





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



?wid=2048&hei=1350&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)







































Working with text data (which we often refer to as “strings”) is common in cybersecurity applications. For example, suppose we have a set of command lines associated with malicious activity, and we want to block similar activity in the future. Often, we create a machine learning (ML) model that incorporates these command lines and is trained to differentiate between malicious and benign activity. However, for a variety of reasons, deploying a complex ML model may be unwarranted — malicious command lines may follow a simple pattern that can be easily detected by a simpler model, the overhead for developing a large model may be too costly, or a simpler model may allow for faster deployment of new detection capabilities.
With text data, one of the simplest models available is substring-based pattern matching (i.e., does this text contain a specific string of characters?). In this post, we'll talk about how to build a model that automatically learns and generates substring patterns that identify malicious activity.
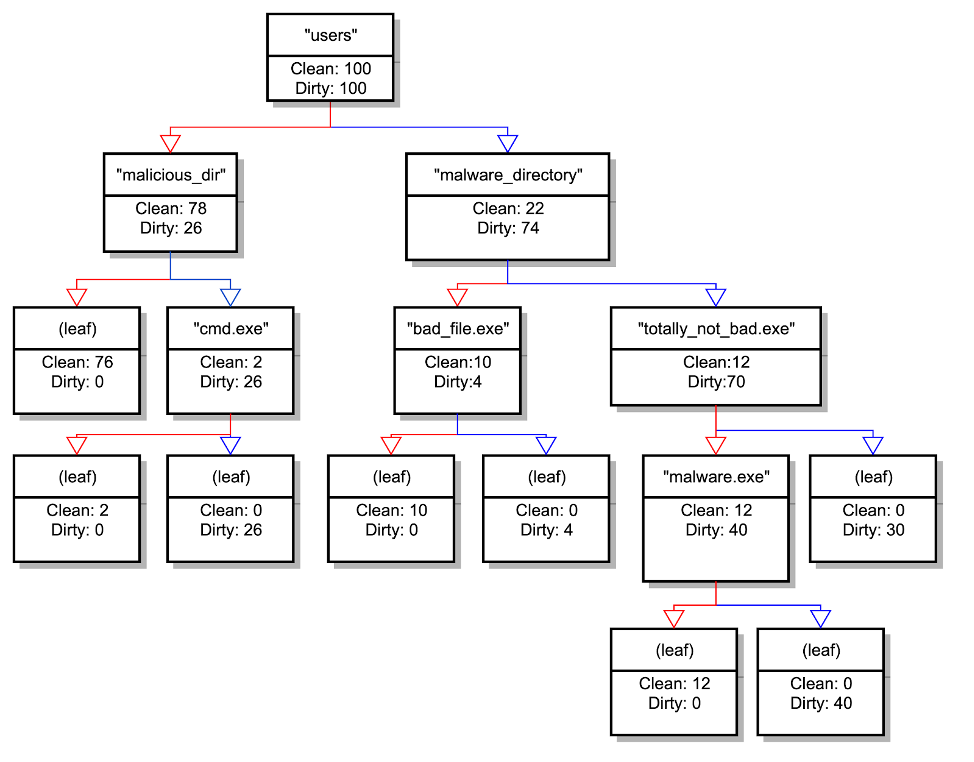 Figure 1. Toy example showing a decision tree learned from string data
We don’t need to construct the whole tree to get only the right-hand side, of course. We can choose the feature that best splits the data and is positively correlated with the label (if we want to match on the positively labeled data). Then, from the data that has matched on that feature, we find the next feature that best splits the data and is positively correlated with the label, and so on, until we don’t have any negatively labeled data remaining or we can’t split the data further, whichever comes first.
This algorithm is pretty simple and works quite well, but it has a downside: It’s greedy. We find the next feature that is “best” by some measure at each step, but it might not be the feature that will lead to the best overall result.
Figure 1. Toy example showing a decision tree learned from string data
We don’t need to construct the whole tree to get only the right-hand side, of course. We can choose the feature that best splits the data and is positively correlated with the label (if we want to match on the positively labeled data). Then, from the data that has matched on that feature, we find the next feature that best splits the data and is positively correlated with the label, and so on, until we don’t have any negatively labeled data remaining or we can’t split the data further, whichever comes first.
This algorithm is pretty simple and works quite well, but it has a downside: It’s greedy. We find the next feature that is “best” by some measure at each step, but it might not be the feature that will lead to the best overall result.
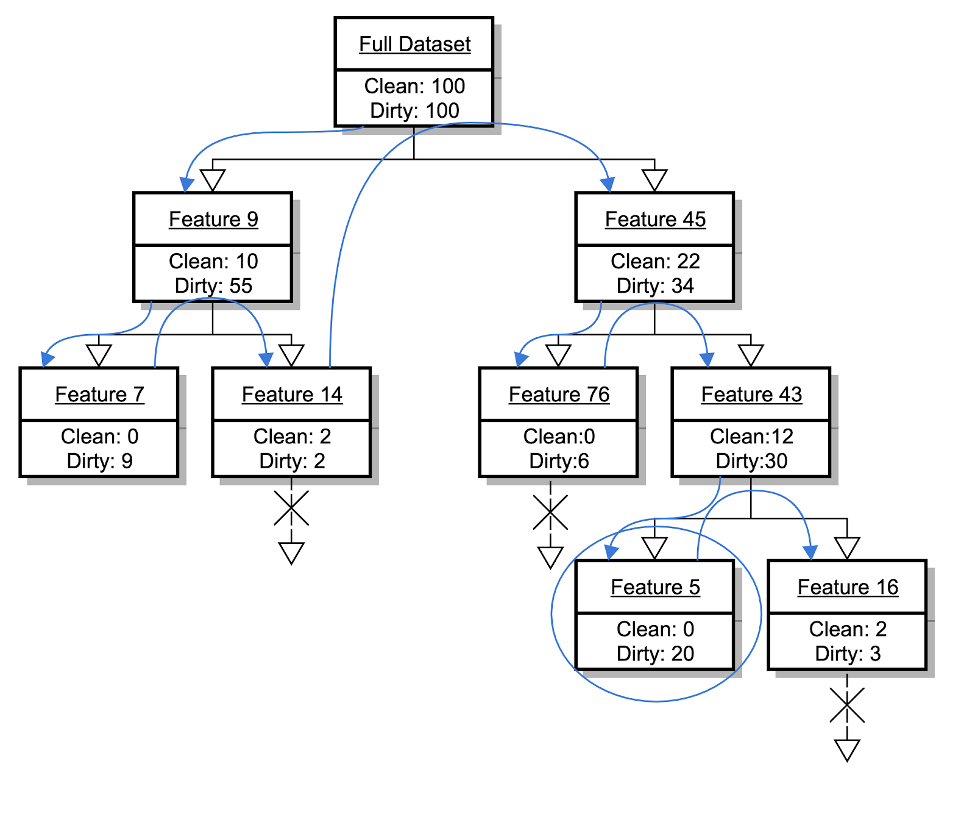 Figure 2. Example of a search tree that uses a depth-first search of the top two features to create expressions
Figure 2. Example of a search tree that uses a depth-first search of the top two features to create expressions
Problem Setup
Given that our data consists of sets of strings with associated labels (e.g., malicious vs. benign, or dirty vs. clean), our goal is to find substring-based patterns that match as much of the data with one label as possible, while minimizing the amount of data matched with the other label. We want to identify patterns that are present in as many malicious command lines as possible, while not being present in any of the benign command lines. There are many possible ways of constructing such substring matches, and things can get very complex very quickly, so we make a couple of simplifications to the problem and add one constraint to harden the model against evasion:- We extract tokens (substrings that we extract from the full strings by some process) rather than working at the character level. Therefore, our text data can be thought of as sequences of (possibly overlapping) tokens.
- We construct expressions for our matches that are of the
form token_4 AND token_7 AND token_11... - We only care about the presence or absence of a token, not how many times it appears in a string.
- Negations like
NOT token_3are not allowed. This is to enforce monotonicity: Adding a substring can't make a string less likely to be matched on, only more likely.
A Non-Negative Decision Path
Since we now have labeled data and sets of features (corresponding to inclusion or exclusion of our tokens), we could try using a classifier like a decision tree and extracting paths from it to use as expressions. The issue with employing a decision tree in this way is that it requires the ability to split our features in either direction, which could result in leaf nodes defined by the exclusion of certain tokens. If we were to translate these leaf nodes into patterns, this exclusion would require the negation of a string match, which we have explicitly ruled out. However, if we think about how a decision tree is constructed, we see that the path down the right-hand side of the decision tree (assuming the right side means a binary feature is positive) is exactly what we want for a single matching expression. As a toy example, if we have some file paths for some malicious and non-malicious files, we could imagine learning a tree like the one below (Figure 1). The blue arrows are followed if the input string matches the pattern in that node. In this case, we can see that if we follow all of the blue arrows from the root, we would create the pattern"users" AND "malware_directory" AND "totally_not_bad.exe" from the right-hand side of the tree, but we wouldn't be able to use the information in the rest of the tree because we have constrained ourselves to not use negation.
Figure 1. Toy example showing a decision tree learned from string dataA Slightly Less Greedy Non-Negative Decision Path
Instead of choosing the next feature based on how that feature splits the current data, we can look ahead by training a decision tree or decision forest at each step, and choosing the feature that has the highest importance (by some measure) in that tree or forest that is also positively correlated with the label (because we don’t want to use negation). Because the most important feature in the tree or forest constructed at each step won’t necessarily be the feature at the root of the tree (or trees), this can differ from the greedy approach and often gives us slightly better string-matching expressions.Searching
If we want to find the absolute best expression possible, we would need to try all of the features (token matches) to find the first feature to split on, and then the remainder of the features to find the next one, and so on. But this would be a very broad and deep tree of possibilities to search through. We can approximate this exhaustive search by searching only in promising directions. One algorithm for this is called “beam search.” The idea of a beam search is to only continue searching from a few (e.g., 10) places in the full tree of possibilities. This approach requires a good heuristic for how promising a particular path is likely to be, and in our case, we may not know how promising a path (set of token matches) is until we have finished (matched on only strings with our desired label). To know for sure how promising our paths in our search space are without checking too many paths, we can do a depth-first search that only checks the top n features at each decision node. This gives us an algorithm that isn’t greedy, can be executed in a reasonable amount of time, and puts a decent amount of effort toward covering as many strings as possible with each matching expression. In the diagram below, a depth-first search is shown for a dataset with 100 clean and 100 dirty instances, and we’ve checked the top two features at each decision node. The blue lines show the traversal of the tree: We’ve checked the best feature first, then its best child, and so on, stopping traversal if a node is purely dirty or if we’ve already found a purely dirty node with more dirty samples than exist in the current node. In this example, the expression created would befeature_45 AND feature_43 AND feature_5.
Figure 2. Example of a search tree that uses a depth-first search of the top two features to create expressionsConclusion
We've presented a few methods to automatically learn string patterns that can be used to classify text data. These methods can be useful in a variety of settings (including cybersecurity) and are lightweight, simple and easily deployed. Are you an expert in designing large-scale distributed systems? The CrowdStrike Engineering team wants to hear from you! Check out the openings on our career page.Additional Resources
- Learn more about the CrowdStrike Falcon® platform by visiting the product webpage.
- Learn more about CrowdStrike endpoint detection and response by visiting the Falcon InsightTM webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.

