunt threats, monitor performance, and ensure compliance seamlessly across 3 billion events in less than 1 second.
Arfan Sharif is a product marketing lead for the Observability portfolio at CrowdStrike. He has over 15 years experience driving Log Management, ITOps, Observability, Security and CX solutions for companies such as Splunk, Genesys and Quest Software. Arfan graduated in Computer Science at Bucks and Chilterns University and has a career spanning across Product Marketing and Sales Engineering.
