Understand CNAPPs with Our Guide
Learn the key benefits and integration tips for Cloud-Native Application Protection Platforms. Enhance your cloud security strategy.
Download the Guide Now
Understand CNAPPs with Our Guide
Learn the key benefits and integration tips for Cloud-Native Application Protection Platforms. Enhance your cloud security strategy.
Download the Guide Now
How to Avoid the Top 11 AWS Misconfigurations
When setting up a new AWS cloud infrastructure, or when modifying any setting to either give permissions or take them away, there are always considerations to be made regarding security.
The AWS Shared Responsibility Model emphasizes that you are responsible for security “in” the cloud, while AWS is responsible for security “of” the cloud. In simple terms, this means that you are liable for changes you make that result in publicly exposing any of your data.
In this article, we’ll explore the most common sets of misconfigurations across the most common services, and advise on how to stay safe and prevent potential breaches when modifying your infrastructure.
Top 4 S3 Misconfigurations
1. Public Buckets or Public Objects Inside Buckets
Whenever you need to use S3 for website storage or as a static site hosting option, you’ll probably need to make some of it, if not all, public. This is an easy process, but if done incorrectly, it can potentially put all of your data at risk of a breach. As we know, such breaches have had extensive consequences over the last few years. If you’re creating a new bucket and you want to make it public, there are a few options to choose from.
As seen in the screenshot below, you can opt to allow public access to buckets and objects, either through new ACLs, any ACLs, new access point policies, or any access point policies:
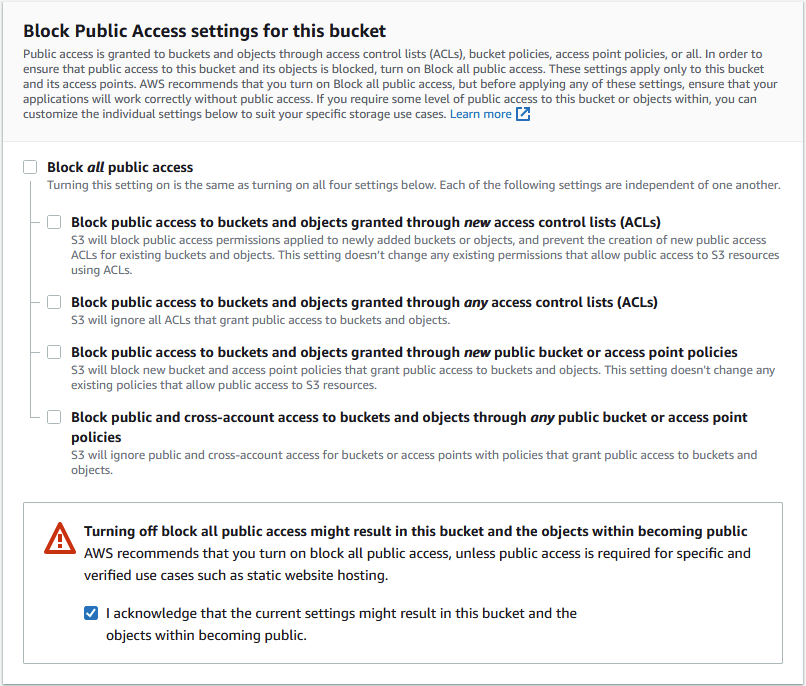
You should be careful to choose the most appropriate solution for your application. Also, be careful with what you add to your bucket, as it will remain public until you change it, potentially exposing sensitive data.
2. Not Using Access Logging
S3 access logging is an easy setting to turn on. If you browse to a bucket’s Properties tab, you’ll see it there:
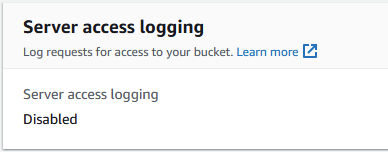
It’s disabled by default, but you can turn it on by clicking the Edit button and assigning a target bucket for the logs to be stored.
What this setting does is log each request for access to your bucket. Even better, these logs don’t cost extra to use, so they can be really useful in certain situations and even help explain an S3 bill to a client. Still, keep in mind that you’ll still be billed for storing those logs in the target bucket, with S3 pricing applied as usual. Since these logs can accumulate quickly, you might want to set up a delete mechanism for them.
It’s also worth noting that your target bucket shouldn’t have access logging enabled, or you’ll cause an infinite loop and might end up with a high bill to pay.
3. Not Using Versioning + S3 Lifecycle
When you enable bucket versioning, you can store multiple instances of an object inside the same bucket. The most useful aspect of this feature is that it enables you to recover from an application malfunction or any unintended user action.
You can enable it through the S3 console by navigating to the Properties tab:
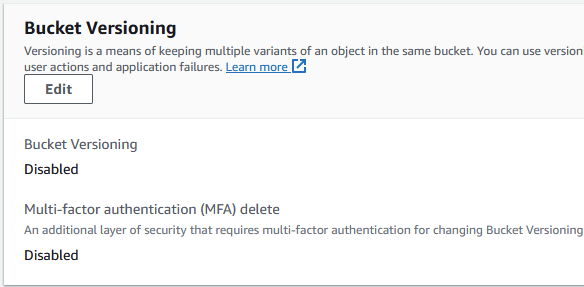
It’s easy to activate, and you should also accompany it with multi-factor authentication (MFA) delete to prevent the unintended deletion of previous instances of objects.
The downside of this feature is that for every version of an object, it stores the entire object, not just the difference between that object and other versions of itself. This can be mitigated by using S3 lifecycle configuration rules. This way, you can set non-current objects to delete themselves after a set period of time; or you can transition them to more affordable storage services, like S3 Glacier Flexible Retrieval, and delete them when they’re replaced by their more recent version.
4. Not Encrypting Critical Information
If you’re storing sensitive data, you should always be encrypting it. You can do this server-side through S3 itself, or you can do it client-side by yourself. If you choose to do it server-side, it’s much easier, as Amazon handles the encryption, storage, and decryption when downloading or copying an object. You can turn this on in the Properties tab by clicking the Edit button under the Default encryption section:
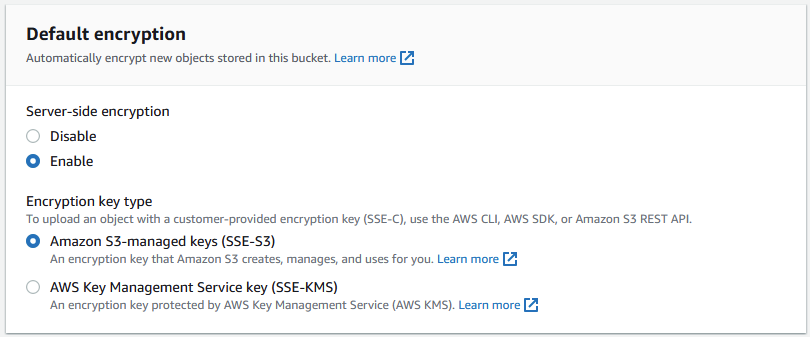
This will let you choose which keys you want to use for the encryption. SSE-S3 keys are managed by S3, and you don’t have to do anything. SSE-KMS keys are managed through KMS and require a bit more setup.
If your data is extremely sensitive, you might want to consider encrypting it yourself before storing it. This is possible, but a bit dangerous since if you lose your keys, you won’t be able to retrieve or decrypt your objects. This process is also extensive and requires setup, so you should head over to the AWS documentation on how to do this.
Learn More
Read this article to learn more about the importance of data encryption as well as its benefits and challenges.
Top 3 EC2 Misconfigurations
1. Public Snapshots, or Non-encrypted Shared Snapshots
The snapshots you make from your instances are private by default, but there are two scenarios where this might change.
The first one is where anyone with enough permissions (even a service such as AWS Lambda) changes it to public, making a previous state of all your data publicly available, which can be disastrous. The second scenario would happen if you needed to share an unencrypted snapshot. In this case, the recipient of the snapshot could create volumes from it, thus pretty much booting an instance with all of your data in it.
Either way, you should encrypt your snapshots, which means encrypting your instances at creation or creating an encrypted snapshot and then a new root volume from that snapshot.
2. Backend instances living in public subnets
If you have any instances that don’t require internet connectivity, such as databases or simple APIs, you should keep them inside private subnets. Being connected to the internet is a constant threat that could trigger at any time since you never know who has access to your instance’s IP.
The way to make an instance live in a private subnet is simply to remove auto-assigning from the IPv4 and IPv6 addresses. You can do this by going to the Subnet tab in the VPC console, choosing your instance’s subnet, and toggling this setting to off:
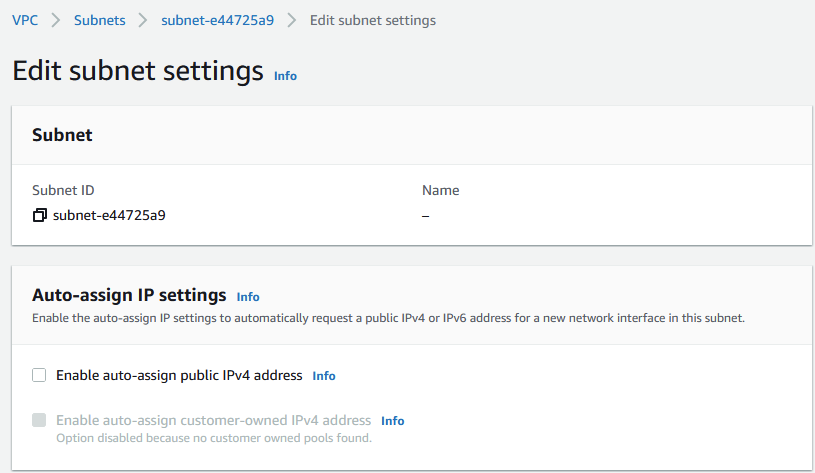
3. Public/unencrypted AMIs
If you need to create an AMI, you also might have to share it with another account. In that case, you should be careful and take a few measures to prevent any security breaches.
First, you should encrypt your volumes, so any AMI that might include a volume is encrypted by default and doesn’t reveal any data. Second, you should be careful when giving out permissions to EC2 because that might include setting the AMI’s availability to public; this might be a problem if you have a malicious actor inside your company, or if any services such as AWS Lambda are compromised.
Finally, you should always share your AMIs through the console to avoid any potential mishaps that might expose them to the world:
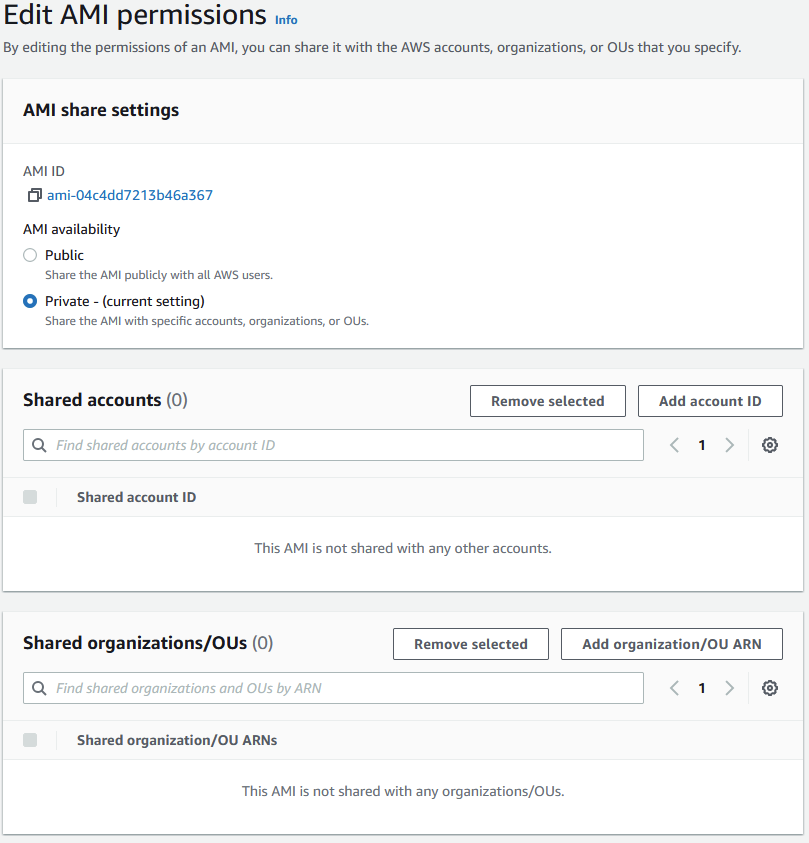
Top 4 IAM misconfigurations
1. Lack of MFA/Key rotation
MultiFactor Authentication (MFA) is crucial and should be required for any entity that is added to identity and access management (IAM), especially users. This way, you can mitigate stolen keys and eliminate a big attack surface. To make it required, you have to navigate to the Security Credentials tab of the user you want to enable it for, and select it there:
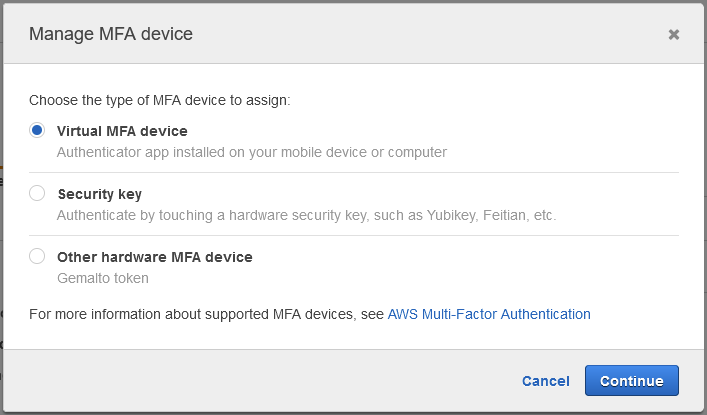
You should also enforce access-key rotation account-wide. While AWS doesn’t have an automatic way of doing this, and suggests doing it manually, there are open-source tools that can automate and simplify the process for you. This only applies to IAM users and not roles, since roles already have automatic key expiration after a set amount of time.
2. Not using roles
Through Identity Access Management (IAM), you can choose to give permissions to users by directly attaching policies to them. But doing so is a bad practice in large and critical infrastructure since you might be giving the wrong permissions to the wrong people; also, if you forget to remove those permissions, they stay there forever.
By using roles as the preferred method of granting permissions, you get automatic key expiration, which is a much more manageable way to deal with excessive permissions or stolen keys. You can also choose to use groups if you have many users that share common privileges, but try not to attach policies directly to users.
3. Giving out too much privilege
When handing out permissions, you should do so according to the Principle of Least Privilege. If one user or role needs access to a service, you should gather the specific actions they must take in order to do their job, and assign those privileges to the IAM entity—instead of taking the easy path and just granting access to the service as a whole. As we’ve covered, there are many simple but very powerful sets of permissions that, when granted, can have disastrous consequences.
4. Keeping unused credentials around
You should always keep track of your keys and active users and roles throughout your infrastructure. If any user becomes inactive for whatever reason (e.g., vacation, layoff, etc.), you might want to consider deactivating those keys for the duration needed and deleting them after some time has passed.
This way, you won’t have any set of keys lying around that still have permissions attached and present a hole in your environment. It’s always preferable to have to recreate a user rather than be exposed to potential internal attacks.

The Complete Guide to CNAPPs
Download CrowdStrike's Complete Guide to CNAPPs to understand why Cloud-Native Application Protection Platforms are a critical component of modern cloud security strategies and how to best integrate them to development lifecycles.
Download NowSummary
There are many ways in which modifying your infrastructure can go wrong, and if you’re not careful, you can end up compromising your data. However, these can be mitigated by making changes to avoid the above misconfigurations gradually and consciously.
Alternatively, you can lean on CrowdStrike to provide you with the security you need. We’ve been commended by AWS for achieving the Threat Detection and Remediation distinction. CrowdStrike Falcon® for AWS can help you analyze and mitigate all the issues listed here, and many more.
Guilherme (Gui) Alvarenga, is a Sr. Product Marketing Manager for the Cloud Security portfolio at CrowdStrike. He has over 15 years experience driving Cloud, SaaS, Network and ML solutions for companies such as Check Point, NEC and Cisco Systems. He graduated in Advertising and Marketing at the Universidade Paulista in Brazil, and pursued his MBA at San Jose State University. He studied Applied Computing at Stanford University, and specialized in Cloud Security and Threat Hunting.


